So you want to send a Multimedia Message (Aka MMS or MM)?
Let’s do it – We’ll use the MM1 interface from the UE towards the MMSc (MMS Service Center) to send our Mobile Originated MMS.
Transport & Creation
Out of the box, our UE doesn’t get told by the network anything about where to send MMS messages (Unless set via something like Android’s Carrier Settings). Instead, this is typically configured by the user in the APN settings, by setting the MMSc address (Typically an FQDN), port (Typically 80) and often a Proxy (Which will actually handle the traffic). Lastly under the bearer type, if we’re sending the MMS on the default bearer (the one used for general Internet) then the bearer type will need to change from “default” to “default,mms”. Alternately, if you’re using a dedicated APN for MMS, you’ll need to set the bearer type to “mms”.
With the connectivity side setup, we’ll need to actually generate an MMS to send, something that is encapsulated in an MMS – so a picture is a good start.
We compose a message with this photo, put an address in the message and hit send on the UE.
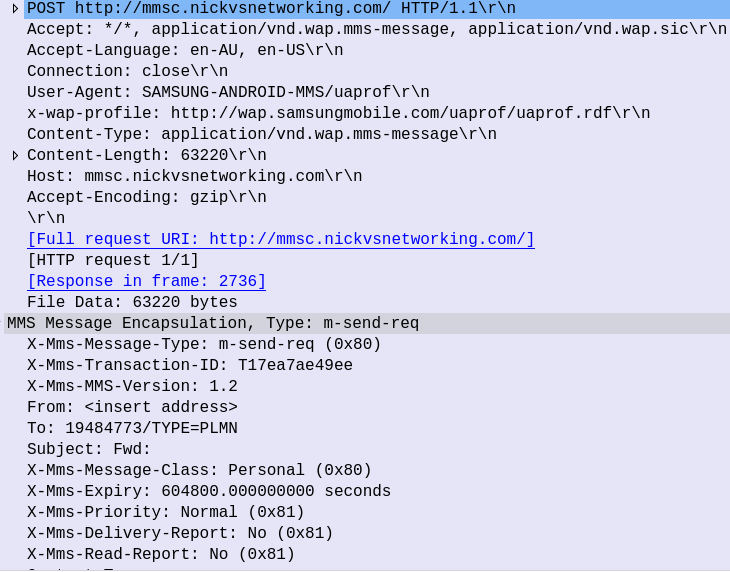
The UE encapsulates the photo and metadata, such as the To address, into an HTTP POST is sent to the IP & Port of your MMSc (Or proxy if you have that set). The body of this HTTP POST contains the MMS Message Body (In this case our picture).
Our MMSc receives this POST, extracts the headers of interest, and the multimedia message body itself (in our case the photo) ready to be forwarded onto their destination.
PCAP Extract showing MMS m-send-req from UE
Header Enrichment / Charging / Authentication
One thing to note is that the From header is empty.
Often times a UE doesn’t know it’s own MSISDN. While there is an MSISDN EF on the SIM file system, often this is not updated with the correct MSISDN, as a customer may have ported over their number from a different carrier, or had a replacement SIM reissued. There’s also some problems in just trusting the From address set by a UE, without verifying it as anyone could change this.
The MMS standards evolved in parallel to the 3GPP specifications, but were historically specified by the Open Mobile Alliance. Because it is at arms length with 3GPP, SIM based authentication was not used on the MM1 interface from a UE to the MMSc.
In fact, there is no authentication on an MMS specified in the standard, meaning in theory, anyone could send one. To counter this, the P-GW or GGSN handling the subscriber traffic often enables “Header Enrichment” which when it detects traffic on the MMS APN, will add a Header to the Mobile Originated request with the IMSI or MSISDN of the subscriber sending it, which the MMSc can use to bill the customer.
m-send-req Request
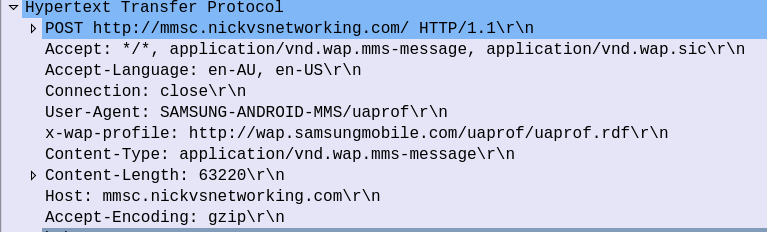
Let’s take a closer look into the HTTP POST sent by the UE containing the message.
Firstly we have what looks like a pretty bulk-standard HTTP POST header, albeit with some custom headers prefixed with “X-” and the Content-Type is application/vnd.wap.mms-message.
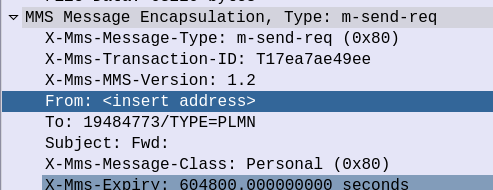
But immediately after the HTTP header in the HTTP message body, we have the “MMS Message Encapsulation” header:
MMS Message Encapsulation Header from MO MMS
This header contains the Destination we set in the MMS when sending it, the request type (m-send-req) as well as the actual content itself (inside the Data section).
So why the double header? Why not just encapsulate the whole thing in the HTTP Post? When MMS was introduced, most phones didn’t have a HTTP stack baked into them like everything does now. Instead traffic would be going through a WAP Gateway.
When usage of WAP fell away, the standard moved to transport the same payload that was transfered over WAP, to instead be transferred over HTTP.
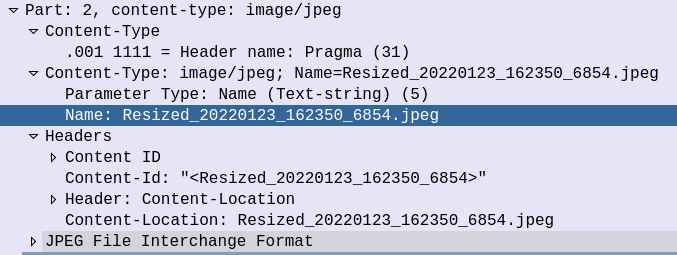
Inside the Data section we can see the MIME Type of the attachments themselves, in this case, it’s a photo of my desk:
With all this information, the MMSc analyses the headers and stores the message body ready for forwarding onto the recipient(/s).
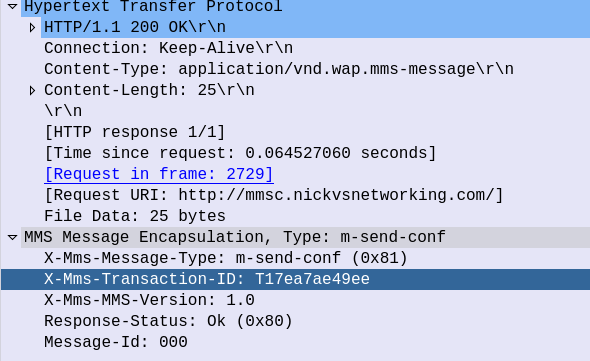
m-send-conf Response
To confirm successful receipt, the MMSc sends back a 200 OK with a matching Transaction ID, so the UE knows the message was accepted.
Unstructured Supplementary Service Data or “USSD” is the stack used in Cellular Networks to offer interactive text based menus and systems to Subscribers.
If you remember topping up your mobile phone credit via a text menu on your flip phone, there’s a good chance that was USSD*.
For a period, USSD Services provided Sporting Scores, Stock Prices and horoscopes on phones and networks that were not enabled for packet data.
Unlike plain SMS-PP, USSD services are transaction stateful, which means that there is a session / dialog between the subscriber and the USSD gateway that keeps track of the session and what has happened in the session thus far.
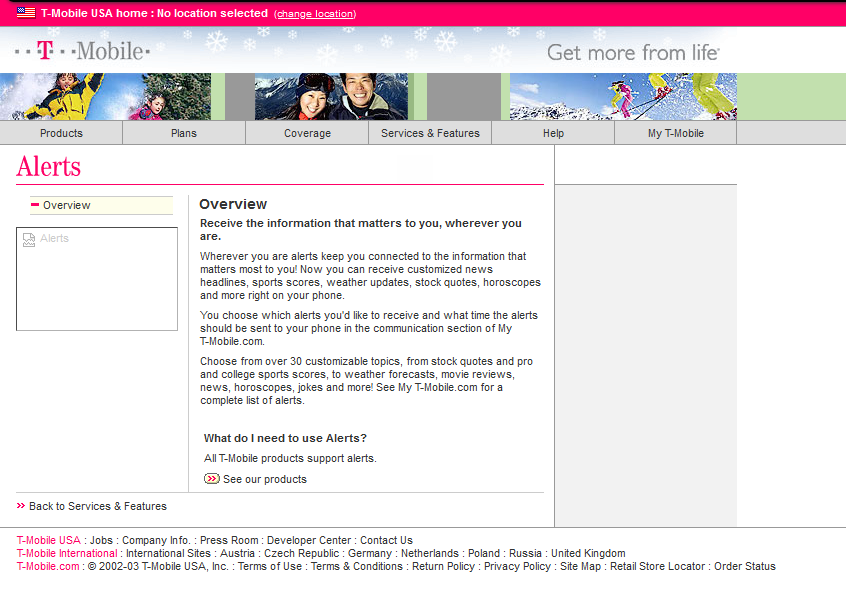
T-Mobile website from 2003 covering the features of their USSD based product at the time
Today USSD is primarily used in the network at times when a subscriber may not have balance to access packet data (Internet) services, so primarily is used for recharging with vouchers.
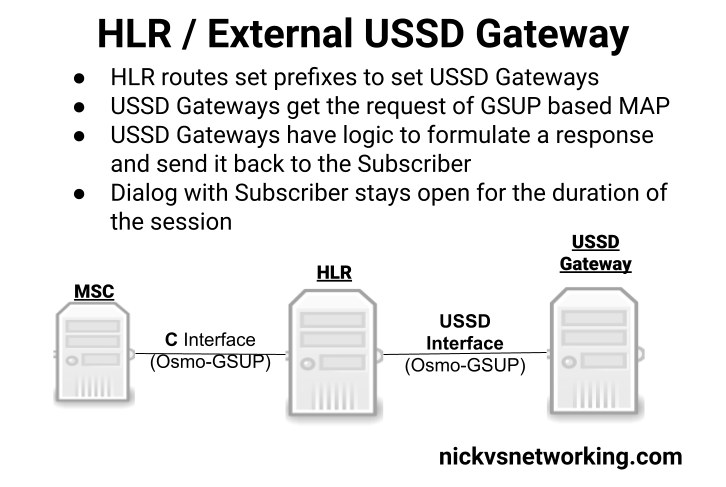
Osmocom’s HLR (osmo-hlr) has an External USSD interface to allow you to define the USSD logic in another entity, for example you could interface the USSD service with a chat bot, or interface with a billing system to manage credit.
Using the example code provided I made a little demo of how the service could be used:
Communication between the USSD Gateway and the HLR is MAP but carried GSUP (Rather than the full MTP3/SCCP/TCAP layers that traditionally MAP stits on top of), and inside the HLR you define the prefixes and which USSD Gateway to route them to (This would allow you to have multiple USSD gateways and route the requests to them based on the code the subscriber sends).
(I had hoped to make a Python example and actually interface it with some external systems, but another day!)
The signaling is fairly straight forward, when the subscriber kicks off the USSD request, the HLR calls a MAP Invoke operation for “processUnstructuredSS-Request”
Unfortunately is seems the stock Android does not support interactive USSD. This is exposed in the Android SDK so applications can access USSD interfaces (including interactive USSD) but the stock dialer on the few phones I played with did not, which threw a bit of a spanner in the works. There are a few apps that can help with this however I didn’t go into any of them.
(or maybe they used SIM Toolkit which had a similar interface)
This is part of a series of posts looking into SS7 and Sigtran networks. We cover some basic theory and then get into the weeds with GNS3 based labs where we will build real SS7/Sigtran based networks and use them to carry traffic.
So, all going well at this point in the tutorial you’ve got your lab setup with SS7 links between our simulated countries, but we haven’t dug too deep into what’s going on.
Most of the juicy stuff happens in the higher layers, but in this post we’ll look at the Data-Link layer for SS7.
In TDM based SS7 networks, Data Link layer is handled by a layer called “MTP2” – Message Transfer Part 2, which is responsible for flow control and ensuring guaranteed delivery between two points on the network.
MTP2 provides the services you’d typically expect at the Data Link Layer; link alignment, CRC generation/verification, end to end transmission between two points, flow control and sequence verification, etc.
MTP2 is responsible for making the connection between two points capable of carrying those far more interesting upper layers, but it’s really important, particularly when we talk about SIGTRAN/SS7 over IP, to understand how this can be done, so you can understand how the networks fit together.
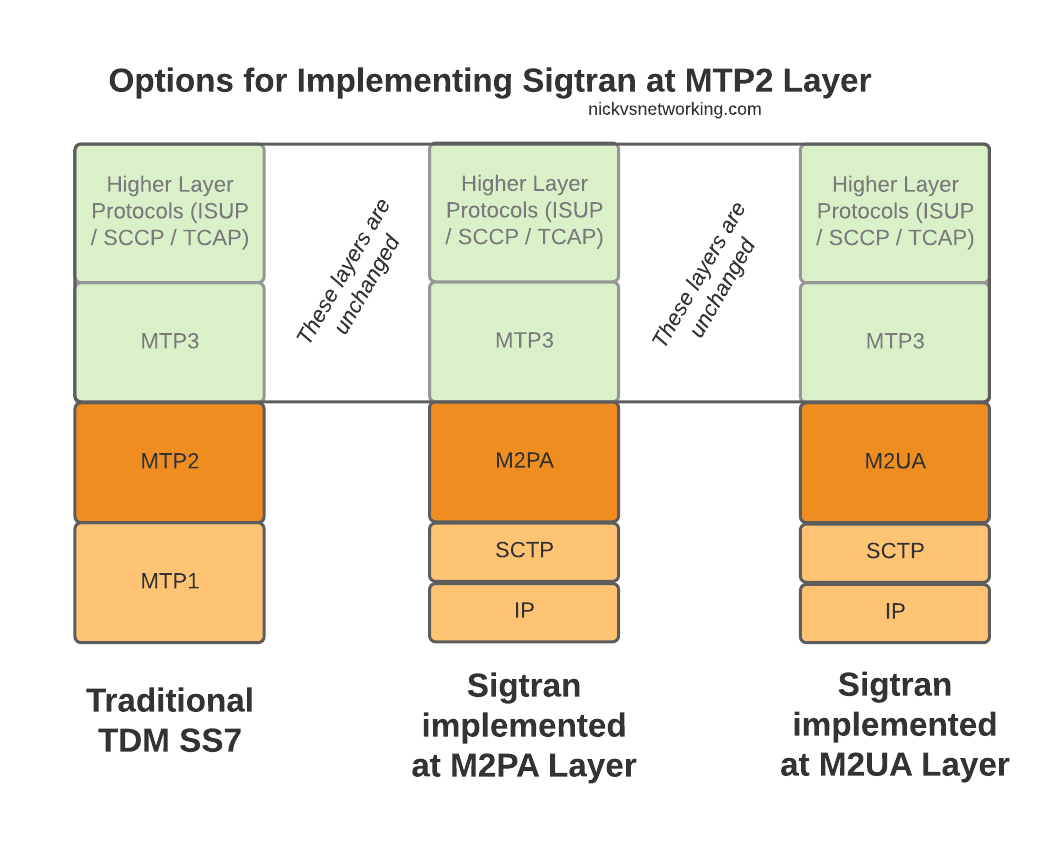
When we move from TDM based SS7 networks to IP based (Sigtran), MTP2 is removed, and can be replaced with one of two options for transporting Layer 2 messaging over IP, M2UA or M2PA.
All the layers above MTP2 on SS7 or M2UA/M2PA on Sigtran, are unchanged, and the upper layers have no visability that underneath, MTP2 has been replaced with M2UA or M2PA.
Taking MTP2 and putting it onto an IP based Layer 2 protocol is only one option for implementing Sigtran, there are others that we’ll look into as we go along, but with this variant the upper layers above Layer 2 (MTP3) remain changed.
Putting SS7 Data Link Layer (MTP2) onto IP
So the two options – M2UA and M2PA. Why do we have two options?
SS7 networks can be really complicated, and different operators may have different needs when converting these networks to IP.
To satisfy those requirements, there’s a bunch of different flavors of SS7 over IP (Sigtran) available to implement, so operators can select the one that meets their needs and use cases.
This means when we’re learning it, there’s a stack of different options to cover.
On the Layer 2 Level, let’s look at the two options we have in some more detail.
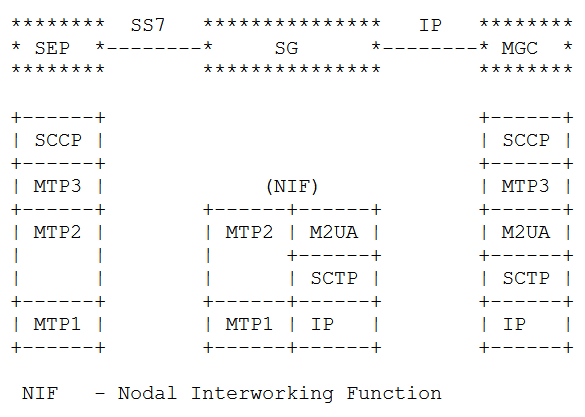
The M2UA Flavour
Image from RFC 4165 / 1.9. Differences Between M2PA and M2UA – Showing M2UA
With a “Nodal Interworking Function” using M2UA, the point codes between our two SS7 nodes remain unchanged.
The SS7 node on the left still talks MTP3 directly with the SS7 node on the right, and the NIF just transparently translates MTP2 into M2UA.
The best analogy I can come up with is that you can think of this as kind of like a Media Converter you’d use for converting between Cat5 to fibre – The devices at each end don’t know they’re not talking over a straight ethernet cable between them, but the media converter changes the transmission medium in between the two in a transparent manner.
M2UA acts in much the same way, except we’re transparently converting the layer 1 & layer 2 signaling, in a way that end devices in the network don’t need to be aware of.
The advantage of this option is that no config changes are needed, we’ve taken our Linksets that were running on TDM and converted them to IP so both ends of the linkset can be moved anywhere with IP connectivity, but transparently to the end devices.
