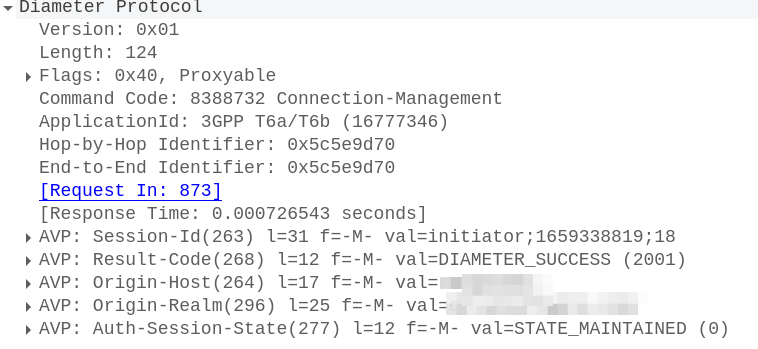
SMSc can send an SRI-for-SM, and if the subscriber is absent, the response can include the informServiceCenter message, which lets the SMSc know if it will get sent an alertServiceCentre message when the subscriber comes back online (sends an UpdateLocation).
This means that the SMSc can be notified when it can deliver the message to the subscriber.
It’s got a bunch of flags, which equate to:
sc-AddressNotIncluded means the service center address from the SRI-for-SM was not included in the Message Waiting Data file (and therefore will not get notified via AlertSC when the subscriber comes back online).
If it’s sc-AddressNotIncluded is set to False it means that the service center address has been added to the Message Waiting Data file, so will get an alertServiceCenter message when the sub comes back online (Double negative).
mnrf-Set means Mobile subscriber Not Reachable (Not registered on any MSC)
mcef-Set means Memory Capacity Exceeded Flag is set as the HLR has run out of memory in the Message Waiting Data file and cannot store any more data (So you won’t get notified via AlertSC when the subscriber comes back online)
mnrg-Set is for Mobile subscriber Not Reachable for GPRS (When using SGSN delivery is not registered for packet service).
mnr5g-Set means the SC will get notified when the subscriber becomes reachable from 5G serving nodes.
mnr5gn3g is a mystery – The only references to it I can find are in the ASN1 spec (hence why Wireshark decodes it) but as to its purpose, I can only guess.
A concept that’s always been a bit unclear to me was how the Sh Profile, XCAP data for call forwarding / barring and RepositoryData all fit together.
Let’s start off with the basics.
The Diameter Sh interface sits between an Application Server (Typically TAS, SMSc, XCAP server, etc) and the HSS.
This AS can run a Diameter User Data Request to get the contents of Sh Data, which is returned in the User Data AVP (702) for a given subscriber.
Application Servers can also subscribe to be notified of changes in the Sh data on the HSS, by sending a Subscriber Notification Request, and when the data changes they’ll get a “Push Notification Request” to inform them of the change.
When sending this User Data Request the AS can specify what data it wants to get returned, for example an AS might want to know the current S-CSCF of a given subscriber, in which case, the AS would set the DataReference AVP (703) to 12 for S-CSCFName.
Not the complete list…
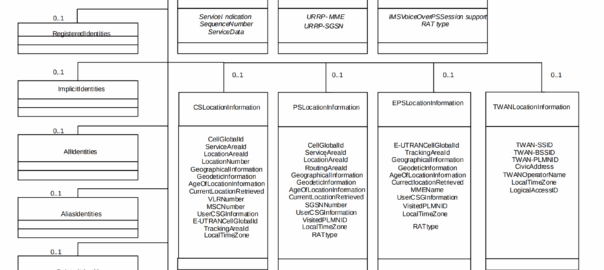
The the AS can request can be public and private identities (IMSIs and MSISDNs), location in the PS and CS networks, TADS info, SRVCC parameters, etc, etc.
Data like TADS Info, CS and PS network location, Public and Private identities, come from the HSS and cannot be modified, these values either come from the static subscriber definition in the HSS (what was set when provisioning the subscriber), or based on the subscriber’s state (ie where they’re registered on the network).
RepositoryData
But there is a section of data we can request the HSS return called RepositoryData which can be modified/updated by the end user or other applications in the network (Modified by ASes), via a Profile Update Request.
This data is where we put the call forwarding, call barring, caller ID presentation/restriction info – The HSS doesn’t really care what is stored in RepositoryData, it’s just a transparent place to store this data.
Think of it as a simple folder containing text files, each text file has a name (ServiceNotification) which allows us to reference the blobs of data by name, a SequenceNumber to identify duplicates, and then the actual contents of the file itself ServiceData.
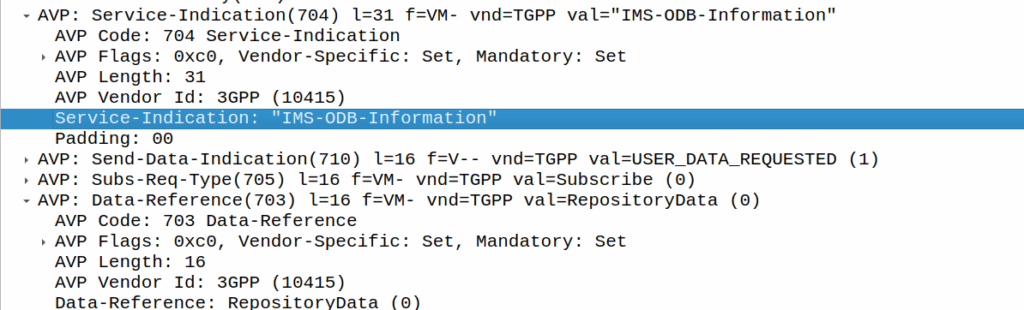
We can then request the contents of these files from the HSS by calling DataReference of RepositoryData and setting the ServiceIndication to be the “file” we want returned to the AS by the HSS.