For some carriers this is a real advantage – If you’ve got a dusty SSP running parts of your Customer Access Network, but the engineers who set it up retired long ago and you just want to drop those leased lines, M2UA could be a good option for you.
The disadvantage, as you might have guessed, is that we don’t get much value from just replacing the link from one point to another. It solves one problem, but doesn’t take that much of a step towards converging our network to run over IP.
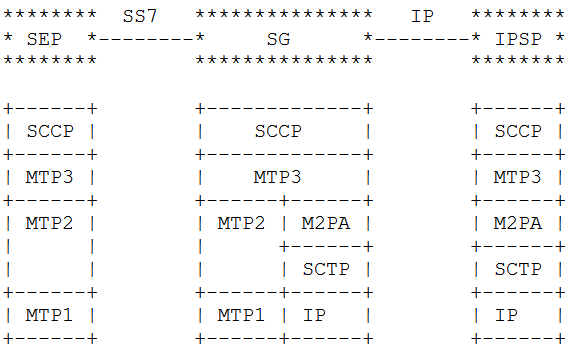
The M2PA Way
The M2PA way looks a bit different. You’ll notice we’ve got MTP3 on the Signaling Gateway we’re introducing into the network.
This means we need to add a point code between the SS7 node on the left and the SS7 node on the right, where there wasn’t one before, and we will need to update the routing tables on both to know to now route to each other via the point code of our Signaling Gateway rather than directly as the would have before we introduced the Signaling Gateway.
Image from RFC 4165 / 1.9. Differences Between M2PA and M2UA – Showing M2PA
We add another point code and an “active” SS7 device, but now we’ve got a lot more flexibility with what we can do, this no longer needs to be a point-to-point link, but with the introduction of the Signaling Gateway can be point-to-multipoint.
So which to chose? Well the answer is (as always) it depends.
If you cannot change any config on the end device (as the person who understood how all this stuff works retired long ago), then M2UA is the answer. M2UA is just an extension/branch of the MTP2 layer onto IP, it has no understanding / support for the higher-layers of SS7. M2UA is simpler, it doesn’t require as much understanding, it’s a quick-and-easy “drop-in” replacement for back-hauling SS7 onto IP. As it’s fairly dumb, M2UA can also allow us to split the load on a high traffic device across two or more SS7 nodes behind it, somewhat like a layer 2 load balancer, but this use case is pretty irrelevant these days.
M2PA on the other hand introduces a new Point Code (Operating on Layer 3 / MTP3) in between the two devices. This means we introduce a new point code in the path, so have to reconfigure the end devices, but affords us access to a lot of newer features. We can do all sorts of fancy things like routing of MTP3 messages, on the Signaling Gateway. This allows us to structure our network in new ways, rather than just doing what we were doing before but over IP.
Summary
When it comes to taking SS7 traffic and putting it onto IP at the Layer 2 level, we looked at the two most common options – M2PA and M2UA, and the pros and cons of each.
In our next post we’ll look at doing away with MTP2 layer entirely when we look at M3UA…
This post is one of a series of packet capture analysis challenges designed to test your ability to understand what is going on in a network from packet captures. Download the Packet Capture and see how many of the questions you can answer from the attached packet capture.
The answers are at the bottom of this page, along with how we got to the answers.
This challenge focuses on the Evolved Packet Core, specifically the S1 and Diameter interfaces.
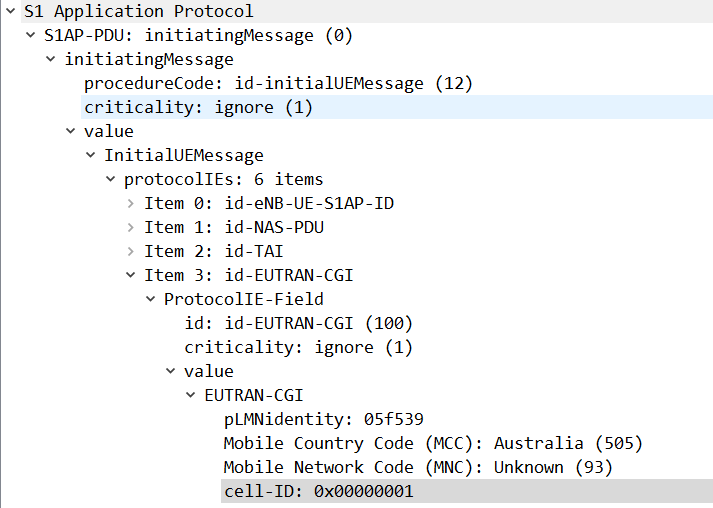
In Uplink messages from the eNodeB the EUTRAN-GCI field contains the Cell-ID of the eNodeB.
In this case the Cell-ID is 1.
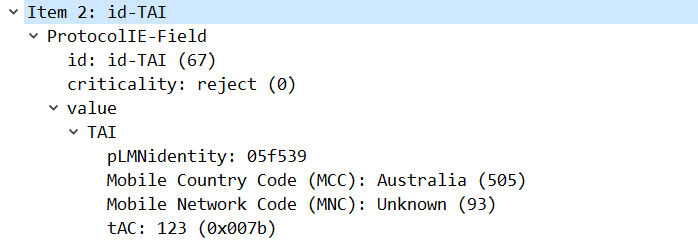
Answer: What is the Tracking Area?
The tracking area is 123.
This information is available in the TAI field in the Uplink S1 messages.
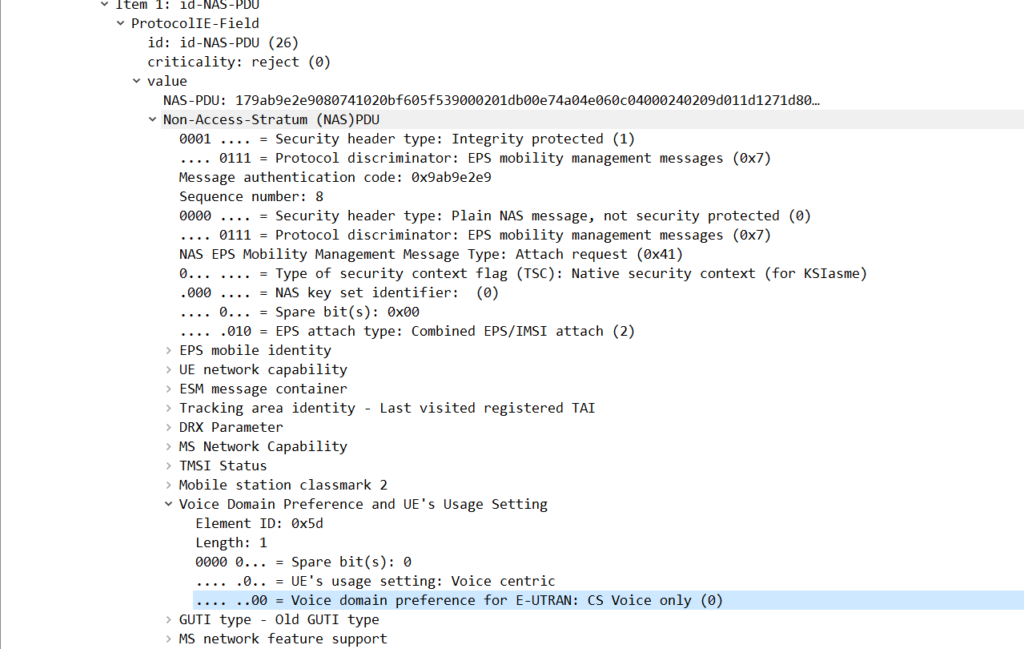
Answer: Does the device attaching to the network support VoLTE?
No, the device does not support VoLTE.
There are a few ways we can get to this answer, and VoLTE support in the phone does not mean VoLTE will be enabled, but we can see the Voice Domain preference is set to CS Voice Only, meaning GSM/UMTS for voice calling.
This is common on cheaper handsets that do not support VoLTE.
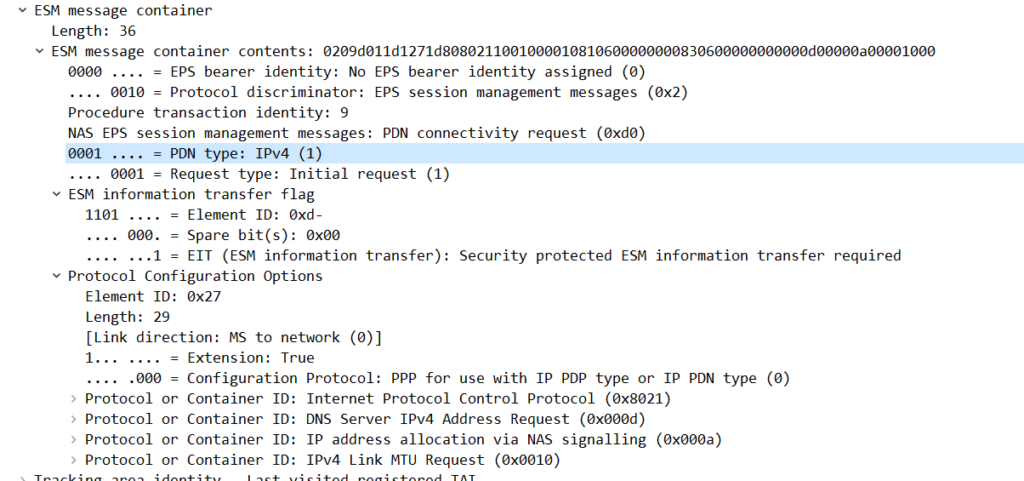
Answer: What type of IP is the subscriber requesting for this PDN session? (IPv4/IPv6/Both)?
The subscriber is requesting an IPv4 address only.
We can see this in the ESM Message Container for the PDN Connectivity Request, the PDN type is “IPv4”.
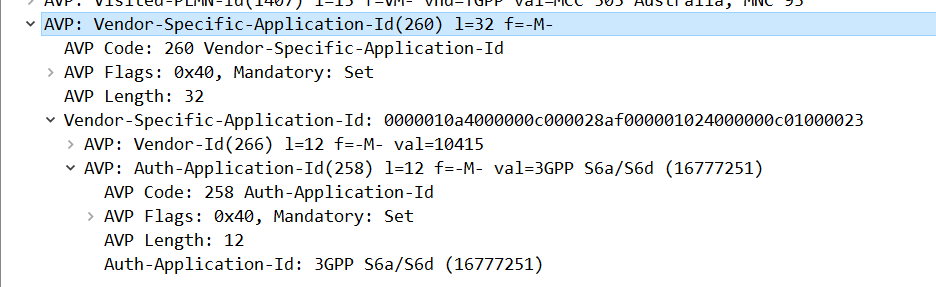
Answer: What is the Diameter Application ID for S6a?
Answer: 16777251
This is shown for the Vendor-Specific-Application-Id AVP on an S6a message.
Answer: What is the Crytpo RES returned by the HSS, and what is the RES returned by the SIM/UE?
The RES (Response) and X-RES (Expected Response) Both are “dba298fe58effb09“, they do match, which means this subscriber was authenticated successfully.
In iOS 15, Apple added support for iPhones to support SMS over IMS networks – SMSoIP. Previously iPhone users have been relying on CSFB / SMSoNAS (Using the SGs interface) to send SMS on 4G networks.
Getting this working recently led me to some issues that took me longer than I’d like to admit to work out the root cause of…
I was finding that when sending a Mobile Termianted SMS to an iPhone as a SIP MESSAGE, the iPhone would send back the 200 OK to confirm delivery, but it never showed up on the screen to the user.
The GSM A-I/F headers in an SMS PDU are used primarily for indicating the sender of an SMS (Some carriers are configured to get this from the SIP From header, but the SMS PDU is most common).
The RP-Destination Address is used to indicate the destination for the SMS, and on all the models of handset I’ve been testing with, this is set to the MSISDN of the Subscriber.
But some devices are really finicky about it’s contents. Case in point, Apple iPhones.
If you send a Mobile Terminated SMS to an iPhone, like the one below, the iPhone will accept and send back a 200 OK to this request.
The problem is it will never be displayed to the user… The message is marked as delivered, the phone has accepted it it just hasn’t shown it…
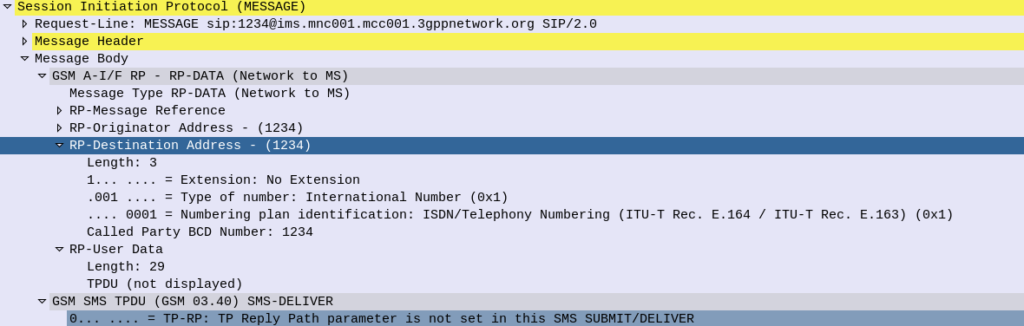
SMS reports as delivered by the iPhone (200 OK back) but never gets displayed to the user of the phone as the RP-Destination Address header is populated
The fix is simple enough, if you set the RP-Destination Address header to 0, the message will be displayed to the user, but still took me a shamefully long time to work out the problem.
RP-Destination Address set to 0 sent to the iPhone, this time it’ll get displayed to the user.
After getting AMR support in FreeSWITCH I set about creating an IMS Application Server for VoLTE / IMS networks using FreeSWITCH.
So in IMS what is an Application Server? Well, the answer is almost anything that’s not a CSCF.
An Application Server could handle your Voicemail, recorded announcements, a Conference Factory, or help interconnect with other systems (without using a BGCF).
I’ll be using mine as a simple bridge between my SIP network and the IMS core I’ve got for VoLTE, with FreeSWITCH transcoding between AMR to PCMA.
Setting up FreeSWITCH
You’ll need to setup FreeSWITCH as per your needs, so that’s however you want to use it.
This post won’t cover setting up FreeSWITCH, there’s plenty of good resources out there for that.
The only difference is when you install FreeSWITCH, you will want to compile with AMR Support, so that you can interact with mobile phones using the AMR codec, which I’ve documented how to do here.
Setting up your IMS
In order to get calls from the IMS to the Application Server, we need a way of routing the calls to the Application Server.
There are two standards-compliant ways to achieve this,
But this is a blunt instrument, after all, it’ll only ever be used at the start of the call, what if we want to send it to an AS because a destination can’t be reached and we want to play back a recorded announcement?
I’ve recently been writing a lot about SS7 / Sigtran, and couldn’t fit this in anywhere, but figured it may be of use to someone…
In our 3-8-3 formated ITU International Point code, each of the parts have a unique meaning.
The 3 bits in the first section are called the Zone section. Being only 3 bits long it means we can only encode the numbers 0-7 on them, but ITU have broken the planet up into different “zones”, so the first part of our ITU International Point Code denotes which Zone the Point Code is in (as allocated by ITU).
The next 8 bits in the second section (Area section) are used to define the “Signaling Area Network Code” (SANC), which denotes which country a point code is located in. Values can range from 0-255 and many countries span multiple SANC zones, for example the USA has 58 SANC Zones.
Lastly we have the last 3 bits that make up the ID section, denoting a single unique point code, typically a carrier’s international gateway. It’s unique within a Zone & SANC, so combined with the Zone-SANC-ID makes it a unique address on the SS7 network. Being only 3 bits long means that we’ve only got 8 possible values, hence so many SANCs being used.
2
Europe
3
Greenland, North America, the Caribbean, and Mexico
This is part of a series of posts looking into SS7 and Sigtran networks. We cover some basic theory and then get into the weeds with GNS3 based labs where we will build real SS7/Sigtran based networks and use them to carry traffic.
Having a direct Linkset from every Point Code to every other Point Code in an SS7 network isn’t practical, we need to rely on routing, so in this post we’ll cover routing between Point Codes on our STPs.
Let’s start in the IP world, imagine a router with a routing table that looks something like this:
Simple IP Routing Table
192.168.0.0/24 out 192.168.0.1 (Directly Attached)
172.16.8.0/22 via 192.168.0.3 - Static Route - (Priority 100)
172.16.0.0/16 via 192.168.0.2 - Static Route - (Priority 50)
10.98.22.1/32 via 192.168.0.3 - Static Route - (Priority 50)
We have an implicit route for the network we’re directly attached to (192.168.0.0/24), and then a series of static routes we configure. We’ve also got two routes to the 172.16.8.0/22 subnet, one is more specific with a higher priority (172.16.8.0/22 – Priority 100), while the other is less specific with a lower priority (172.16.0.0/16 – Priority 50). The higher priority route will take precedence.
This should look pretty familiar to you, but now we’re going to take a look at routing in SS7, and for that we’re going to be talking Variable Length Subnet Masking in detail you haven’t needed to think about since doing your CCNA years ago…
Why Masking is Important
A route to a single Point Code is called a “/14”, this is akin to a single IPv4 address being called a “/32”.
We could setup all our routing tables with static routes to each point code (/14), but with about 4,000 international point codes, this might be a challenge.
Instead, by using Masks, we can group together ranges of Point Codes and route those ranges through a particular STP.
This opens up the ability to achieve things like “Route all traffic to Point Codes to this Default Gateway STP”, or to say “Route all traffic to this region through this STP”.
Individually routing to a point code works well for small scale networking, but there’s power, flexibility and simplification that comes from grouping together ranges of point codes.
Information Overload about Point Codes
So far we’ve talked about point codes in the X.YYY.Z format, in our lab we setup point codes like 1.2.3.
This is not the only option however…
Variants of SS7 Point Codes
IPv4 addresses look the same regardless of where you are. From Algeria to Zimbabwe, IPv4 addresses look the same and route the same.
In SS7 networks that’s not the case – There are a lot of variants that define how a point code is structured, how long it is, etc. Common variants are ANSI, ITU-T (International & National variants), ETSI, Japan NTT, TTC & China.
The SS7 variant used must match on both ends of a link; this means an SS7 node speaking ETSI flavoured Point Codes can’t exchange messages with an ANSI flavoured Point Code.
Well, you can kinda translate from one variant to another, but requires some rewriting not unlike how NAT does it.
ITU International Variant
For the start of this series, we’ll be working with the ITU International variant / flavour of Point Code.