For example, if the Data-Reference AVP is set to zero (Repository Data) and the Service-Indicator AVP is set to “IMS-ODB-Information” the HSS will return the data for the file IMS-ODB-Information of repository data.
This RepositoryData is just “transparent” storage of XML data by the HSS, and this is where we’d put Call Forwarding, Operator Defined Barring and CLI presentation/restriction parameters.
In theory you could also store 3rd party custom unstructured data here (Move over AWS S3 buckets, I’m moving all my storage to Diameter!), but it’s not commonly used beyond call routing parameters.
The two most common types of ServiceIndication keys you’ll see stored in RepositoryData are MMTEL-Services and IMS-ODB-Information. Each of these are defined by their own XML spec, but the MMTel-Services key is where all of our Call Forwarding, Caller ID Presentation/Restriction parameters live, while IMS-ODB-Information contains the parameters for Operator Defined barring – Both of these XML definitions we’ll dive into in a post of their own, but for now all you need to remember is that they’re stored transparently as XML on the HSS.
An example use case of this would be when a user wants to manage their call forwarding data via XCAP. When the user pulls up the Call Forwarding menu on their phone, the first entry point will be the XCAP Server (AS) to get all the User Data for MMTelServices, so it’ll do that via a Diameter User Data Request with the DataReference set to RepositoryData and the ServiceIndication set to MMTel-Service so the XCAP server can pass the full XCAP XML body to the UE.
The UE can then update this data, and the XCAP server just sends a Profile Update Request to push the updated XML to be stored on the HSS.
Fitting this all Together
Data sent to the AS by the HSS will always include the <Sh-Data> XML, but the child keys within it depend on the data the AS requested under the Data-Reference.
If we requested IMSI as the DataReference, then the returned XML might look like:
<Sh-Data> <imsi>9990112345677</imsi> </Sh-Data>
Likewise, if you requested IMSPublicIdentity as the DataReference you’d get:
The spec goes into full detail on all the possible keys, but in short, when the AS queries the data for the provided DataReference, the HSS sends back an Sh-Data XML body containing at a minimum those keys.
Recently I’ve been playing with creating UPPs – Unprotected Profile Packages – The “profile” that gets loaded onto eSIMs.
While that’s worthy of a post itself, for testing I’ve found it really convenient to be able to “explore” the created SIM profile in PySIM, Gemalto Card Admin, etc, and check the behavior in a real handset using the SIMtrace.
So how do you get an eSIM onto a physical card?
For that I’m using a physical consumer eSIM, which is a physical SIM card I can load an eSIM onto.
Normally the eSIM is baked into your phone, but this one isn’t, it’s baked into a 4FF form factor.
But while iOS and Android have got flows for loading the eSIM (the Local Profile Assistant), this is just a bit of plastic, so we need our own external LPA to pull the eSIM from the SM-DP+ and load it onto the card.
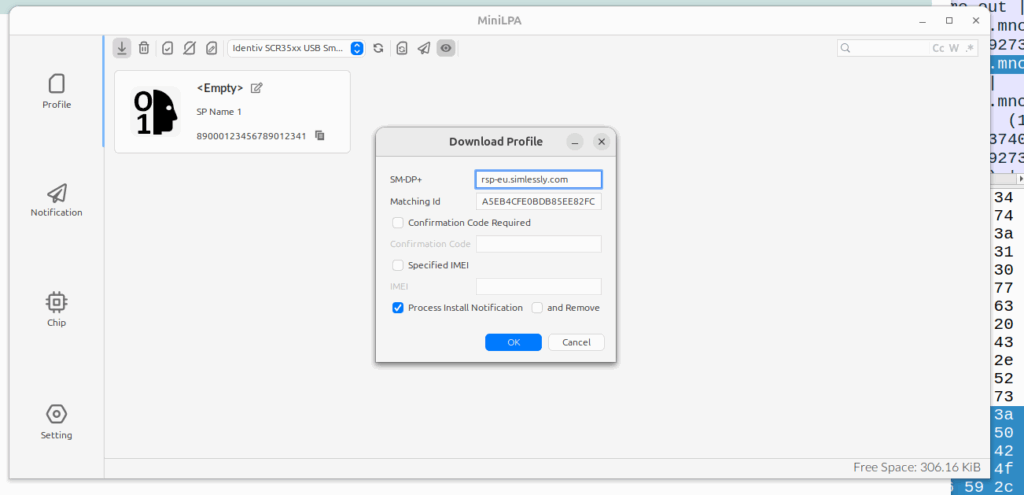
So in addition to this a SIM card reader I used a nifty util called MiniLPA which is the Local-Profile-Assistant, used to load eSIM profiles onto the eSIM itself.
I installed the Debian package of MiniLPA, started it up, plugged in my SIM reader and consume eUICC, then took the LPA address and split the SM-DP+ address (the Domain name part) and the ID (the long hex string part) up and plugged them into the download profile window and boom, I had a profile loaded and could work with the eSIM profile on a physical card.
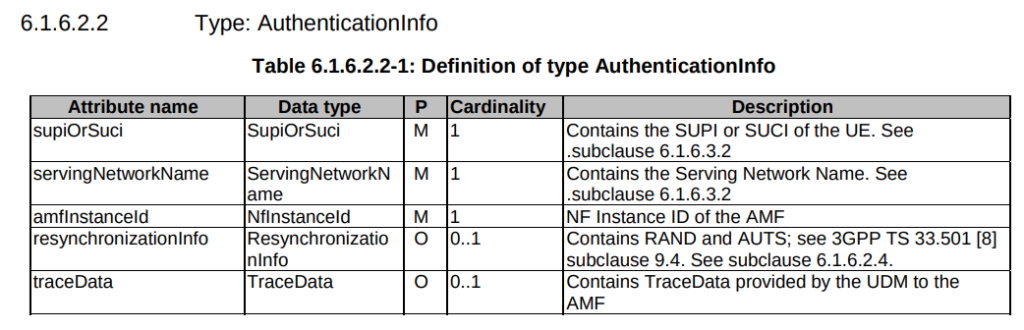
The UE Authentication Service is consumed by the AMF. The AMF initiates the authentication operation, when indicated, as part of the UE registration process. The AUSF performs either 5G-AKA or EAP-based authentication based on information received from the AMF. If EAP authentication is used then the AUSF and the UE exchange EAP messages through the AMF.