ITU International point codes are 14 bits long, and format is described as 3-8-3. The 3-8-3 form of Point code just means the 14 bit long point code is broken up into three sections, the first section is made up of the first 3 bits, the second section is made up of the next 8 bits then the remaining 3 bits in the last section, for a total of 14 bits.
So our 14 bit 3-8-3 Point Code looks like this in binary form:
If you’re dealing with multiple vendors or products,you’ll see some SS7 Point Codes represented as decimal (2067), some showing as 1-2-3 codes and sometimes just raw binary. Fun hey?
So why does the binary part matter? Well the answer is for masks.
To loop back to the start of this post, we talked about IP routing using a network address and netmask, to represent a range of IP addresses. We can do the same for SS7 Point Codes, but that requires a teeny bit of working out.
As an example let’s imagine we need to setup a route to all point codes from 3-4-0 through to 3-6-7, without specifying all the individual point codes between them.
Firstly let’s look at our start and end point codes in binary:
100-00000100-000 = 3-004-0 (Start Point Code)
100-00000110-111 = 3-006-7 (End Point Code)
Looking at the above example let’s look at how many bits are common between the two,
100-00000100-000 = 3-004-0 (Start Point Code)
100-00000110-111 = 3-006-7 (End Point Code)
The first 9 bits are common, it’s only the last 5 bits that change, so we can group all these together by saying we have a /9 mask.
When it comes time to add a route, we can add a route to 3-4-0/9 and that tells our STP to match everything from point code 3-4-0 through to point code 3-6-7.
The STP doing the routing it only needs to match on the first 9 bits in the point code, to match this route.
SS7 Routing Tables
Now we have covered Masking for roues, we can start putting some routes into our network.
In order to get a message from one point code to another point code, where there isn’t a direct linkset between the two, we need to rely on routing, which is performed by our STPs.
This is where all that point code mask stuff we just covered comes in.
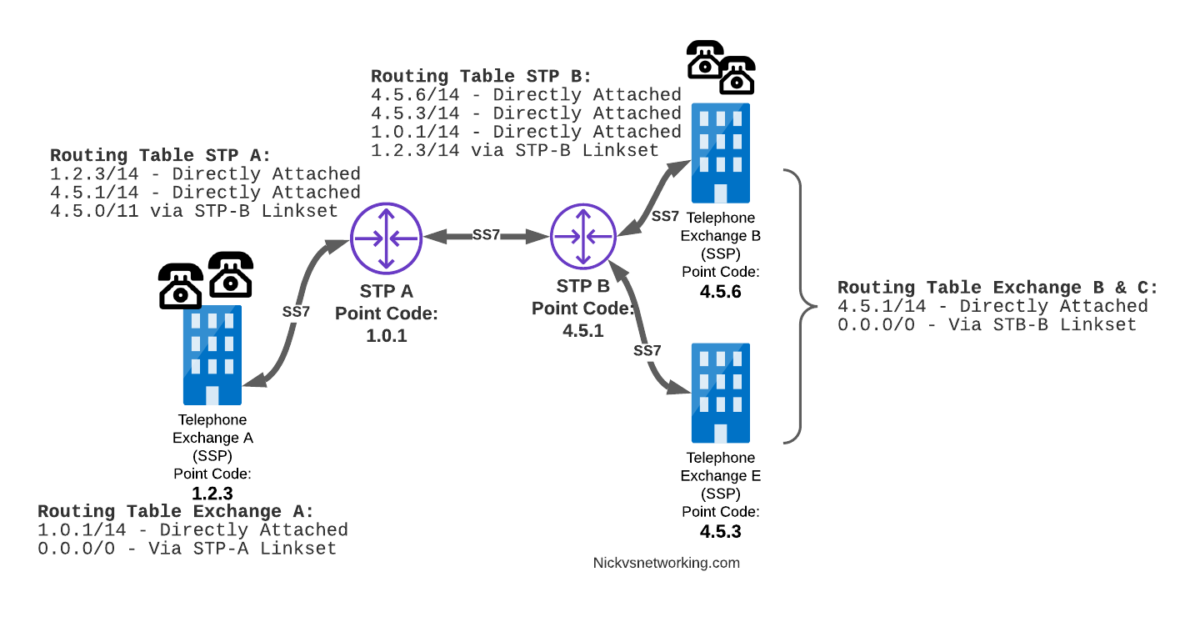
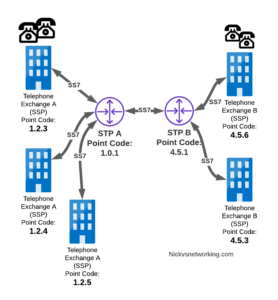
Let’s look at a diagram below,
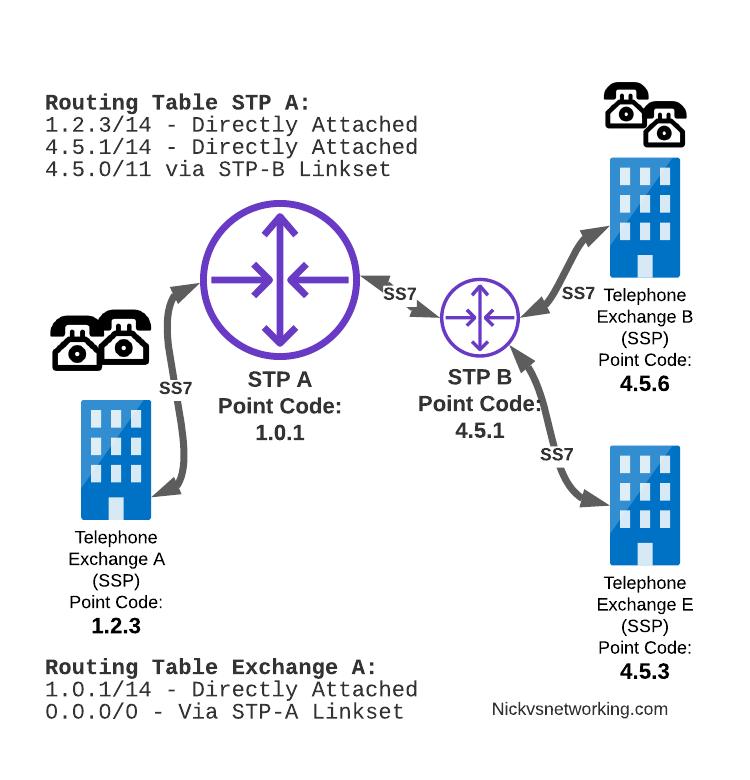
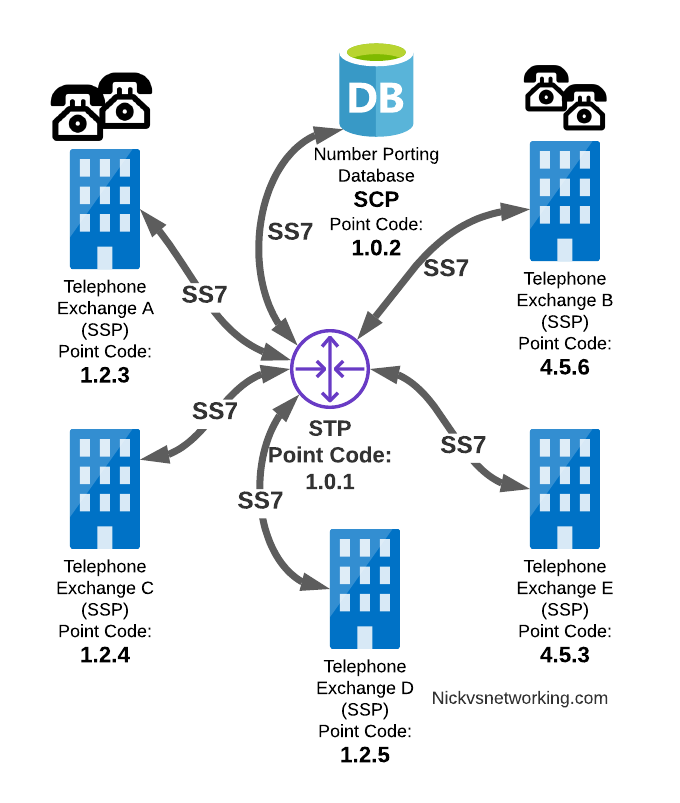
Let’s look at the routing to get a message from Exchange A (SSP) on the bottom left of the picture to Exchange E (SSP) with Point Code 4.5.3 in the bottom right of the picture.
Exchange A (SSP) on the bottom left of the picture has point code 1.2.3 assigned to it and a Linkset to STP-A. It has the implicit route to STP-A as it’s got that linkset, but it’s also got a route configured on it to reach any other point code via the Linkset to STP-A via the 0.0.0/0 route which is the SS7 equivalent of a default route. This means any traffic to any point code will go to STP-A.
From STP-A we have a linkset to STP-B. In order to route to the point codes behind STP-B, STP-A has a route to match any Point Code starting with 4.5.X, which is 4.5.0/11. This means that STP-A will route any Point Code between 4.5.1 and 4.5.7 down the Linkset to STP-B.
STP-B has got a direct connection to Exchange B and Exchange E, so has implicit routes to reach each of them.
So with that routing table, Exchange A should be able to route a message to Exchange E.
But…
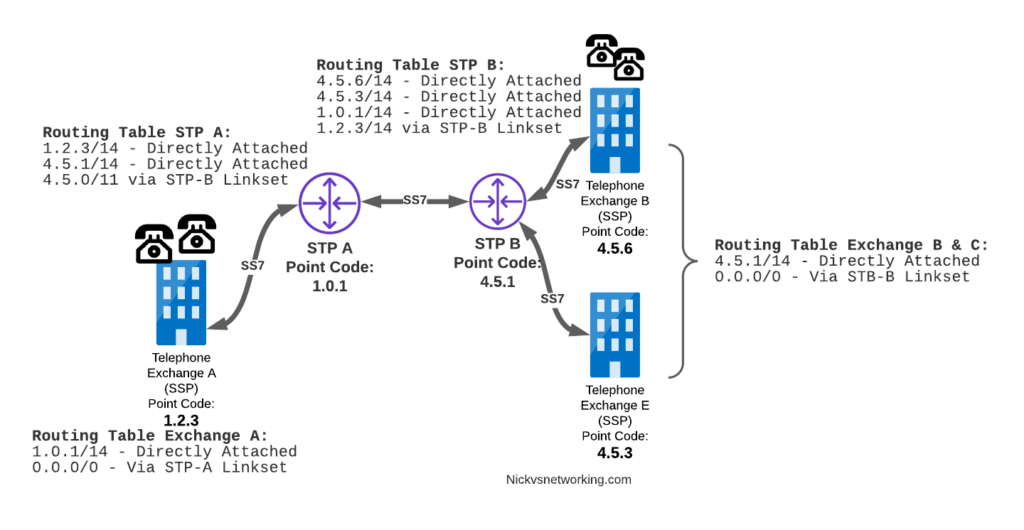
Return Routing
Just like in IP routing, we need return routing. while Exchange A (SSP) at 1.2.3 has a route to everywhere in the network, the other parts of the network don’t have a route to get to it. This means a request from 1.2.3 can get anywhere in the network, but it can’t get a response back to 1.2.3.
So to get traffic back to Exchange A (SSP) at 1.2.3, our two Exchanges on the right (Exchange B & C with point codes 4.5.6 and 4.5.3) will need routes added to them. We’ll also need to add routes to STP-B, and once we’ve done that, we should be able to get from Exchange A to any point code in this network.
There is a route missing here, see if you can pick up what it is!
So we’ve added a default route via STP-B on Exchange B & Exchange E, and added a route on STP-B to send anything to 1.2.3/14 via STP-A, and with that we should be able to route from any exchange to any other exchange.
One last point on terminology – when we specify a route we don’t talk in terms of the next hop Point Code, but the Linkset to route it down. For example the default route on Exchange A is 0.0.0/0 via STP-A linkset (The linkset from Exchange A to STP-A), we don’t specify the point code of STP-A, but just the name of the Linkset between them.
Back into the Lab
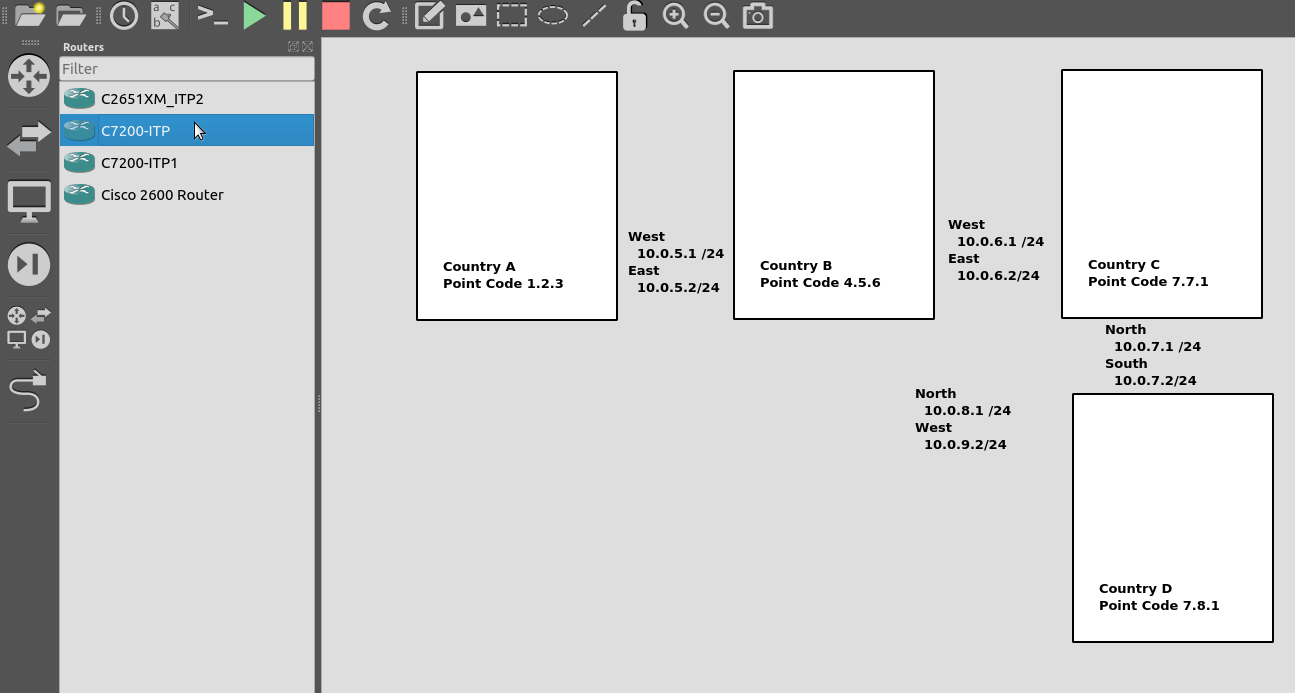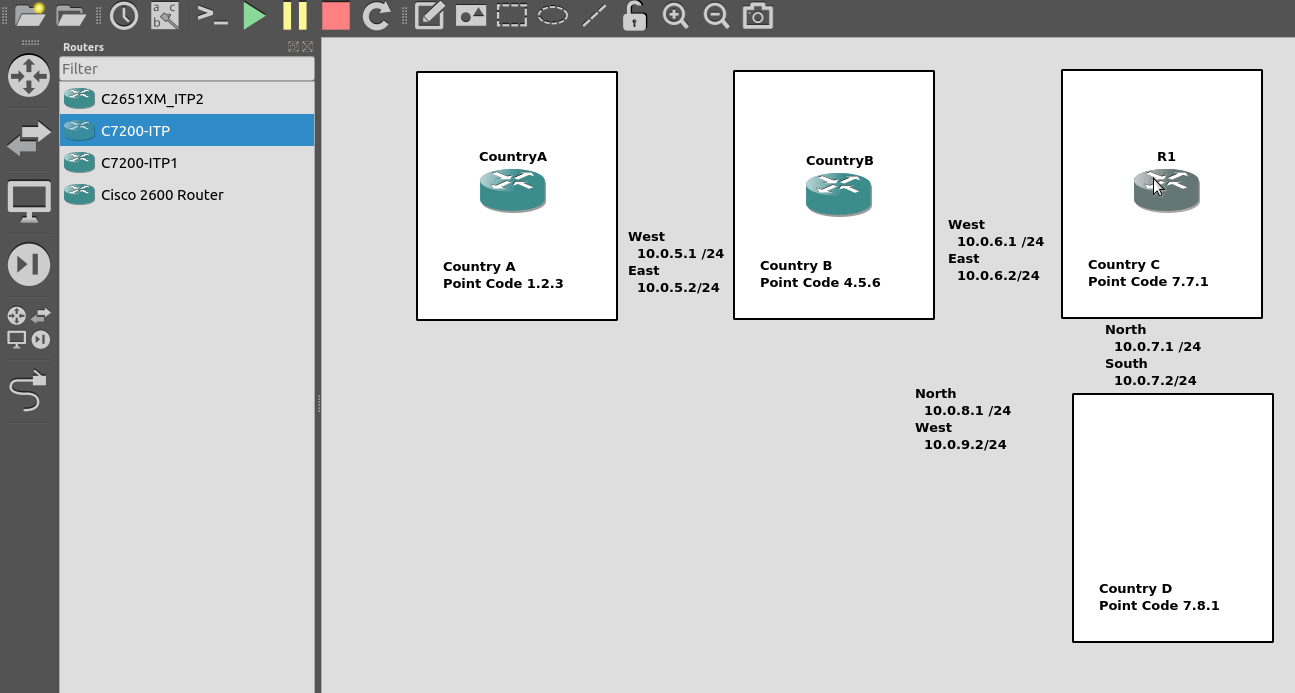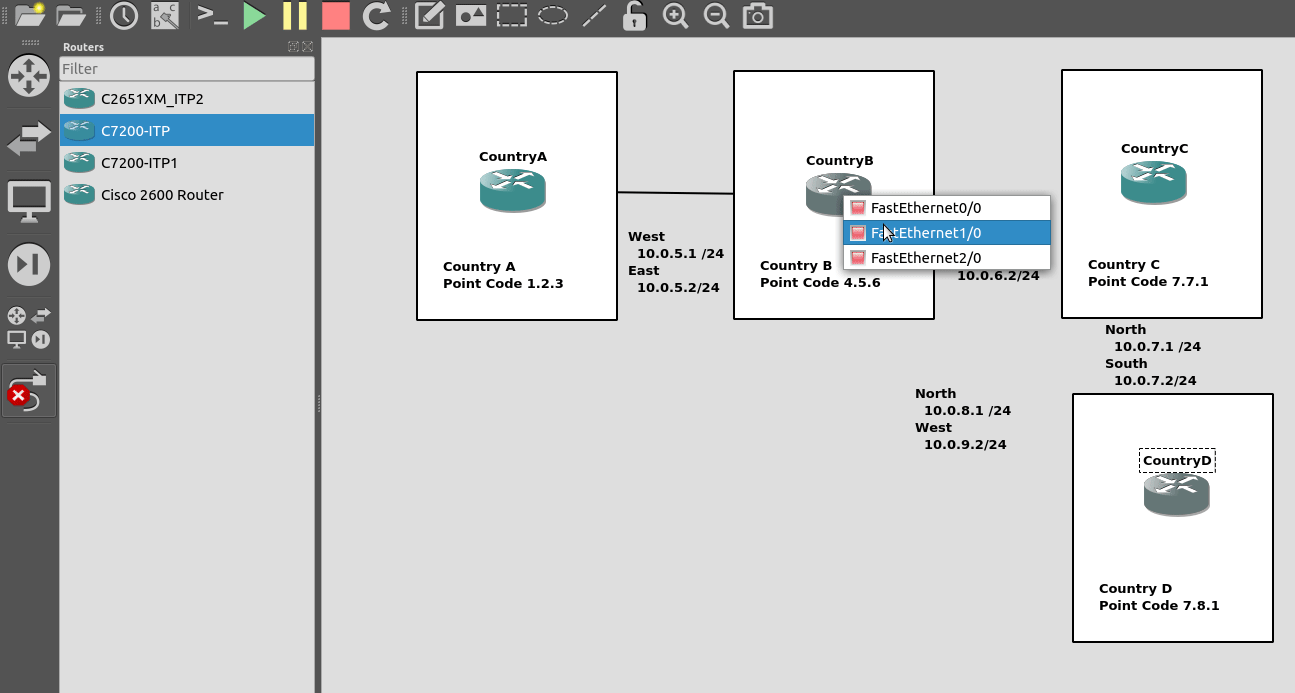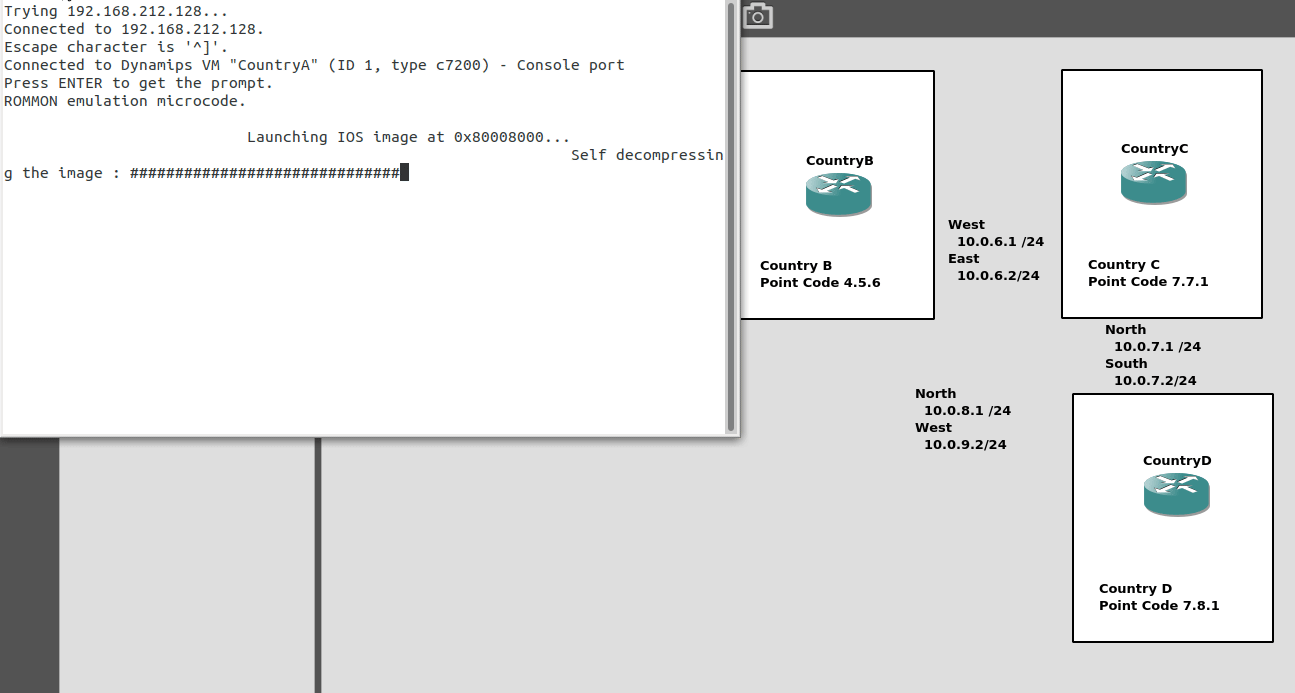
So back to the lab, where we left it was with linksets between each point code, so each Country could talk to it’s neighbor.