3GPP TS 29.509 V16.3.0; 5G System; Authentication Server Services
Common Dialogs on Nausf-auth Service
Authenticate UE – Request
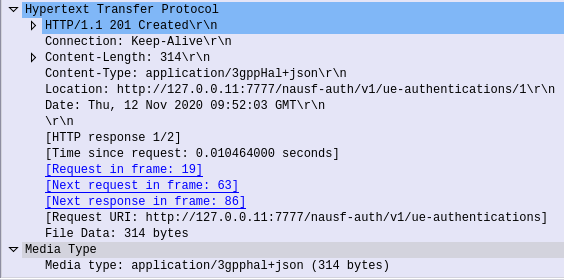
HTTP POST sent from the AMF to the AUSF, to the URL /nausf-auth/v1/ue-authentications with JSON body containing the SUPI or the SUCI, and the serving network name.
Authenticate UE – Response
If request from the AMF is successfully processed by the AUSF, it sends back a “201 Created” response, with a JSON Body containing the authentication vectors:
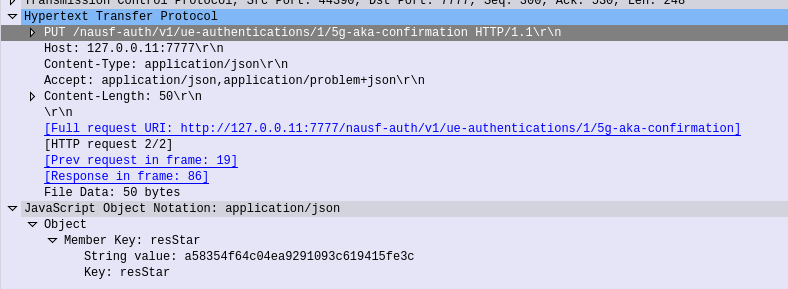
The AMF needs to advise the AUSF the RES returned from the Subscriber (if one was returned) to confirm the UE successfully authenticated, so the AMF sends this in the form of an HTTP PUT to the AUSF to the URL /nausf-auth/v1/ue-authentications/1/5g-aka-confirmation
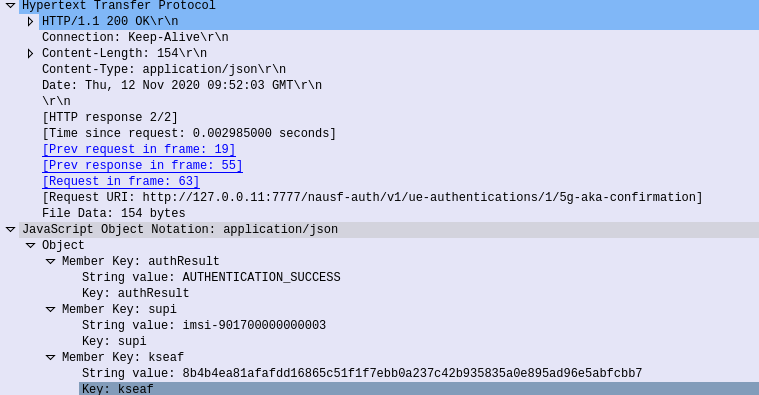
5G-AKA Confirmation – Response
If successful a 200 OK is sent back to the AMF by the AUSF with a JSON body containing the SUPI of the Subscriber (keep in mind the subscriber may have authenticated with a SUCI, so up until this point the AMF doesn’t know the SUPI of the Subscriber), and the Kseaf key used for ciphering and integrity protection.
Common Dialogs on Nudm-ueau Service
The Nudm_UEAuthentication service is used by NF service consumers to obtain UE authentication vectors from the UDM, to inform the UDM of authentication results, to query authentication results, and to purge authentication results.
3GPP TS 29.503 Unified Data Management Services
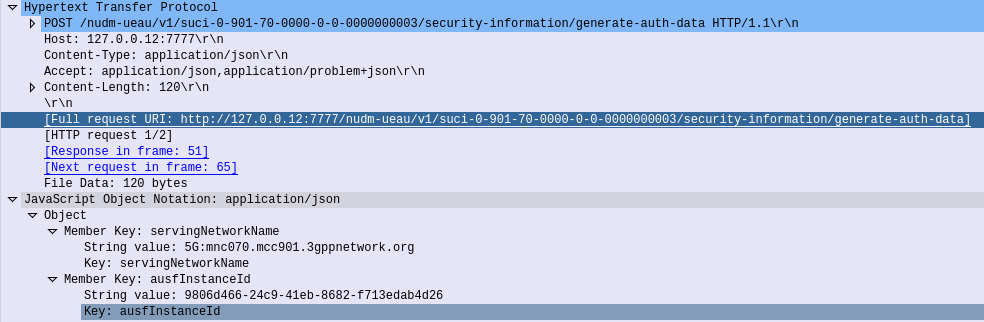
Generate Authentication Data – Request
When the AUSF needs to authenticate a subscriber, for example because an AMF has requested vectors, it in turn needs to request this information be generated by the UDM.
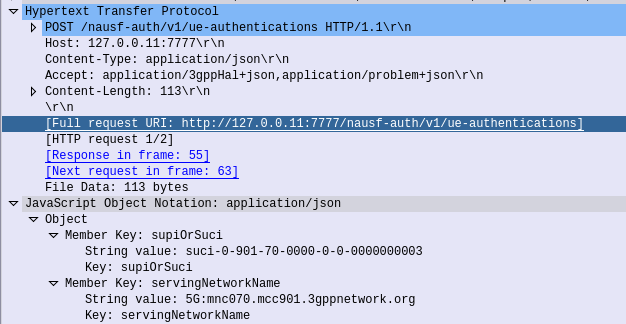
So the AUSF sends a HTTP POST to /nudm-ueau/v1/suci-0-901-70-0000-0-0-0000000003/security-information/generate-auth-data on the UDM (Where 901-70-0000-0-0-0000000003 is the SUPI or SUCI of the subscriber), and with a JSON body containing the AUSF’s Instance ID.