Let’s confirm this is the case before we go setting up routes, then together, we’ll get a route from Country A to Country C (and back).
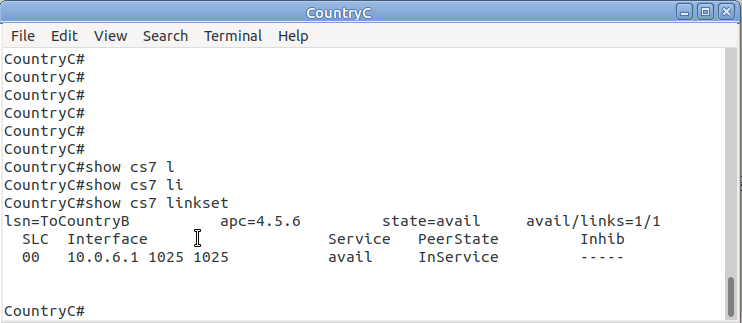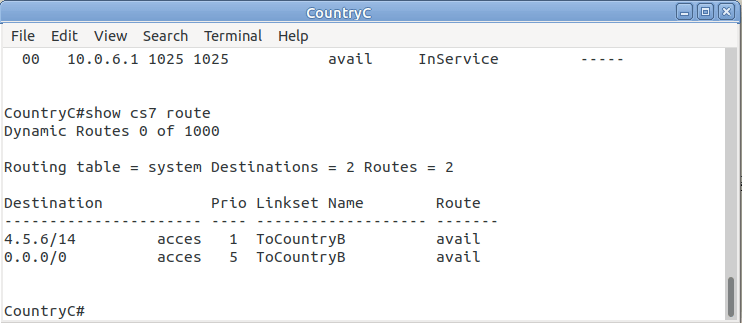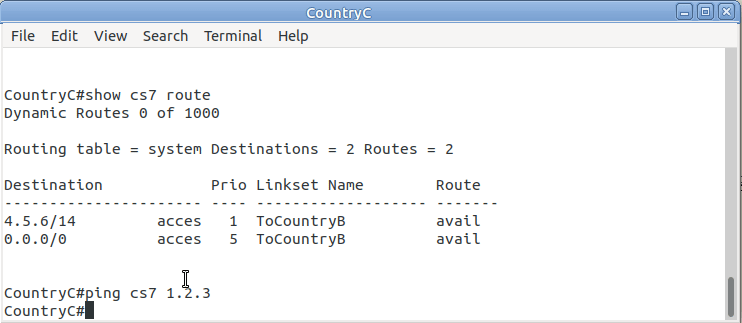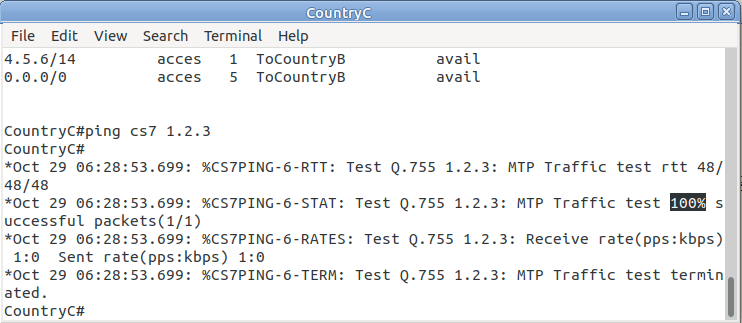
So let’s check the status of the link from Country B to its two neighbors – Country A and Country C. All going well it should look like this, and if it doesn’t, then stop by my last post and check you’ve got everything setup.
So let’s add some routing so Country A can reach Country C via Country B. On Country A STP we’ll need to add a static route. For this example we’ll add a route to 7.7.1/14 (Just Country C).
That means Country A knows how to get to Country C. But with no return routing, Country C doesn’t know how to get to Country A. So let’s fix that.
We’ll add a static route to Country C to send everything via Country B.
CountryC#conf t
Enter configuration commands, one per line. End with CNTL/Z.
CountryC(config)#cs7 route-table system
CountryC(config)#update route 0.0.0/0 linkset ToCountryB
*Jan 01 05:37:28.879: %CS7MTP3-5-DESTSTATUS: Destination 0.0.0 is accessible
So now from Country C, let’s see if we can ping Country A (Ok, it’s not a “real” ICMP ping, it’s a link state check message, but the result is essentially the same).
By running:
CountryC# ping cs7 1.2.3
*Jan 01 06:28:53.699: %CS7PING-6-RTT: Test Q.755 1.2.3: MTP Traffic test rtt 48/48/48
*Jan 01 06:28:53.699: %CS7PING-6-STAT: Test Q.755 1.2.3: MTP Traffic test 100% successful packets(1/1)
*Jan 01 06:28:53.699: %CS7PING-6-RATES: Test Q.755 1.2.3: Receive rate(pps:kbps) 1:0 Sent rate(pps:kbps) 1:0
*Jan 01 06:28:53.699: %CS7PING-6-TERM: Test Q.755 1.2.3: MTP Traffic test terminated.
We can confirm now that Country C can reach Country A, we can do the same from Country A to confirm we can reach Country B.
But what about Country D? The route we added on Country A won’t cover Country D, and to get to Country D, again we go through Country B.
This means we could group Country C and Country D into one route entry on Country A that matches anything starting with 7-X-X,
For this we’d add a route on Country A, and then remove the original route;
Of course, you may have already picked up, we’ll need to add a return route to Country D, so that it has a default route pointing all traffic to STP-B. Once we’ve done that from Country A we should be able to reach all the other countries:
CountryA#show cs7 route
Dynamic Routes 0 of 1000
Routing table = system Destinations = 3 Routes = 3
Destination Prio Linkset Name Route
---------------------- ---- ------------------- -------
4.5.6/14 acces 1 ToCountryB avail
7.0.0/3 acces 5 ToCountryB avail
CountryA#ping cs7 7.8.1
*Jan 01 07:28:19.503: %CS7PING-6-RTT: Test Q.755 7.8.1: MTP Traffic test rtt 84/84/84
*Jan 01 07:28:19.503: %CS7PING-6-STAT: Test Q.755 7.8.1: MTP Traffic test 100% successful packets(1/1)
*Jan 01 07:28:19.503: %CS7PING-6-RATES: Test Q.755 7.8.1: Receive rate(pps:kbps) 1:0 Sent rate(pps:kbps) 1:0
*Jan 01 07:28:19.507: %CS7PING-6-TERM: Test Q.755 7.8.1: MTP Traffic test terminated.
CountryA#ping cs7 7.7.1
*Jan 01 07:28:26.839: %CS7PING-6-RTT: Test Q.755 7.7.1: MTP Traffic test rtt 60/60/60
*Jan 01 07:28:26.839: %CS7PING-6-STAT: Test Q.755 7.7.1: MTP Traffic test 100% successful packets(1/1)
*Jan 01 07:28:26.839: %CS7PING-6-RATES: Test Q.755 7.7.1: Receive rate(pps:kbps) 1:0 Sent rate(pps:kbps) 1:0
*Jan 01 07:28:26.843: %CS7PING-6-TERM: Test Q.755 7.7.1: MTP Traffic test terminated.
So where to from here?
Well, we now have a a functional SS7 network made up of STPs, with routing between them, but if we go back to our SS7 network overview diagram from before, you’ll notice there’s something missing from our lab network…
So far our network is made up only of STPs, that’s like building a network only out of routers!
In our next lab, we’ll start adding some SSPs to actually generate some SS7 traffic on the network, rather than just OAM traffic.
This is part of a series of posts looking into SS7 and Sigtran networks. We cover some basic theory and then get into the weeds with GNS3 based labs where we will build real SS7/Sigtran based networks and use them to carry traffic.
So we’ve made it through the first two parts of this series talking about how it all works, but now dear reader, we build an SS7 Lab!
At one point, and SS7 Signaling Transfer Point would be made up of at least 3 full size racks, and cost $5M USD. We can run a dozen of them inside GNS3!
Cisco’s “IP Transfer Point” (ITP) software adds SS7 STP functionality to some models of Cisco Router, like the 2651XM and C7200 series hardware.
Luckily for us, these hardware platforms can be emulated in GNS3, so that’s how we’ll be setting up our instances of Cisco’s ITP product to use as STPs in our network.
For the rest of this post series, I’ll refer to Cisco’s IP Transfer Point as the “Cisco STP”.
Not open source you say! Osmocom have OsmoSTP, which we’ll introduce in a future post, and elaborate on why later…
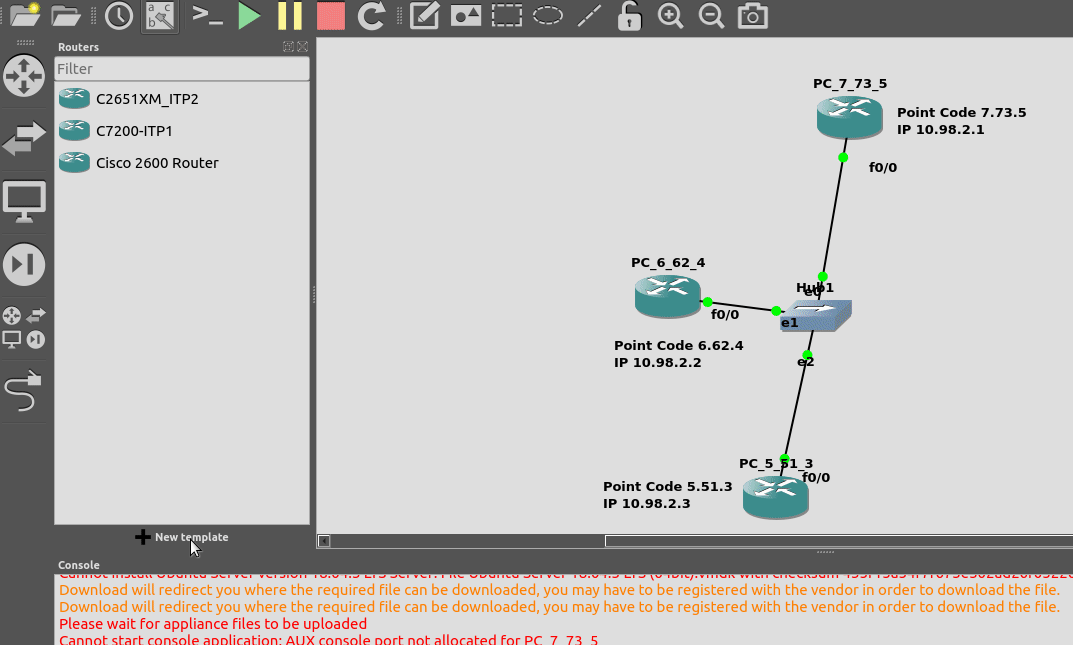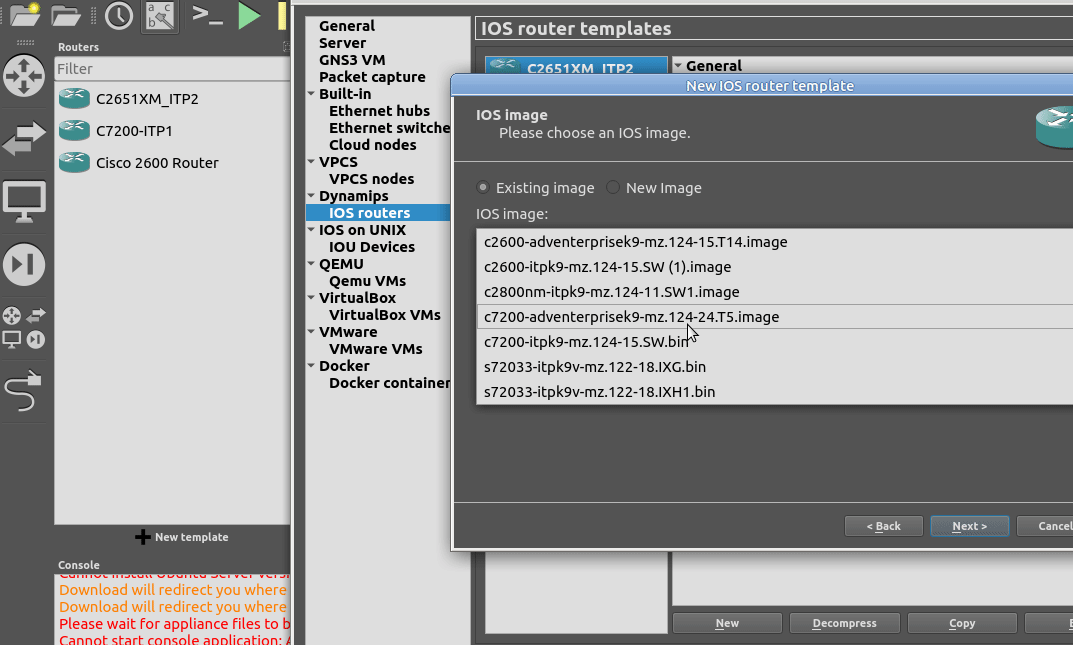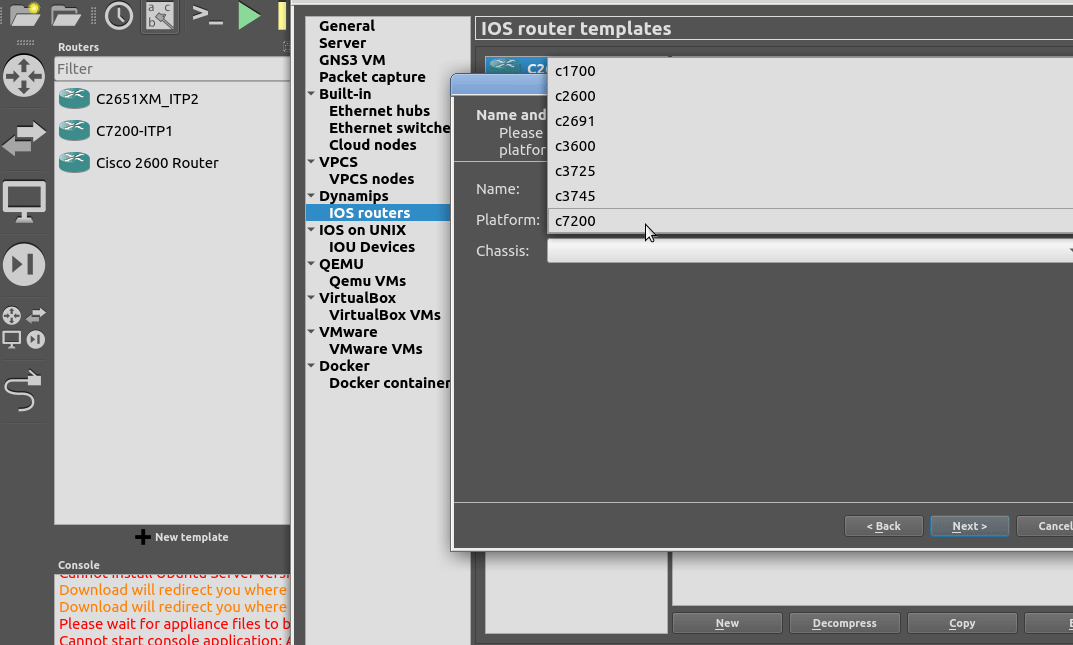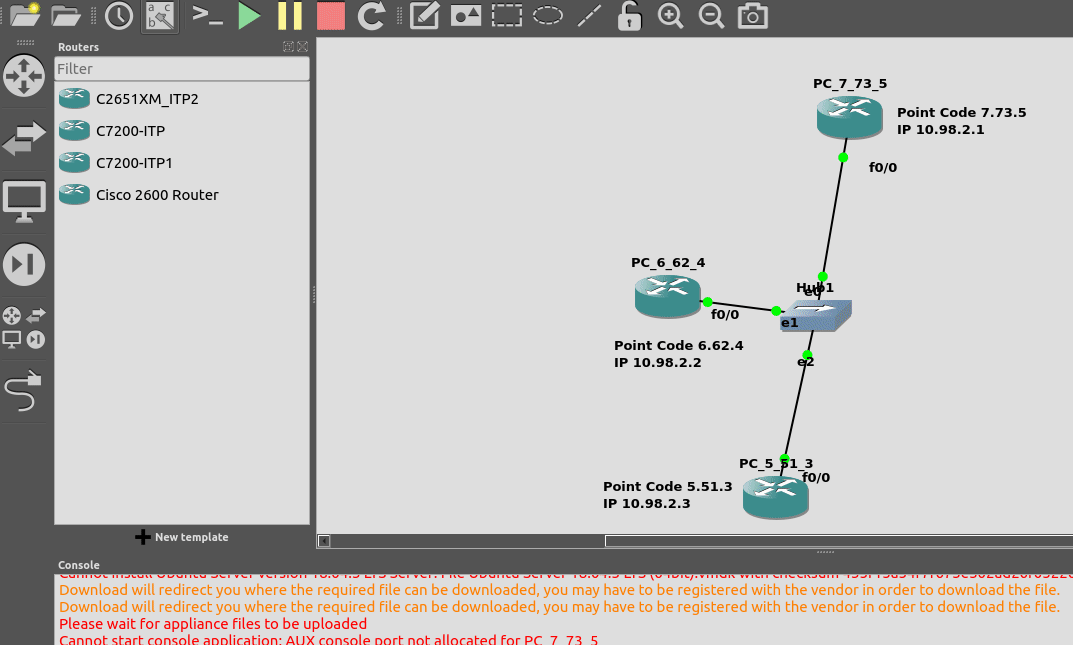
From inside GNS3, we’ll create a new template as per the Gif below.