Generate Authentication Data – Response
Once the UDM has
The UDM will need to take the SUPI/SUCI provided by the AUSF and generate the authentication vectors following the AKA Process taking the OP/OPc & K keys as inputs.
The UDM sends a 200 OK back to the AUSF that requested the information, with a JSON Body containing the full vectors, including the Kausf to be provided to the AMF when the subscriber has successfully authenticated.
The AUSF sends an HTTP GET to the UDM with the SUPI/SUCI in the URI /nudr-dr/v1/subscription-data/imsi-901700000000003/authentication-data/authentication-subscription
To do this the UDM needs the K & OP (or OPc) values for that subscriber, depending on the UDM configuration, it may have this data cached, or it may need to retrieve these values from the UDR.
One of the guys at work asked a seemingly simple question, is the PLMN with MCC 505 and MNC 57 the same as MCC 505 MNC 057 – It’s on 6 octets after all.
So is Mobile Network Code 57 the same as Mobile Network Code 057 in the PLMN code?
The answer is no, and it’s a massive pain in the butt.
All countries use 3 digit Mobile Country Codes, so Australia, is 505. That part is easy.
The tricky part is that some countries (Like Australia) use 2 digit Mobile Network Codes, while others (Like the US) use 3 digit mobile network codes.
Why would you do this? Why would a regulator opt to have 1/10th the addressable size of network codes – I don’t know, and I haven’t been able to find an answer – If you know please drop a comment, I’d love to know.
That’s all well and good from a SIM perspective, but less useful for scenarios where you might be the Visited PLMN for example, and only see the IMSI of a Subscriber.
We worked on a project in a country that mixed both 2 digit and 3 digit Mobile Network Codes, under the same Mobile Country Code. Certain Qualcomm phones would do very very strange things, and it took us a long time and a lot of SIM OTA to resolve the issue, but that’s a story for another day…
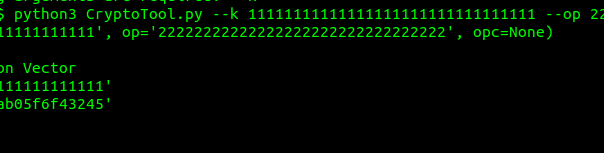
Namespace(k='11111111111111111111111111111111', op='22222222222222222222222222222222', opc=None) Generating OPc key from OP & K Generating Multimedia Authentication Vector Input K: b'11111111111111111111111111111111' Input OPc: b'2f3466bd1bea1ac9a8e1ab05f6f43245' Input AMF: b'\x80\x00'
Of course, being open source, you can grab the functions out of this and make a little script to convert everything in a CSV or whatever format your key data is in.
So what about OPc to OP? Well, this is a one-way transaction, we can’t get the OP Key from an OPc & Ki.
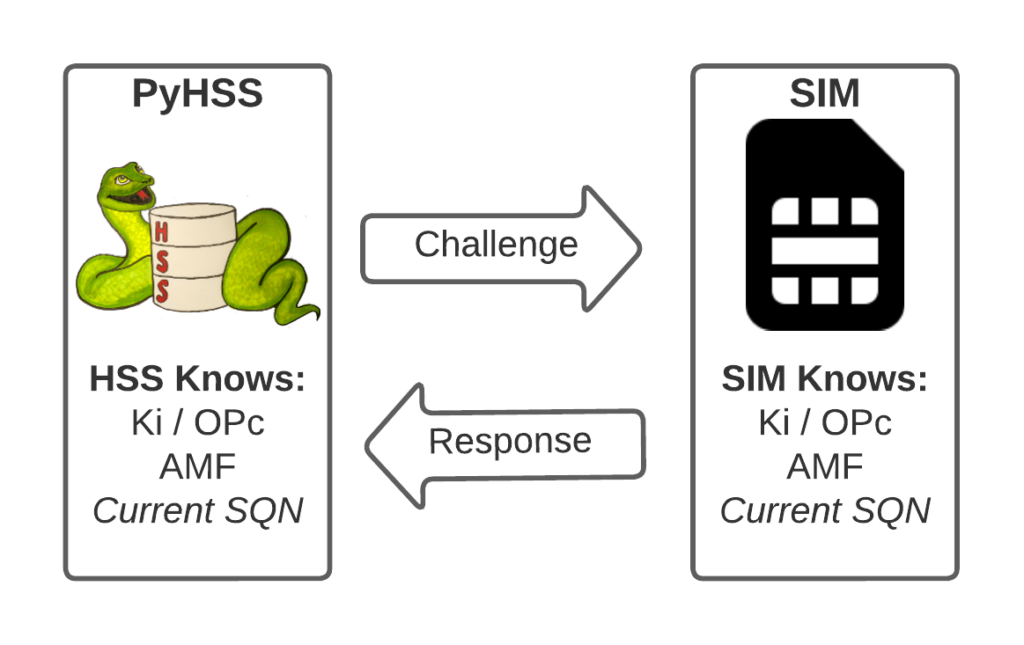
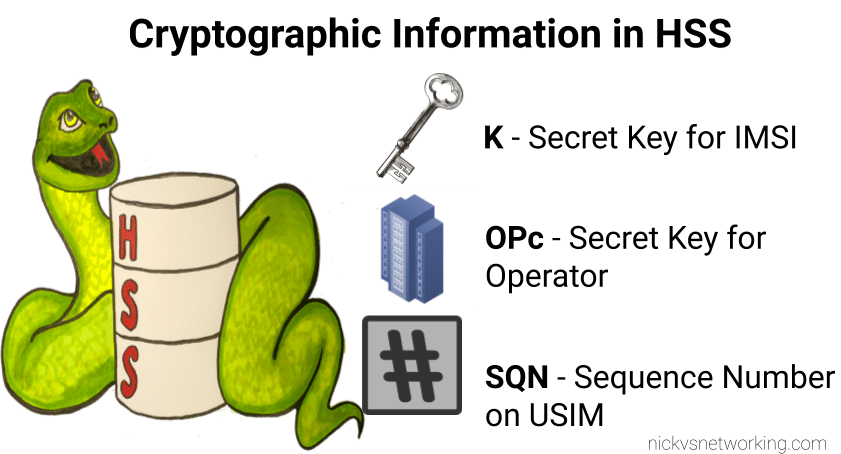
I’ve written about Milenage and SIM based security in the past on this blog, and the component that prevents replay attacks in cellular network authentication is the Sequence Number (Aka SQN) stored on the SIM.