You will need a copy of the software image to load in. If you’ve got software entitlements you should be able to download it, the filename of the image I’m using for the 7200 series is c7200-itpk9-mz.124-15.SW.bin and if you go searching, you should find it.
Now we can start building networks with our Cisco STPs!
What we’re going to achieve
In this lab we’re going to introduce the basics of setting up STPs using Sigtran (SS7 over IP).
If you follow along, by the end of this post you should have two STPs talking Sigtran based SS7 to each other, and be able to see the SS7 packets in Wireshark.
As we touched on in the last post, there’s a lot of different flavours and ways to implement SS7 over IP. For this post, we’re going to use M2PA (MTP2 Peer Adaptation Layer) to carry the MTP2 signaling, while MTP3 and higher will look the same as if it were on a TDM link. In a future post we’ll better detail the options here, the strengths and weaknesses of each method of transporting SS7 over IP, but that’s future us’ problem.
IP Connectivity
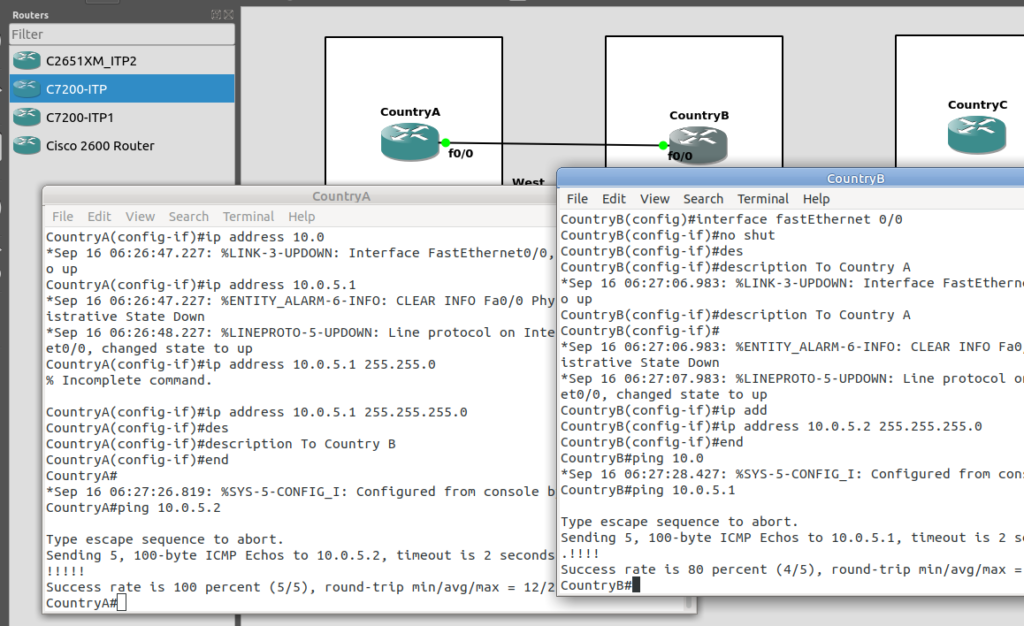
As we don’t have any TDM links, we’re going to do everything on IP, this means we have to setup the IP layer, before we can add any SS7/Sigtran stuff on top, so we’re going to need to get basic IP connectivity going between our Cisco STPs.
So for this we’ll need to set an IP Address on an interface, unshut it, link the two STPs. Once we’ve confirmed that we’ve got IP connectivity running between the two, we can get started on the Sigtran / SS7 side of things.
Let’s face it, if you’re reading this, I’m going to bet that you are probably aware of how to configure a router interface.
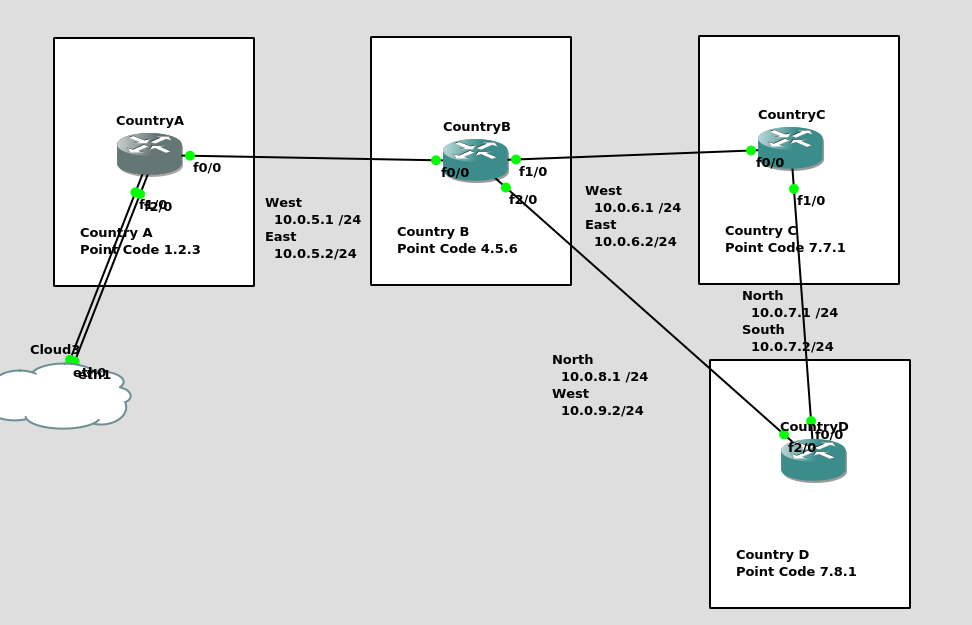
I’ve put a simple template down in the background to make a little more sense, which I’ve attached here if you want to follow along with the same addressing, etc.
So we’ll configure all the routers in each country with an IP – we don’t need to configure IP routing. This means adjacent countries with a direct connection between them should be able to ping each other, but separated countries shouldn’t be able to.
So now we’ve got IP connectivity between two countries, let’s get Sigtran / SS7 setup!
First we’ll need to define the basics, from configure-terminal in each of the Cisco STPs. We’ll need to set the SS7 variant (We’ll use ITU variant as we’re simulating international links), the network-indicator (This is an International network, so we’ll use that) and the point code for this STP (From the background image).
CountryA(config)#cs7 variant itu
CountryA(config)#cs7 network-indicator international
CountryA(config)#cs7 point-code 1.2.3
Repeat this step on Country A and Country B.
Next we’ll define a local peer on the STP. This is an instance of the Sigtran stack along with the port we’ll be listening on. Our remote peer will need to know this value to bring up the connection, the number specified is the port, and the IP is the IP it will bind on.
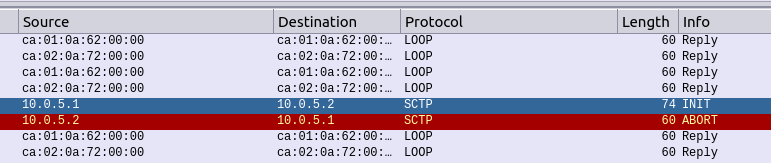
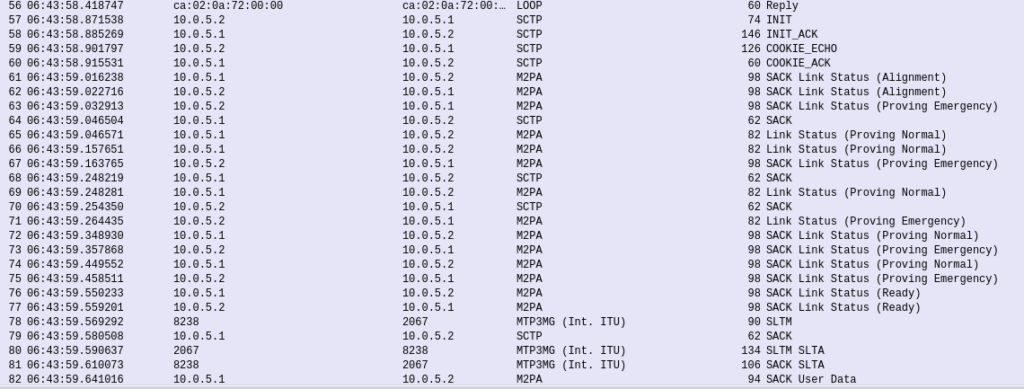
If you’re still sniffing the traffic between Country A and Country B, you should see our SS7 connection come up.
Wireshark trace of the connection coming up
The conneciton will come up layer-by-layer, firstly you’ll see the transport layer (SCTP) bring up an SCTP association, then MTP2 Peer Adaptation Layer (M2PA) will negotiate up to confirm both ends are working, then finally you’ll see MTP3 messaging.
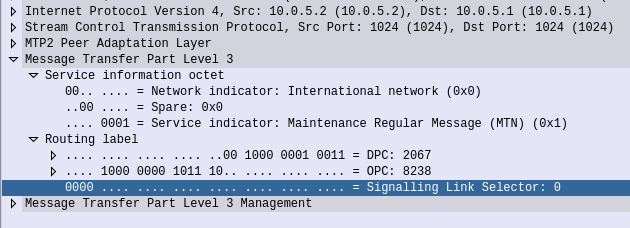
If we open up an MTP3 packet you can see our Originating and Destination Point Codes.
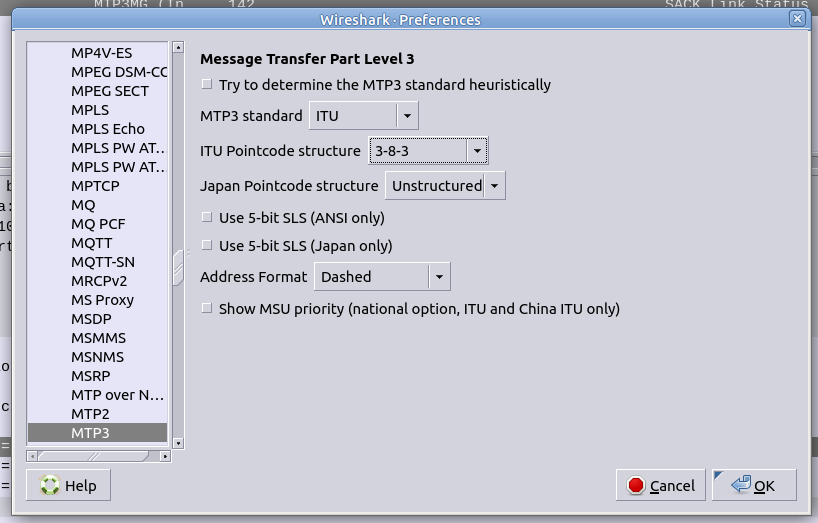
Notice in Wireshark the Point Codes don’t show up as 1-2-3, but rather 2067? That’s because they’re formatted as Decimal rather than 14 bit, this handy converter will translate them for you, or you can just change your preference in Wireshark’s decoders to use the matching ITU POint Code Structure.
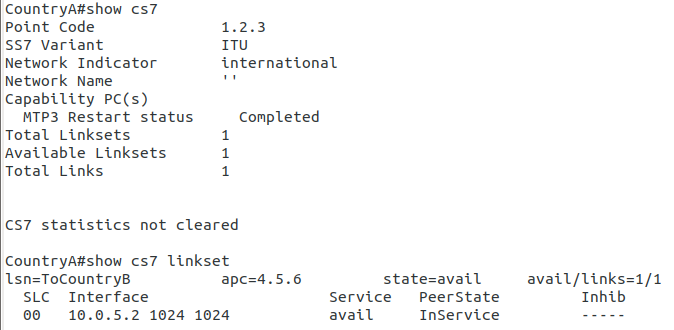
From the CLI on one of the two country STPs we can run some basic commands to view the status of all SS7 components and Linksets.
And there you have it! Basic SS7 connectivity!
There is so much more to learn, and so much more to do! By bringing up the link we’ve barely scratched the surface here.
Some homework before the next post, link all the other countries shown together, with Country D having a link to Country C and Country B. That’s where we’ll start in the lab – Tip: You’ll find you’ll need to configure a new cs7 local-peer for each interface, as each has its own IP.
This is part of a series of posts looking into SS7 and Sigtran networks. We cover some basic theory and then get into the weeds with GNS3 based labs where we will build real SS7/Sigtran based networks and use them to carry traffic.
So one more step before we actually start bringing up SS7 / Sigtran networks, and that’s to get a bit of a closer look at what components make up SS7 networks.
Recap: What is SS7?
SS7 is the name given to the protocol stack used almost exclusively in the telecommunications space. SS7 isn’t just one protocol, instead it is a suite of protocols. In the same way when someone talks about IP networking, they’re typically not just talking about the IP layer, but the whole stack from transport to application, when we talk about an SS7 network, we’re talking about the whole stack used to carry messages over SS7.
And what is SIGTRAN?
Sigtran is “Signaling Transport”. Historically SS7 was carried over TDM links (Like E1 lines).
As the internet took hold, the “Signaling Transport” working group was formed to put together the standards for carrying SS7 over IP, and the name stuck.
I’ve always thought if I were to become a Mexican Wrestler (which is quite unlikely), my stage name would be DSLAM, but SIGTRAN comes a close second.
Today when people talk about SIGTRAN, they mean “SS7 over IP”.
What is in an SS7 Network?
SS7 Networks only have 3 types of network elements:
Service Switching Points (SSP)
Service Transfer Points (STP)
Service Control Points (SCP)
Service Switching Points (SSP)
Service Switching Points (SSPs) are endpoints in the network. They’re the users of the connectivity, they use it to create and send meaningful messages over the SS7 network, and receive and process messages over the SS7 network.
Like a PC or server are IP endpoints on an IP Network, which send and receive messages over the network, an SSP uses the SS7 network to send and receive messages.