Think of the SQN as an incrementing odometer of authentication vectors. Odometers can go forward, but never backwards. So if a challenge comes in with an SQN behind the odometer (a lower number), it’s no good.
Why the SQN is important for Milenage Security
Every time the SIM authenticates it ticks up the SQN value, and when authenticating it checks the challenge from the network doesn’t have an SQN that’s behind (lower than) the SQN on the SIM.
Let’s take a practical example of this:
The HSS in the network has SQN for the SIM as 8232, and generates an authentication challenge vector for the SIM which includes the SQN of 8232. The SIM receives this challenge, and makes sure that the SQN in the SIM, is equal to or less than 8232. If the authentication passes, the new SQN stored in the SIM is equal to 8232 + 1, as that’s the next valid SQN we’d be expecting, and the HSS incriments the counters it has in the same way.
By constantly increasing the SQN and not allowing it to go backwards, means that even if we pre-generated a valid authentication vector for the SIM, it’d only be valid for as long as the SQN hasn’t been authenticated on the SIM by another authentication request.
Imagine for example that I get sneaky access to an operator’s HSS/AuC, I could get it to generate a stack of authentication challenges that I could use for my nefarious moustache-twirling purposes whenever I wanted.
This attack would work, but this all comes crumbling down if the SIM was to attach to the real network after I’ve generated my stack of authentication challenges.
If the SQN on the SIM passes where it was when the vectors were generated, those vectors would become unusable.
It’s worth pointing out, that it’s not just evil purposes that lead your SQN to get out of Sync; this happens when you’ve got subscriber data split across multiple HSSes for example, and there’s a mechanism to securely catch the HSS’s SQN counter up with the SQN counter in the SIM, without exposing any secrets, but it just ticks the HSS’s SQN up – It never rolls back the SQN in the SIM.
The Flaw – Draining the Pool
The Authentication Information Request is used by a cellular network to authenticate a subscriber, and the Authentication Information Answer is sent back by the HSS containing the challenges (vectors).
When we send this request, we can specify how many authentication challenges (vectors) we want the HSS to generate for us, so how many vectors can you generate?
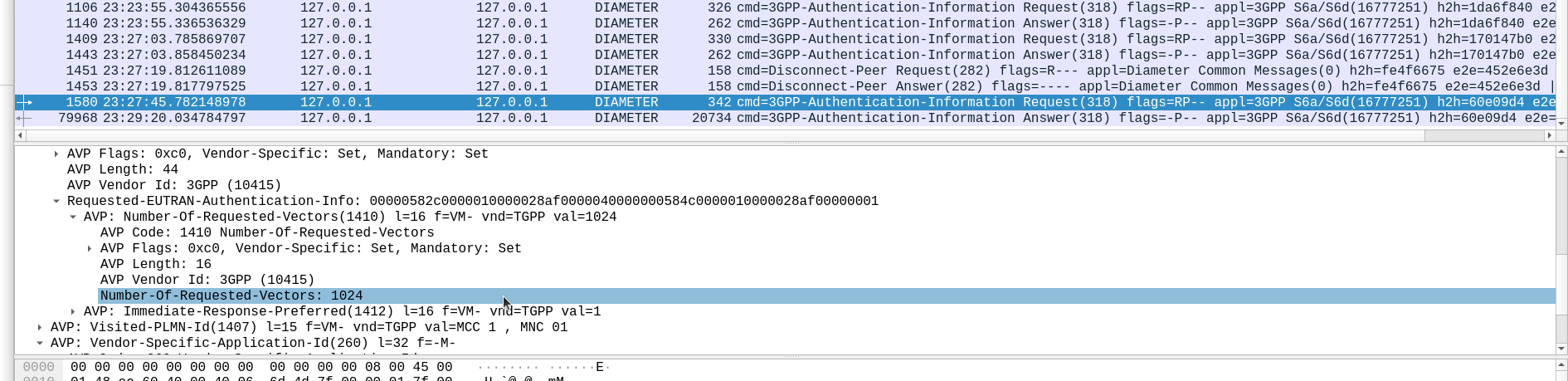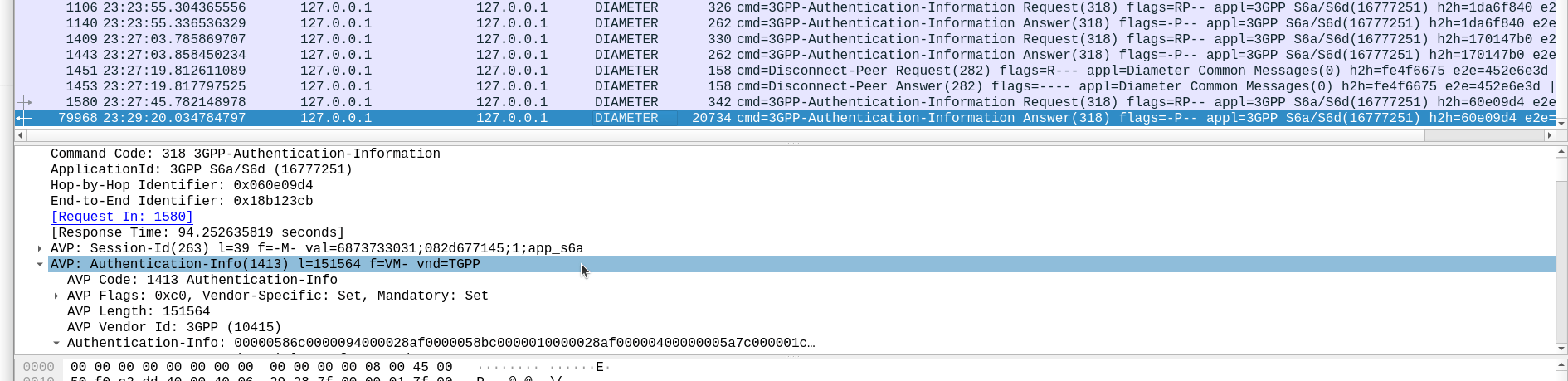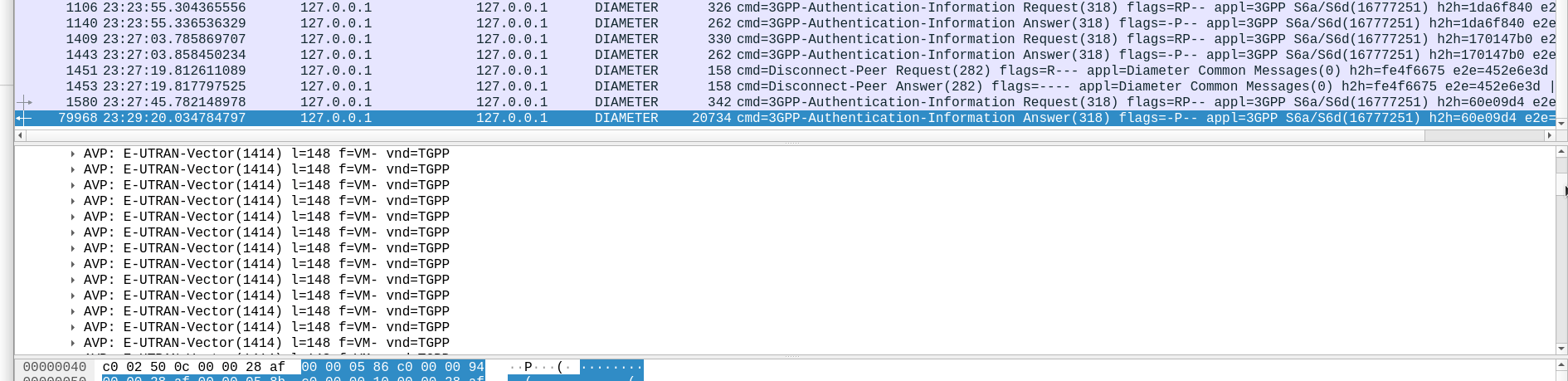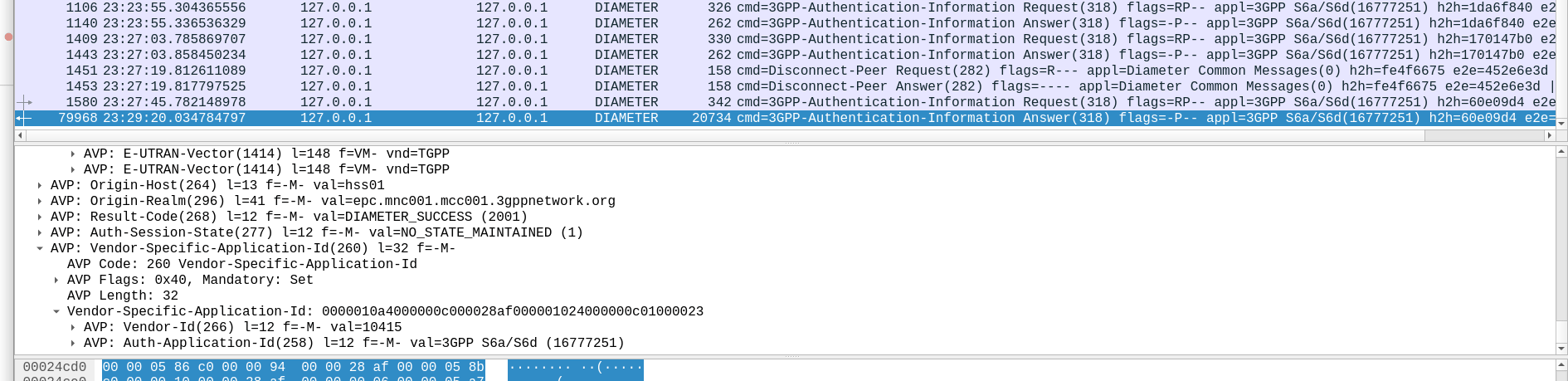
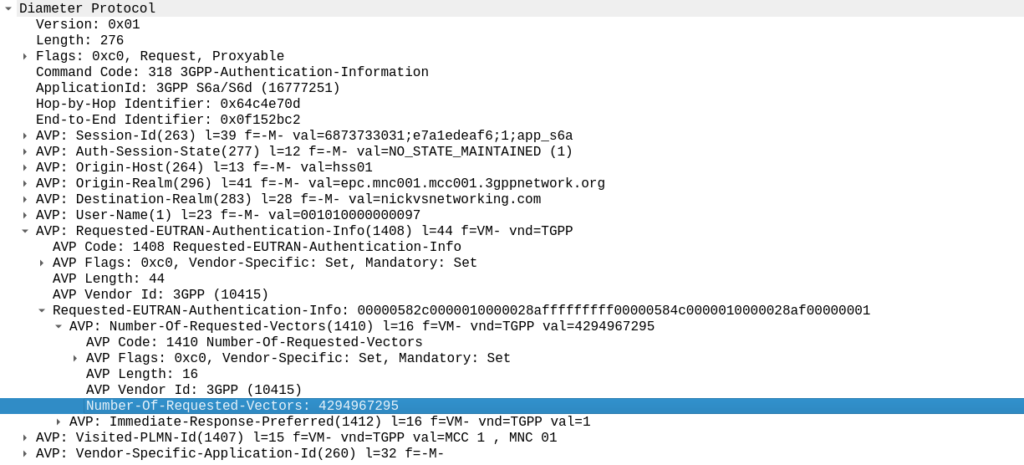
TS 129 272 says the Number-of-Requested-Vectors AVP is an Unsigned32, which gives us a possible pool of 4,294,967,295 combinations. This means it would be legal / valid to send an Authentication Information Request asking for 4.2 billion vectors.
It’s worth noting that that won’t give us the whole pool.
Sequence numbers (SQN) shall have a length of 48 bits.
TS 133 102
While the SQN in the SIM is 48 bits, that gives us a maximum number of values before we “tick over” the odometer of 281,474,976,710,656.
If we were to send 65,536 Authentication-Information-Requests asking for 4,294,967,295 a piece, we’d have got enough vectors to serve the sub for life.
Except the standard allows for an unlimited number of vectors to be requested, this would allow us to “drain the pool” from an HSS to allow every combination of SQN to be captured, to provide a high degree of certainty that the SQN provided to a SIM is far enough ahead of the current SQN that the SIM does not reject the challenges.
Can we do this?
Our lab has access to HSSes from several major vendors of HSS.
Out of the gate, the Oracle HSS does not allow more than 32 vectors to be requested at the same time, so props to them, but the same is not true of the others, all from major HSS vendors (I won’t name them publicly here).
For the other 3 HSSes we tried from big vendors, all eventually timed out when asking for 4.2 billion vectors (don’t know why that would be *shrug*) from these HSSes, it didn’t get rejected.
This is a lab so monitoring isn’t great but I did see a CPU spike on at least one of the HSSes which suggests maybe it was actually trying to generate this.
Of course, we’ve got PyHSS, the greatest open source HSS out there, and how did this handle the request?
Well, being standards compliant, it did what it was asked – I tested with 1024 vectors I’ll admit, on my little laptop it did take a while. But lo, it worked, spewing forth 1024 vectors to use.
So with that working, I tried with 4,294,967,295…
And I waited. And waited.
And after pegging my CPU for a good while, I had to get back to real life work, and killed the request on the HSS.
In part there’s the fact that PyHSS writes back to a database for each time the SQN is incremented, which is costly in terms of resources, but also that generating Milenage vectors in LTE is doing some pretty heavy cryptographic lifting.
The Risk
Dumping a complete set of vectors with every possible SQN would allow an attacker to spoof base stations, and the subscriber would attach without issue.
Historically this has been very difficult to do for LTE, due to the mutual network authentication, however this would be bypassed in this scenario.
The UE would try for a resync if the SQN is too far forward, which mitigates this somewhat.
Cryptographically, I don’t know enough about the Milenage auth to know if a complete set of possible vectors would widen the attack surface to try and learn something about the keys.
Mitigations / Protections
So how can operators protect ourselves against this kind of attack?
Different commercial HSS vendors handle this differently, Oracle limits this to 32 vectors, and that’s what I’ve updated PyHSS to do, but another big HSS vendor (who I won’t publicly shame) accepts the full 4294967295 vectors, and it crashes that thread, or at least times it out after a period.
If you’ve got a decent Diameter Routing Agent in place you can set your DRA to check to see if someone is using this exploit against your network, and to rewrite the number of requested vectors to a lower number, alert you, or drop the request entirely.
Having common OP keys is dumb, and I advocate to all our operator customers to use OP keys that are unique to each SIM, and use the OPc key derived anyway. This means if one SIM spilled it’s keys, the blast doesn’t extend beyond that card.
In the long term, it’d be good to see 3GPP limit the practical size of the Number-of-Requested-Vectors AVP.
2G/3G Impact
Full disclosure – I don’t really work with 2G/3G stacks much these days, and have not tested this.
MAP is generally pretty bandwidth constrained, and to transfer 280 billion vectors might raise some eyebrows, burn out some STPs and take a long time…
But our “Send Authentication Info” message functions much the same as the Authentication Information Request in Diameter, 3GPP TS 29.002 shows we can set the number of vectors we want:
5GC Vulnerability
This only impacts LTE and 5G NSA subscribers.
TS 29.509 outlines the schema for the Nausf reference point, used for requesting vectors, and there is no option to request multiple vectors.
Summary
If you’ve got baddies with access to your HSS / HLR, you’ve got some problems.
But, with enough time, your pool could get drained for one subscriber at a time.
This isn’t going to get the master OP Key or plaintext Ki values, but this could potentially weaken the Milenage security of your system.
If you’re working with the larger SIM vendors, there’s a good chance they key material they send you won’t actually contain the raw Ki values for each card – If it fell into the wrong hands you’d be in big trouble.
Instead, what is more likely is that the SIM vendor shares the Ki generated when mixed with a transport key – So what you receive is not the plaintext version of the Ki data, but rather a ciphered version of it.
But as long as you and the SIM vendor have agreed on the ciphering to use, an the secret to protect it with beforehand, you can read the data as needed.
This is a tricky topic to broach, as transport key implementation, is not covered by the 3GPP, instead it’s a quasi-standard, that is commonly used by SIM vendors and HSS vendors alike – the A4 / K4 Transport Encryption Algorithm.
It’s made up of a few components:
K2 is our plaintext key data (Ki or OP)
K4 is the secret key used to cipher the Ki value.
K7 is the algorithm used (Usually AES128 or AES256).
It’s important when defining your electrical profile and the reuqired parameters, to make sure the operator, HSS vendor and SIM vendor are all on the same page regarding if transport keys will be used, what the cipher used will be, and the keys for each batch of SIMs.