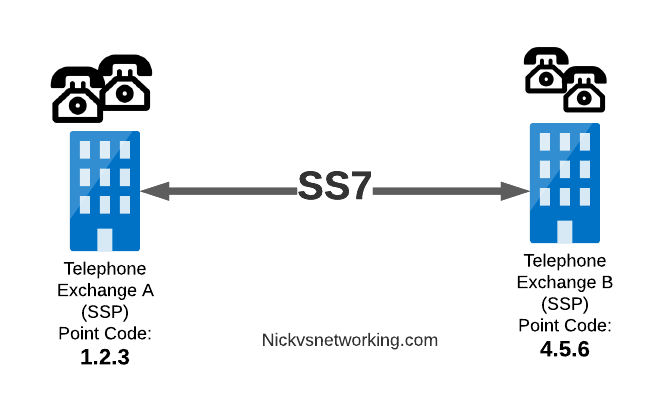
In a PSTN context, your local telephone exchange is most likely an SS7 Service Switching Point (SSP) as it creates traffic on the SS7 network and receives traffic from it.
A call from a user on one exchange to a user on another exchange could go from the SSP in Exchange A, to the SSP in Exchange B, in the same way you could send data between two computers by connecting directly between them with an Ethernet crossover cable.
Messages between our two exchanges are addressed using Point Codes, which can be thought of a lot like IP Addresses, except shorter.
In the MTP3 header of each SS7 message is the Destination Point Code, and the Origin Point Code.
When Telephone Exchange A wants to send a message over SS7 to Telephone Exchange B, the MTP header would look like:
MTP3 Header:
Origin Point Code: 1.2.3
Destination Point Code: 4.5.6
Service Transfer Points (STP)
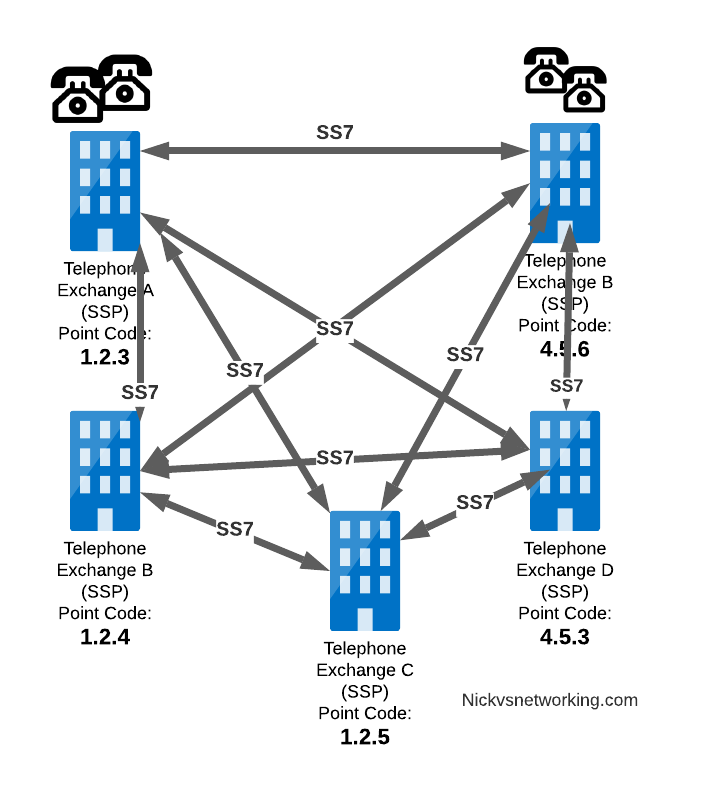
Linking each SSP to each other SSP has a pretty obvious problem as our network grows.
What happens if we’ve got hundreds of SSPs? If we want a full-mesh topology connecting every SSP to every other SSP directly, we’d have a rats nest of links!
A “full-mesh” approach for connecting SSPs does not work at scale, so STPs are introduced
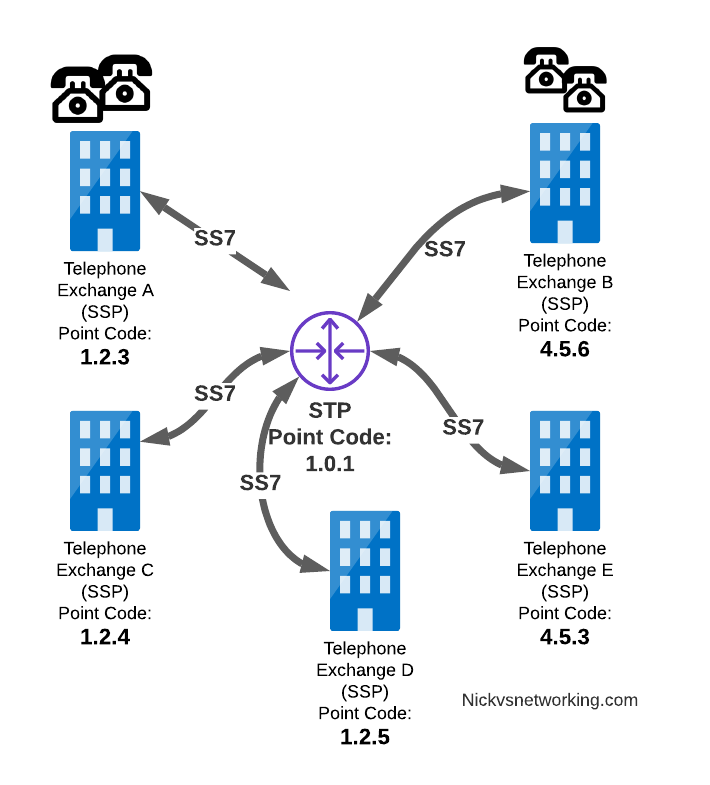
So to keep things clean and scalable, we’ve got Signalling Transfer Points (STPs).
STPs can be thought of like Routers but in an SS7 network.
When our SSP generates an SS7 message, it’s typically handed to an STP which looks at the Destination Point Code, it’s own routing table and routes it off to where it needs to go.
STP acting as a central router to connect lots of SSPs
This means every SSP doesn’t require a connection to every other SSP. Instead by using STPs we can cut down on the complexity of our network.
When Telephone Exchange A wants to send a message over SS7 to Telephone Exchange B, the MTP header would look the same, but the routing table on Telephone Exchange A would be setup to send the requests out the link towards the STP.
MTP3 Header:
Origin Point Code: 1.2.3
Destination Point Code: 4.5.6
Linksets
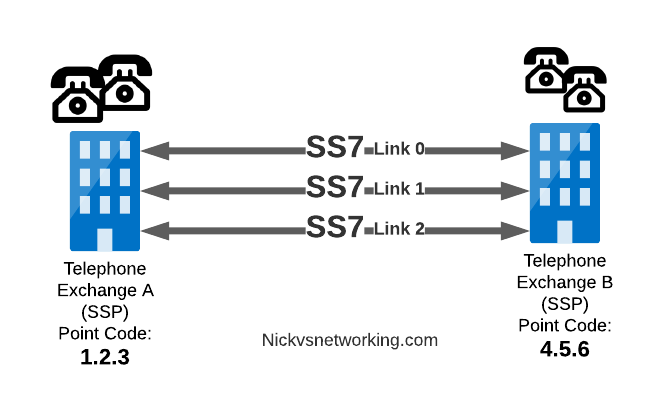
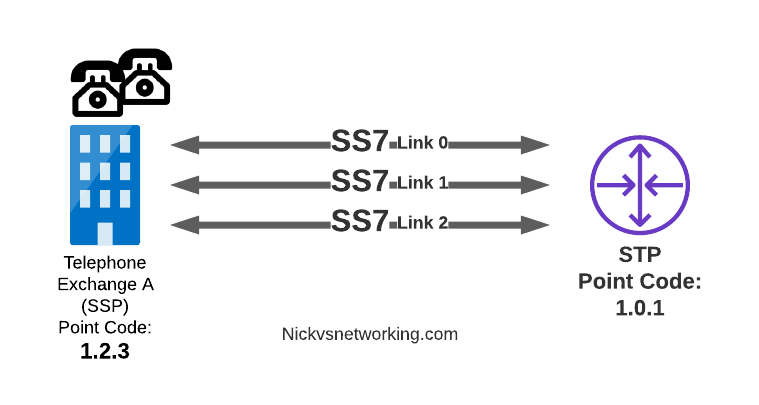
Between SS7 Nodes we have Linksets. Think of Linksets as like LACP or Etherchannel, but for SS7.
You want to have multiple links on every connection, for sharing out the load or for redundancy, and a Linkset is a group of connections from one SS7 node to another, that are logically treated as one link.
Link between an SSP and STP with 3 linksets
Each of the links in a Linkset is identified by a number, and specified in in the MTP3 header’s “Signaling Link Selector” field, so we know what link each message used.
MTP3 Header:
Origin Point Code: 1.2.3
Destination Point Code: 4.5.6
Signaling Link Selector: 2
Service Control Point (SCP)
Somewhere between a Rolodex an relational database, is the Service Control Point (SCP).
For an exchange (SSP) to route a call to another exchange, it has to know the point code of the destination Exchange to send the call to. When fixed line networks were first deployed this was fairly straight forward, each exchange had a list of telephone number prefixes and the point code that served each prefix, simple.
But then services like number porting came along when a number could be moved anywhere. Then 1800/0800 numbers where a number had to be translated back to a standard phone number entered the picture.
To deal with this we need a database, somewhere an SSP can go to query some information in a database and get a response back.
This is where we use the Service Control Point (SCP).
Keep in mind that SS7 long predates APIs to easily lookup data from a service, so there was no RESTful option available in the 1980s.
When a caller on a local exchange calls a toll free (1800 or 0800 number depending on where you are) number, the exchange is setup with the Point Code of an SCP to query with the toll free number, and the SCP responds back with the local number to route the call to.
While SCPs are fading away in favor of technology like DNS/ENUM for Local Number Portability or Routing Databases, but they are still widely used in some networks.
Getting to know the Signalling Transfer Point (STP)
As we saw earlier, instead of a one-to-one connection between each SS7 device to every other SS7 device, Signaling Transfer Points (STP) are used, which act like routers for our SS7 traffic.
The STP has an internal routing table made up of the Point Codes it has connections to and some logic to know how to get to each of them.
Like a router, STPs don’t really create SS7 traffic, or consume traffic, they just receive SS7 messages and route them on towards their destination.
Ok, they do create some traffic for checking links are up, etc, but like a router, their main job is getting traffic where it needs to go.
When an STP receives an SS7 message, the STP looks at the MTP3 header. Specifically the Destination Point Code, and finds if it has a path to that Point Code. If it has a route, it forwards the SS7 message on to the next hop.
Like a router, an STP doesn’t really concern itself with anything higher than the MTP3 layer – As point codes are set in the MTP3 layer that’s the only layer the STP looks at and the upper layers aren’t really “any of its business”.
STPs don’t require a direct connection (Linkset) from the Originating Point Code straight to the Destination Point Code. Just like every IP router doesn’t need a direct connection to ever other network. By setting up a routing table of Point Codes and Linksets as the “next-hop”, we can reach Destination Point Codes we don’t have a direct Linkset to by routing between STPs to reach the final Destination Point Code.
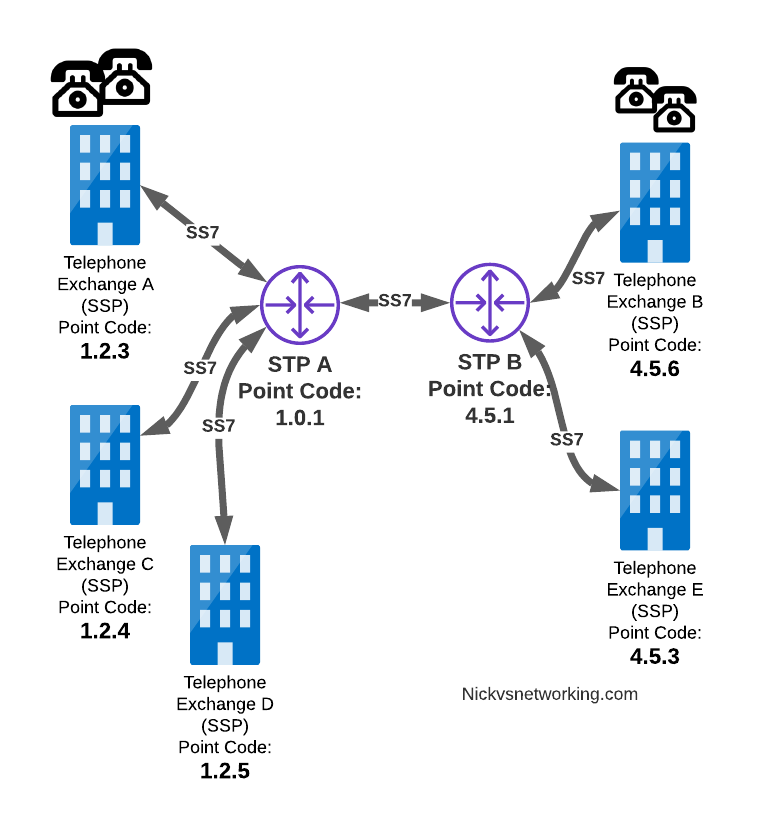
Let’s work through an example:
And let’s look at the routing table setup on STP-A:
STP A Routing Table:
1.2.3 - Directly attached (Telephone Exchange A)
1.2.4 - Directly attached (Telephone Exchange C)
1.2.5 - Directly attached (Telephone Exchange D)
4.5.1 - Directly attached (STP-B)
4.5.3 - Via STP-B
4.5.6 - Via STP-B
So what happens when Telephone Exchange A (Point Code 1.2.3) wants to send a message to Telephone Exchange E (Point Code 4.5.3)? Firstly Telephone Exchange A puts it’s message on an MTP3 payload, and the MTP3 header will look something like this:
MTP3 Header:
Origin Point Code: 1.2.3
Destination Point Code: 4.5.3
Signaling Link Selector: 1
Telephone Exchange A sends the SS7 message to STP A, which looks at the MTP3 header’s Destination Point Code (4.5.3), and then in it’s routing table for a route to the destination point. We can see from our example routing table that STP A has a route to Destination Point Code 4.5.3 via STP-B, so sends it onto STP-B.
For STP-B it has a direct connection (linkset) to Telephone Exchange E (Point Code 4.5.3), so sends it straight on
Like IP, Point Codes have their own form of Variable-Length-Subnet-Routing which means each STP doesn’t need full routing info for every Destination Point Code, but instead can have routes based on part of the point code and a subnet mask.
But unlike IP, there is no BGP or OSPF on SS7 networks. Instead, all routes have to be manually specified.
For STP A to know it can get messages to destinations starting with 4.5.x via STP B, it needs to have this information manually added to it’s route table, and the same for the return routing.
Sigtran & SS7 Over IP
As the world moved towards IP enabled everything, TDM based Sigtran Networks became increasingly expensive to maintain and operate, so a IETF taskforce called SIGTRAN (Signaling Transport) was created to look at ways to move SS7 traffic to IP.
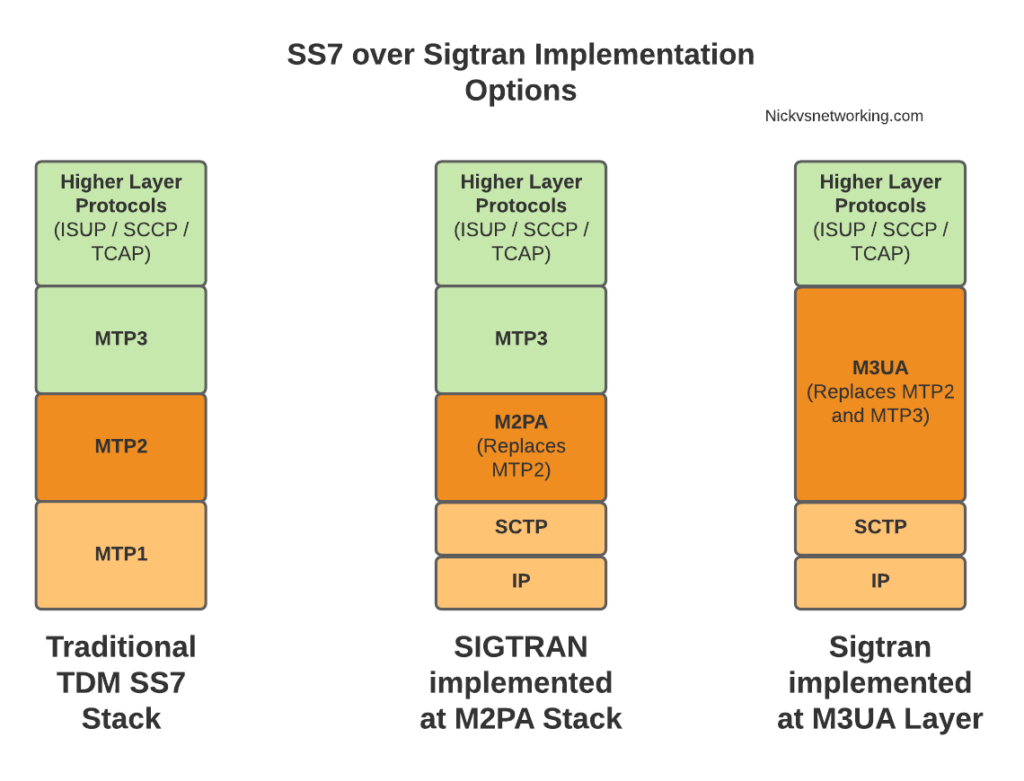
When moving SS7 onto IP, the first layer of SS7 (MTP1) was dropped, as it primarily concerned the physical side of the network. MTP2 didn’t really fit onto an IP model, so a two options were introduced for transport of the MTP2 data, M2PA (Message Transfer Part 2 User Peer-to-Peer Adaptation Layer) and M2UA (MTP2 User Adaptation Layer) were introduced, which rides on top of SCTP. This means if you wanted an MTP2 layer over IP, you could use M2UA or M2TP.
SCTP is neither TCP or UDP. I’ve touched upon SCTP on this blog before, it’s as if you took the best bits of TCP without the issues like head of line blocking and added multi-homing of connections.
So if you thought all the layers above MTP2 are just transferred, unchanged on top of our M2PA layer, that’s one way of doing it, however it’s not the only way of doing it.
There are quite a few ways to map SS7 onto IP Networks, which we’ll start to look into it more detail, but to keep it simple, for the next few posts we’ll be assuming that everything above MTP2/M2PA remain unchanged.
In the next post, we’ll get some actual SS7 traffic flowing!
This is part of a series of posts looking into SS7 and Sigtran networks. We cover some basic theory and then get into the weeds with GNS3 based labs where we will build real SS7/Sigtran based networks and use them to carry traffic.
If you use a mobile phone, a VoIP system or a copper POTS line, there’s a high chance that somewhere in the background, SS7 based signaling is being used.
The signaling for GSM, UMTS and WCDMA mobile networks all rely on SS7 based signaling, and even today the backbone of most PSTN traffic relies SS7 networks. To many this is mysterious carrier tech, and as such doesn’t get much attention, but throughout this series of posts we’ll take a hands-on approach to putting together an SS7 network using GNS3 based labs and connect devices through SS7 and make some stuff happen.
Overview of SS7
Signaling System No. 7 (SS7/C7) is the name for a family of protocols originally designed for signaling between telephone switches. In plain English, this means it was used to setup and teardown large volumes of calls, between exchanges or carriers.
When carrier A and Carrier B want to send calls between each other, there’s a good chance they’re doing it over an SS7 Network.
But wait! SIP exists and is very popular, why doesn’t everyone just use SIP? Good question, imaginary asker. The answer is that when SS7 came along, SIP was still almost 25 years away from being defined. Yes. It’s pretty old.
SS7 isn’t one protocol, but a family of protocols that all work together – A “protocol stack”. The SS7 specs define the lower layers and a choice of upper layer / application protocols that can be carried by them.
The layered architecture means that the application layer at the top can be changed, while the underlying layers are essentially the same.
This means while SS7’s original use was for setting up and tearing down phone calls, this is only one application for SS7 based networks. Today SS7 is used heavily in 2G/3G mobile networks for connectivity between core network elements in the circuit-switched domain, for international roaming between carriers and services like Local Number Portability and Toll Free numbers.
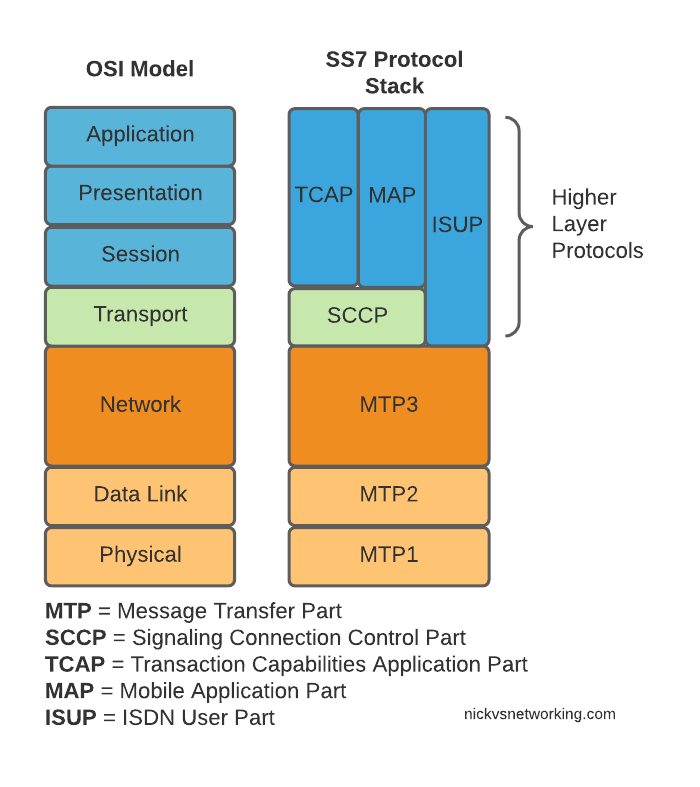
Here’s the layers of SS7 loosely mapped onto the OSI model (SS7 predates the OSI model as well):
OSI Model (Left) and SS7 Protocol Stack (Right)
We do have a few layers to play with here, and we’ll get into them all in depth as we go along, but a brief introduction to the underlying layers:
MTP 1 – Message Transfer Part 1
This is our physical layer. In this past this was commonly E1/T1 lines.
It’s responsible for getting our 1s and 0s from one place to another.
MTP 2 – Message Transfer Part 2
MTP2 is responsible for the data link layer, handling reliable transfer of data, in sequence.
MTP 3 – Message Transfer Part 3
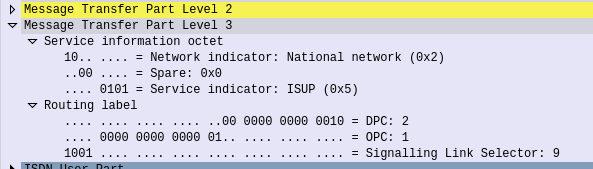
The MTP3 header contains an Originating and a Destination Point Code.
These point codes can be thought of as like an IP Address; they’re used to address the source and destination of a message. A “Point Code” is the unique address of a SS7 Network element.
MTP3 header showing the Destination Point Code (DPC) and Origin Point Code (OPC) on a National Network, carrying ISUP traffic
Every message sent over an SS7 network will contain an Origin Point Code that identifies the sender, and a Destination Point Code that identifies the intended recipient.
This is where we’ll bash around at the start of this course, setting up Linksets to allow different devices talking to each other and addressing each other via Point Codes.
The MTP3 header also has a Service Indicator flag that indicates what the upper layer protocol it is carrying is, like the Protocol indicator in IPv4/IPv6 headers.
A Signaling Link Selector indicates which link it was transported over (did I mention we can join multiple links together?), and a Network Indicator for determining if this is signaling is at the National or International level.
TUP/MAP/SCCP/ISUP
These are the “higher-layer” protocols. Like FTP sits on top of TCP/IP, a SS7 network can transport these protocols from their source to their destination, as identified by the Origin Point Code (OPC), to the Destination Point Code (DPC), as specified in the MTP3 header.
We’ll touch on these protocols more as we go on. SCCP has it’s own addressing on top of the OPC/DPC (Like IP has IP Addressing, but TCP has port numbers on top to further differentiate).
Why learn SS7 today?
SS7 and SIGTRAN are still widely in use in the telco world, some of it directly, other parts derived / evolved from it.
So stick around, things are about to get interesting!
To support Dedicated Bearers we first have to have a way of profiling the traffic, to classify the traffic as being the type we want to provide the Dedicated Bearer for.
The first step involves a request from an Application Function (AF) to the PCRF via the Rx interface.
The most common type of AF would be a P-CSCF. When a VoLTE call gets setup the P-CSCF requests that a dedicated bearer be setup for the IP Address and Ports involved in the VoLTE call, to ensure users get the best possible call quality.
But Application Functions aren’t limited to just VoLTE – You could also embed an Application Function into the server for an online game to enable a dedicated bearer for users playing that game, or a sports streaming app that detects when a user starts streaming sports and creates a dedicated bearer for that user to send the traffic down.
The request to setup a dedicated bearer comes in the form of a Diameter request message from the AF, using the Rx reference point, typically from the P-CSCF to the PCRF in the network in an “AA-Request”.
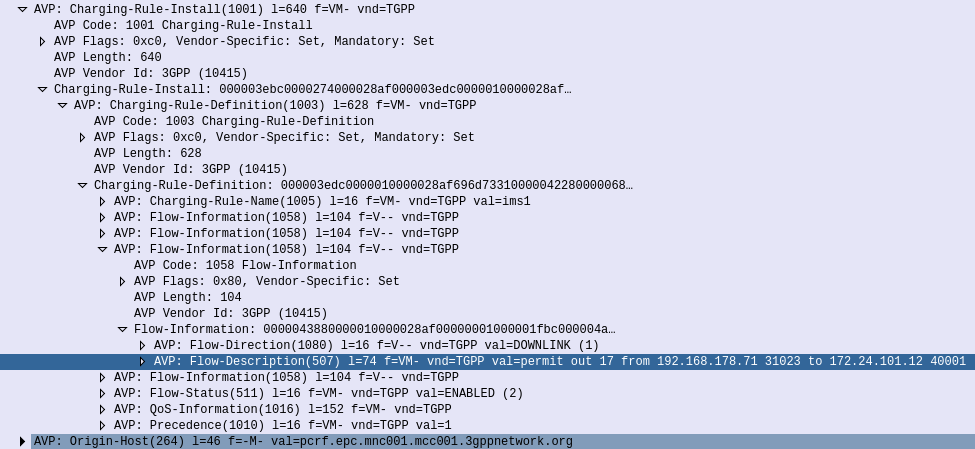
Of main interest in the AA-Request is the Media Component AVP, that contains all the details needed to identify the traffic flow.
Now our PCRF is in charge of policy, and know which P-GW is serving the required subscriber. So the PCRF takes this information and sends a Gx Re-Auth Request to the PCEF in the P-GW serving the subscriber, with a Charging Rule the PCEF in the P-GW needs to install, to profile and apply QoS to the bearer.
Charging Rule Definition’s Flow-Information AVPs showing the information needed to profile the traffic
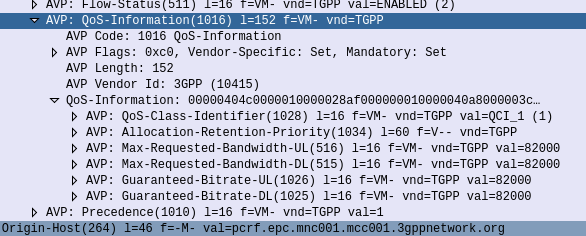
The QoS Description AVP defines which QoS parameters (QCI / ARP / Guaranteed & Maximum Bandwidth) should be applied to the traffic that matches the rules we just defined.
QoS Information AVP showing requested QoS Parameters
The P-GW sends back a Gx Re-Auth Answer, and gets to work actually setting up these bearers.
With the rule installed on the PCEF, it’s time to get this new bearer set up on the UE / eNodeB.
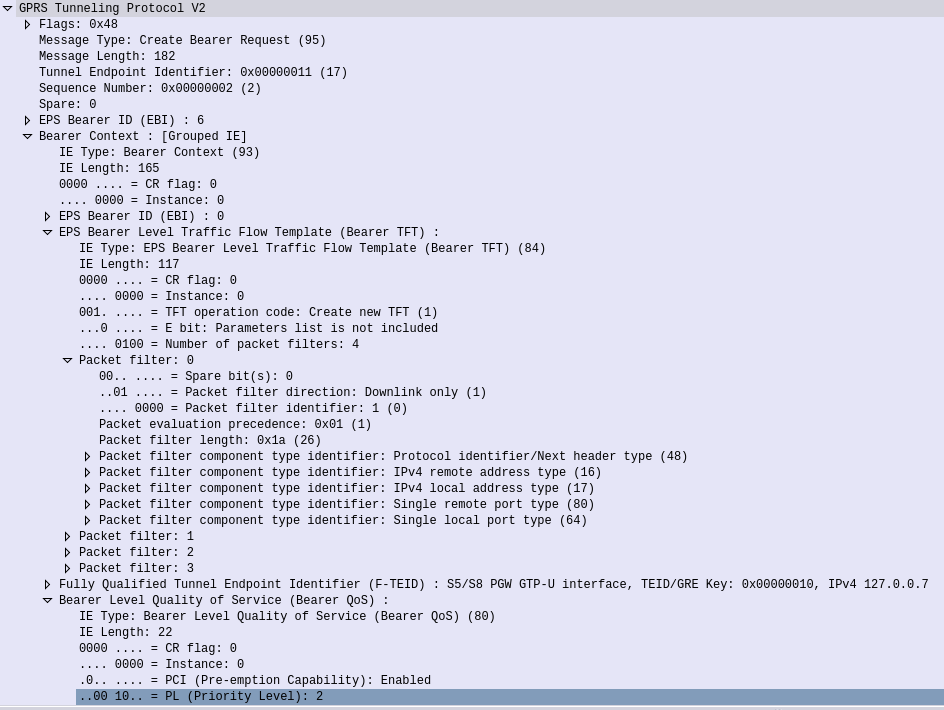
The P-GW sends a GTPv2 “Create Bearer Request” to the S-GW which forwards it onto the MME, to setup / define the Dedicated Bearer to be setup on the eNodeB.
GTPv2 “Create Bearer Request” sent by the P-Gw to the S-GW forwarded from the S-GW to the MME
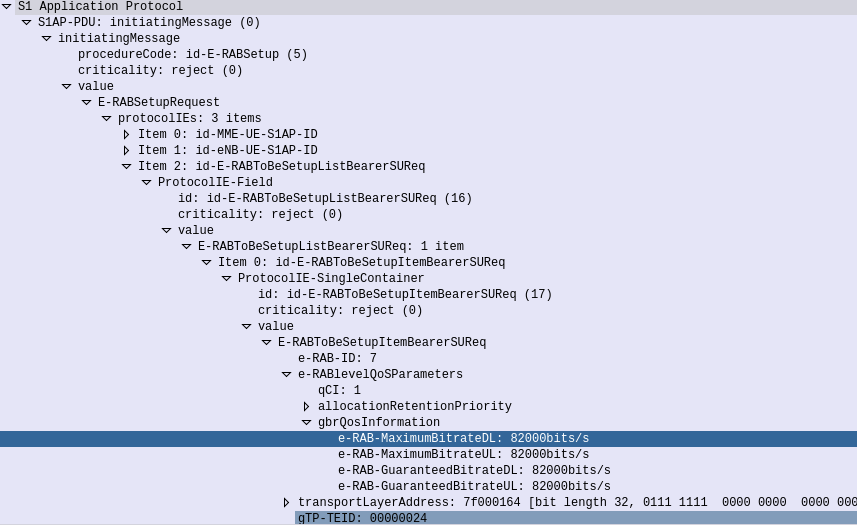
The MME translates this into an S1 “E-RAB Setup Request” which it sends to the eNodeB to setup,
S1 E-RAB Setup request showing the E-RAB to be setup
Assuming the eNodeB has the resources to setup this bearer, it provides the details to the UE and sets up the bearer, sending confirmation back to the MME in the S1 “E-RAB Setup Response” message, which the MME translates back into GTPv2 for a “Create Bearer Response”
All this effort to keep your VoLTE calls sounding great!
So I’ve been waxing lyrical about how cool in the NRF is, but what about how it’s secured?
A matchmaking service for service-consuming NFs to find service-producing NFs makes integration between them a doddle, but also opens up all sorts of attack vectors.
Theoretical Nasty Attacks (PoC or GTFO)
Sniffing Signaling Traffic: A malicious actor could register a fake UDR service with a higher priority with the NRF. This would mean UDR service consumers (Like the AUSF or UDM) would send everything to our fake UDR, which could then proxy all the requests to the real UDR which has a lower priority, all while sniffing all the traffic.
Stealing SIM Credentials: Brute forcing the SUPI/IMSI range on a UDR would allow the SIM Card Crypto values (K/OP/Private Keys) to be extracted.
Sniffing User Traffic: A dodgy SMF could select an attacker-controlled / run UPF to sniff all the user traffic that flows through it.
Obviously there’s a lot more scope for attack by putting nefarious data into the NRF, or querying it for data gathering, and I’ll see if I can put together some examples in the future, but you get the idea of the mischief that could be managed through the NRF.
This means it’s pretty important to secure it.
OAuth2
3GPP selected to use common industry standards for HTTP Auth, including OAuth2 (Clearly lessons were learned from COMP128 all those years ago), however OAuth2 is optional, and not integrated as you might expect. There’s a little bit to it, but you can expect to see a post on the topic in the next few weeks.
3GPP Security Recommendations
So how do we secure the NRF from bad actors?
Well, there’s 3 options according to 3GPP:
Option 1 – Mutual TLS
Where the Client (NF) and the Server (NRF) share the same TLS info to communicate.
This is a pretty standard mechanism to use for securing communications, but the reliance on issuing certificates and distributing them is often done poorly and there is no way to ensure the person with the certificate, is the person the certificate was issued to.
3GPP have not specified a mechanism for issuing and securely distributing certificates to NFs.
Option 2 – Network Domain Security (NDS)
Split the network traffic on a logical level (VLANs / VRFs, etc) so only NFs can access the NRF.
Essentially it’s logical network segregation.
Option 3 – Physical Security
Split the network like in NDS but a physical layer, so the physical cables essentially run point-to-point from NF to NRF.
NRF and NF shall authenticate each other during discovery, registration, and access token request. If the PLMN uses protection at the transport layer as described in clause 13.1, authentication provided by the transport layer protection solution shall be used for mutual authentication of the NRF and NF. If the PLMN does not use protection at the transport layer, mutual authentication of NRF and NF may be implicit by NDS/IP or physical security (see clause 13.1). When NRF receives message from unauthenticated NF, NRF shall support error handling, and may send back an error message. The same procedure shall be applied vice versa. After successful authentication between NRF and NF, the NRF shall decide whether the NF is authorized to perform discovery and registration. In the non-roaming scenario, the NRF authorizes the Nnrf_NFDiscovery_Request based on the profile of the expected NF/NF service and the type of the NF service consumer, as described in clause 4.17.4 of TS23.502 [8].In the roaming scenario, the NRF of the NF Service Provider shall authorize the Nnrf_NFDiscovery_Request based on the profile of the expected NF/NF Service, the type of the NF service consumer and the serving network ID. If the NRF finds NF service consumer is not allowed to discover the expected NF instances(s) as described in clause 4.17.4 of TS 23.502[8], NRF shall support error handling, and may send back an error message. NOTE 1: When a NF accesses any services (i.e. register, discover or request access token) provided by the NRF , the OAuth 2.0 access token for authorization between the NF and the NRF is not needed.
TS 133 501 – 13.3.1 Authentication and authorization between network functions and the NRF
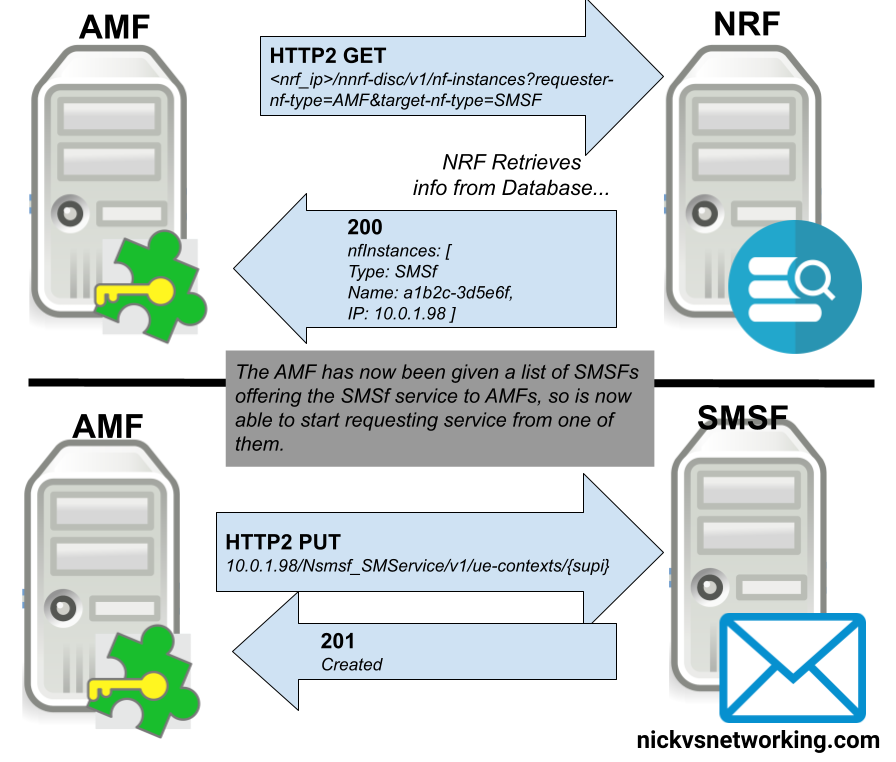
The Network Repository Function plays matchmaker to all the elements in our 5G Core.
For our 5G Service-Based-Architecture (SBA) we use Service Based Interfaces (SBIs) to communicate between Network Functions. Sometimes a Network Function acts as a server for these interfaces (aka “Service Producer”) and sometimes it acts as a client on these interfaces (aka “Service Consumer”).
For service consumers to be able to find service producers (Clients to be able to find servers), we need a directory mechanism for clients to be able to find the servers to serve their needs, this is the role of the NRF.
With every Service Producer registering to the NRF, the NRF has knowledge of all the available Service Producers in the network, so when a Service Consumer NF comes along (Like an AMF looking for UDM), it just queries the NRF to get the details of who can serve it.
Basic Process – NRF Registration
In order to be found, a service producer NF has to register with the NRF, so the NRF has enough info on the service-producer to be able to recommend it to service-consumers.
This is all the basic info, the Service Based Interfaces (SBIs) that this NF serves, the PLMN, and the type of NF.
The NRF then stores this information in a database, ready to be found by SBI Service Consumers.
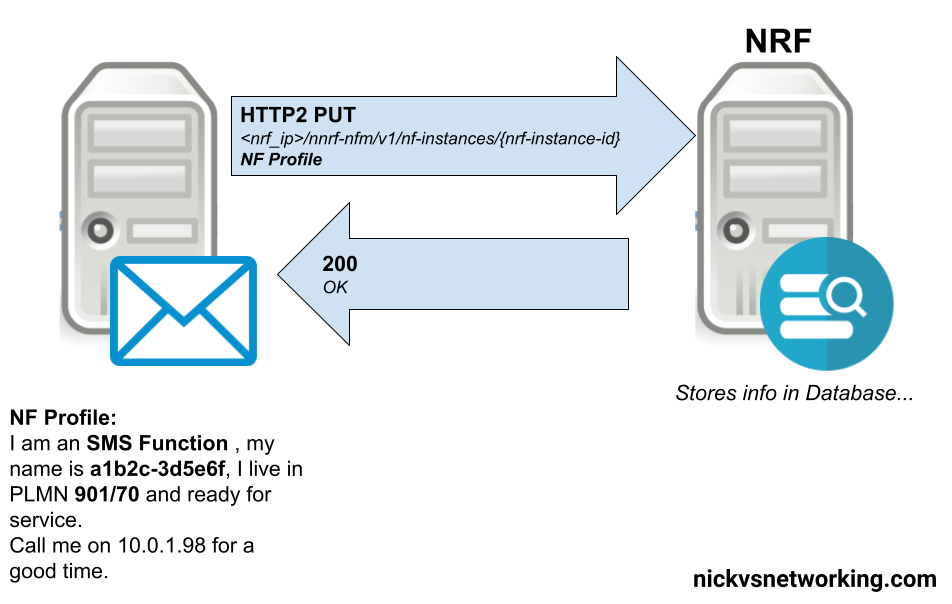
This is achieved by the Service Producing NF sending a HTTP2 PUT to the NRF, with the message body containing all the particulars about the services it offers.
Simplified example of an SMSc registering with the NRF in a 5G Core
Basic Process – NRF Discovery
With an NRF that has a few SBI Service Producers registered in it, we can now start querying it from SBI Service Consumers, to find SBI Service Producers.
The SBI Service Consumer looking for a SBI Service Producer, queries the NRF with a little information about itself, and the SBI Service Producer it’s looking for.
For example a SMF looking for a UDM, sends a request like:
SMS by default uses the GSM-7 bit alphabet, thanks to the fact each letter is only 7 bits long, this means you can cram 160 characters into a 140 byte message body.
However, this 7-bit alphabet is, well, limited, because it’s 7 bits long it means we can only have 128 different combinations of these bits, or to put it another way, with only 128 different unique combinations of these bits, we can only define 128 characters.
You have the standard 26 latin alphabet characters that Sesame Street drilled into you, some characters with accents, digits, and a limited set of symbols.
The GSM 7 bit alphabet does not include is character sets and symbols common for non-English written languages.
Shift Tables
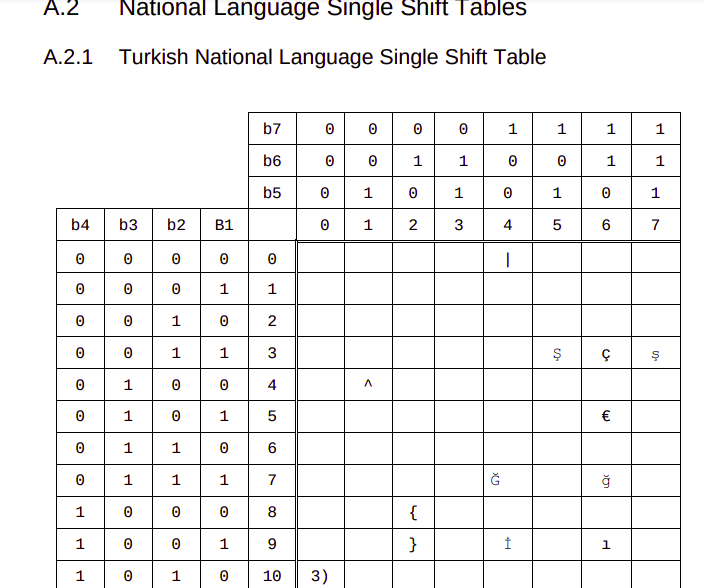
To deal with this 3GPP introduced “National Language Shift Tables”, which are enable a sort of find-and-replace approach to the 7-bit alphabet, where certain characters that are unused in one alphabet, take the value of characters from the local alphabet.
So if you want to send the character Ğ (Found in the Turkish and Azerbaijani alphabets) you’d select the Turkish language Shift table, that replaces the capital G (71) with Ğ.
Of course you need to have two things to do this, you need the Language Shift Table to tell you what local-language letters replace what default letters, and a mechanism to state that you’re using a language shift table.
3GPP define the National Language Shift tables in TS 23.038, where you can lookup the character you want to encode, so you know what 7 bit value it uses, for example our character Ğ is 1000111 in the 7-bit alphabet.
Next we need to indicate that we don’t want 1000111 in the 7-bit alphabet to be rendered as “G”, we want to use the “Turkish National Language Single Shift Table” which will render it as “Ğ”. We do this in the User Data Header of the SMS Body, the same way we’d indicate that an SMS is a concatenated SMS.
But by adding a header in the User Data Header of the SMS Body, we eat into the space we can use to send the message body, with a single User Data Header indicating that the Turkish National Language Single Shift Table is being used, we go from a maximum of 160 characters without the User Data Header, to 134 characters.
I’ve shared a lot more information on the User Data Header in this post on Concatenated SMS, should you be interested.
No matter how many shift tables you define, you’re not going to cover all of these in a 7-bit alphabet.
So all this encoding falls to 💩 when someone adds an Emoji.
The “😀” Emoji, represented as U+1F600 in Unicode, can be encoded as 0xF09F9880 in UTF-8 or 0xD83DDE00 in UTF-16.
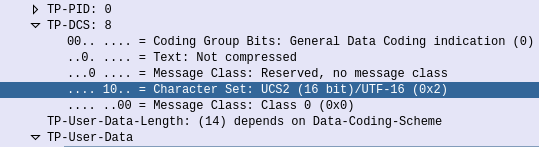
So in 3GPP Networks, when you need more than 128 characters to work with, and when shift tables won’t cut the mustard, you can change the encoding used to use the International Standards Organisations’ “Universal coded character set 2” (UCS-2).
Unfortunately UCS-2 never really took off, but luckily it overlaps with UTF-16 character set, which is a lot more common.
So if you’ve got a “😀” Emoji in your SMS body the encoding of the message will be changed from GSM-7 to use a different encoding -UTF-16 / UCS2.
SMS Body showing TP-DCS character set is UCS2 / UTF-16 as Emojis are present
There’s a catch here, if you’re moving from a 7-bit alphabet to a 16 bit alphabet, you’re going to have a lot less space to work with.
A single SMS contains 1120 bits for the user data (The actual message).
With GSM-7 bit encoding, each letter takes up 7 bits, so 1120÷7 gives us 160 characters.
With UTF-16/UCS2 encoding, each letter takes up 16 bits so 1120÷16 only give us 70 characters.
So what happens next?
Often when Emojis are used, as our message is now limited to 70 characters concatenated messages are used, which takes a further 8 bytes of our message body if concatenated messages are used, further limiting the message length.
You may find you need to move your Open5GS deployments from one server to another, or split them between servers. This post covers the basics of migrating Open5GS config and data between servers by backing up and restoring it elsewhere.
The Database
Open5GS uses MongoDB as the database for the HSS and PCRF. This database contains all our SDM data, like our SIM Keys, Subscriber profiles, PCC Rules, etc.
Backup Database
To backup the MongoDB database run the below command (It doesn’t need sudo / root to run):
mongodump -o Open5Gs_"`date +"%d-%m-%Y"`"
You should get a directory called Open5Gs_todaysdate, the files in that directory are the output of the MongoDB database.
Restore Database
If you copy the backup we just took (the directory named Open5Gs_todaysdate) to the new server, you can restore the complete database by running:
mongorestore Open5Gs_todaysdate
This restores everything in the database, including profiles and user accounts for the WebUI,
You may instead just restore the Subscribers table, leaving the Profiles and Accounts unchanged with:
The database schema used by Open5GS changed earlier this year, meaning you cannot migrate directly from an old database to a new one without first making a few changes.
But networks evolve, and 5G Networks required some extensions to GTP to support these on the N9 and N3 reference points. (UPF to UPF and UPF to gNodeB / Access Network).
3GPP TS 38.415 outlines the PDU session user plane protocol used in 5GC.
The Need for GTP Header Extensions
As increasingly complex QoS capabilities are introduced into 5GC, there is a need to signal certain information on a per-packet basis.
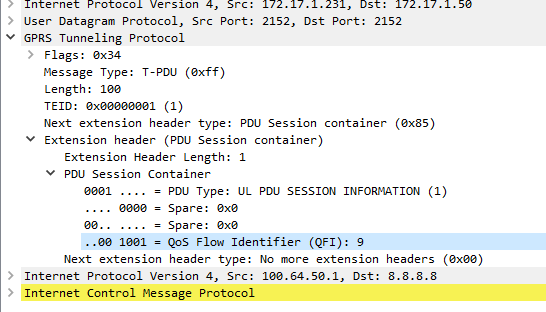
The expansion of QoS in 5GC means the UPF of gNodeB may need to set the QoS Flow Identifier per-packet, include delay measurements or signal that Reflective QoS is being used per packet, for this, you need to extend GTP.
Fortunately GTP has support for Extension Headers and this has been leveraged to add the PDU Session Container in the Extension Header of a GTP packet.
In here you can set on a per packet basis:
QoS Flow Identifier (QFI) – Used to identify the QoS flow to be used (Pretty self explanatory)
Reflective QoS Indicator (RQI) – To indicate reflective QoS is supported for the encapsulated packet
Paging Policy Presence (PPP) – To indicate support for Paging Policy Indicator (PPI)
Paging Policy Indicator (PPI) – Sets parameters of paging policy differentiation to be applied
QoS Monitoring Packet – Indicates packet is used for QoS Monitoring and DL & UL Timestamps to come
UL/DL Sending Time Stamps – 64 bit timestamp generated at the time the UPF or UE encodes the packet
UL/DL Received Time Stamps – 64 bit timestamp generated at the time the UPF or UE received the packet
UL/DL Delay Indicators – Indicates Delay Results to come
UL/DL Delay Results – Delay measurement results
Sequence Number Presence – Indicates if QFI sequence number to come
UL/DL QFI Sequence Number – Sequence number as assigned by the UPF or gNodeB
Most people think of 160 characters as the length of an SMS. But the payload is actually 140 bytes, but with better encoding 1 character doesn’t require 1 byte.
The above paragraph is exactly 160 characters. It would fit into a standard SMS.
By using the GSM 7 bit alphabet, you can cram 16 characters into 140 bytes (octets) of space, which is kind of cool.
140 bytes of data containing 160 characters of text
You’d think if you took a 160 character SMS, and concatenated it onto another 160 character SMS, you’d get a total of 320 characters, right (160+160=320)? Alas it’s not that simple.
In order to achieve the concatenation of messages in a way that’s transparent to the users (rather than a series of SMSes coming through one-after-the-ther) a User-Data Header (TP-User-Data-Header-Indicator aka TP-UHDI) is added to the TP-User Data of the TPDU (the part that actually contains the user message).
This User-Data Header takes up 7 bytes, which with GSM encoding robs us of 6 characters from the message length. (Not a typo, GSM7 encoding does not mean 1 character = 1 byte, hence we can get 160 characters into 140 bytes of space) So a two SMS concatenated message would only allow 268 characters to be sent (134 characters + 134 characters).
Let’s take a look at this header that’s robbing us of message length, but enabling us to concatenate messages.
For starters, the information about how many parts in the concatenated message, and what part number this one is, is located in the message body, hence robbing us of characters.
But we only know about the presence of this header being in the message body because the SMS-SUBMIT TPDU has the TP-UDHI flag (TP-User-Data-Header-Indicator) set, so we know the User Data is prefixed with the User-Data-Header.
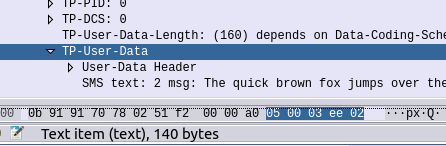
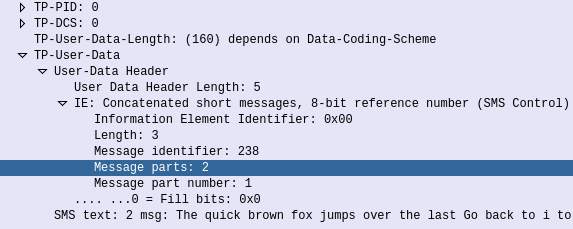
Now if we have a look in the TP-User-Data we can see the User-Data Header, this can actually carry a few different payloads, but in our case, it’s carrying the Concatenated Short Messages IE, which tells us the message identifier (unique per single-but-multi-part message, the number of parts in the message (in this case 2) and the part number this is (part 1 of 2).
First part of a two part SMS
Now the phone has indicated this is a multipart message, the length of the data is still 160, but the length of the actual message is now limited to 134 characters with GSM7 encoding.
The encoding isn’t as bad as you might expect: 1st byte indicates the total length of the User Data Headers (After this the actual user data begins), 2nd byte is the IE identifier, for Concatenated Short Messages, this is 00, 3rd byte is the length of the Concatenated Short Messages IE, 4th byte is the message identifier in hex, 5th byte is the number of message parts in hex (So up to 255 message parts) 6th byte is the message part number, to aid in putting it back together in order.
3GPP TS 23.040 – 9.2.3.24 TP-User Data (TP-UD) – Encoding of User Data Header and generic IEConcatenated short message IE encoding
So what we end up with is a header inside our user payload, advising that this is a concatenated SMS, the message identifier, the number of parts in the message, and the part number of this particular message.
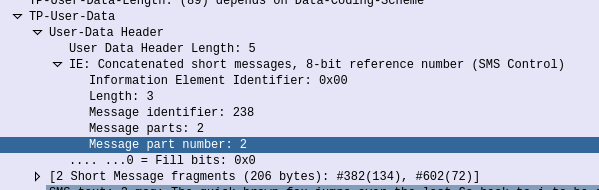
Last part of two part SMS
The SMSc on receipt of these has to spool them back out to the destination with the same message part number, and same headers in place.
The phone receiving the SMS has to wait for all the parts to come through and then reassemble before rendering to the user.
So that’s how concatenated SMS works. While this may seem convoluted and silly in a world where transfering more than 140 bytes of data is trivial, SMS was introduced in the early 1990s, and in theory at least, a user with a phone that supported SMS purchased when SMS was introduced, should still be able to interwork with phones today.
Previous generations of core mobile network, would only allocate a single IP address per UE (Well, two if dual-stack IPv4/IPv6 if you want to be technical). But one of the cool features in 5GC is the support for Framed Routing natively.
You could do this on several EPC platforms on LTE, but it’s support was always a bit shoe-horned in, and the UE was not informed of the framed addresses.
If you’ve worked in a wireline ISP you’re probably familiar with the concept of framed routing already, in short it’s one or more static routes, typically returned from a AAA server (Normally RADIUS) that are then routed to the subscriber.
Each subscriber gets allocated an IP by the network, but other IPs can also be routed to the subscriber, based on the network and CIDR mask.
So let’s say we allocate a public IP of 1.2.3.4/32 to our subscriber, but our subscriber is a fixed-wireless user running a business and they want a extra public IP Addresses.
How do we do this? With Framed Routing.
Now in our UDM we can add a “Framed IP”, and when the SMF sets up a session for our subscriber, the extra networks specified in the framed routes will get routed to that UE.
If we add 203.176.196.0/30 in our UDM for a subscriber, when the subscriber attaches the UPF will be setup to forward traffic to 1.2.3.4/32 and also traffic to 203.176.196.0/30 to the UE.
Update: I previously claimed: Best of all this is signaled to the UE during the attach, so the UE is say a router, it becomes aware of the Framed IPs allocated to it. This is incorrect! Thanks to Anonymous Telco Engineer from an Anonymous Nordic Country for pointing this out, it is not signaled to the UE.
More info in 3GPP TS 23.501 section 5.6.14 Support of Framed Routing.