Here’s an example from a Huawei HSS with SIMs from G&D:
We’re using AES128, and any SIMs produced by G&D for this batch will use that transport key (transport key ID 1 in the HSS), so when adding new SIMs we’ll need to specify what transport key to use.
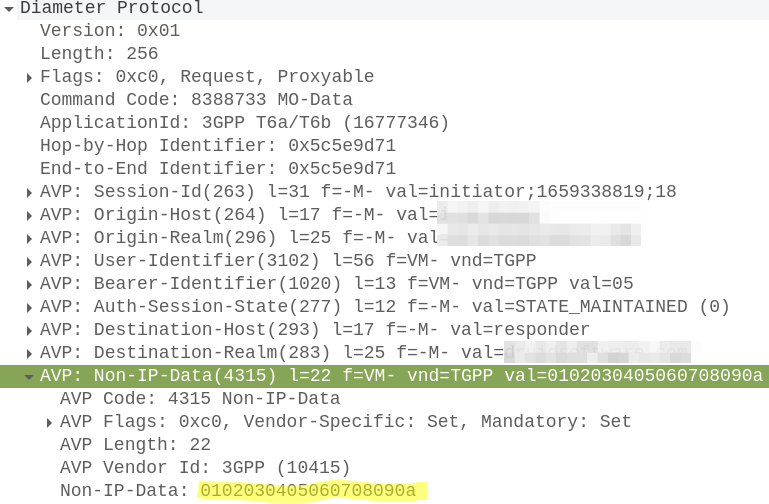
In our last post we covered the basics of NB-IoT Non-IP Data Deliver (NIDD), and if that acronym soup wasn’t enough for you, we’re going to take a deep dive into the flows for attaching, sending, receiving and closing a NIDD session.
The attach for NIDD is very similar to the standard attach for wideband LTE, except the MME establishes a connection on the T6a Diameter interface toward the SCEF, to indicate the sub is online and available.
The NIDD Attach
The SCEF is now able to send/receive NIDD traffic from the subscriber on the T6a interface, but in reality developers don’t / won’t interact with Diameter, so the SCEF exposes the T8 API that developers can interact with to access an abstraction layer to interact with the SCEF, and then through onto the UE.
If you’re wondering what the status of Open Source SCEF implementations are, then you may have already guessed we’re working on one! PyHSS should have support for NB-IoT SCEF features in the future.
NB-IoT provides support for Non-IP Data Delivery (NIDD) over 3GPP Networks, but to handle this, some new network elements are introduced, in a home network scenario that’s the SCEF and the SCF/AS.
On the 3GPP side the SCEF it communicates to the MME via the T6a Interface, which is based upon Diameter.
On the side towards our IoT Service Consumers (in the standards referred to as “SCS/AS” or “Service Capabilities Server Application Servers” (catchy names as always), via the RESTful HTTP based T8 interface.
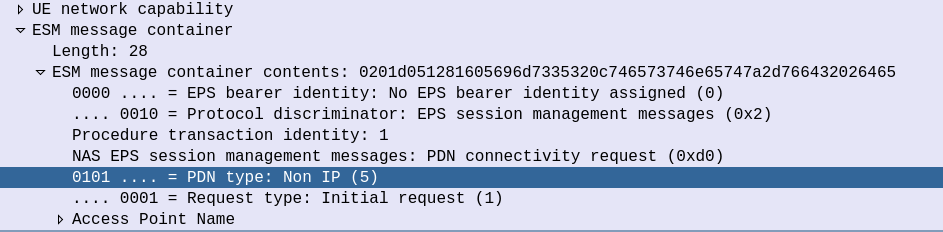
The start of the S1 Attach procedure is very similar to a regular S1 attach.
The initial S1 PDU Connectivity Request indicates in the ESM Message Container that the PDN Type is Non IP.
S1 PDU Connectivity Request from attach procedure
Other than that, the initial attach procedure looks very similar to the regular S1 attach procedure.
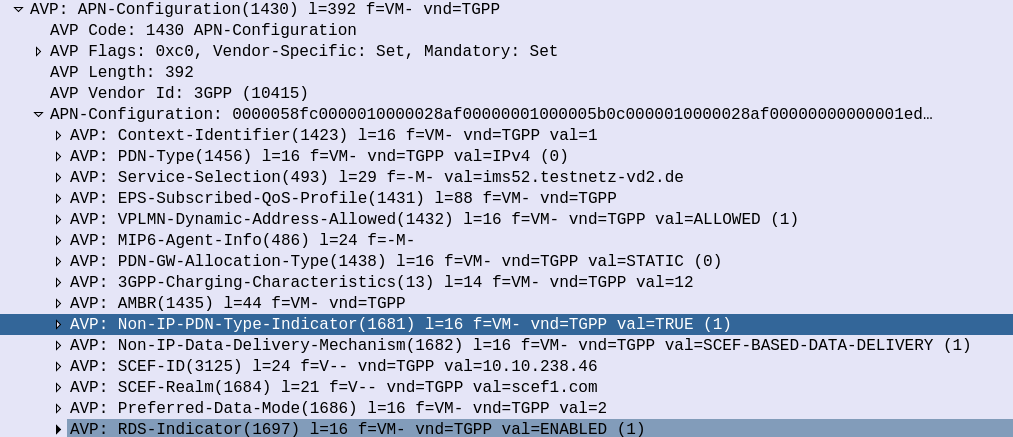
On the S6a interface the Update Location Request from the MME to the HSS indicates that this is an EUTRAN-NB-IoT Radio Access Type.
And the Update Location Answer APN Configuration contains some additional AVPs on the APN to indicate that the APN supports Non-IP-PDN-Type and that the SCEF is used for Data Delivery.
The SCEF-ID (Diameter Host) and SCEF-Realm (Diameter realm) to serve this user is also specified in the APN Configuration in the Update Location Answer.
This is how our MME determines where to send the T6a traffic.
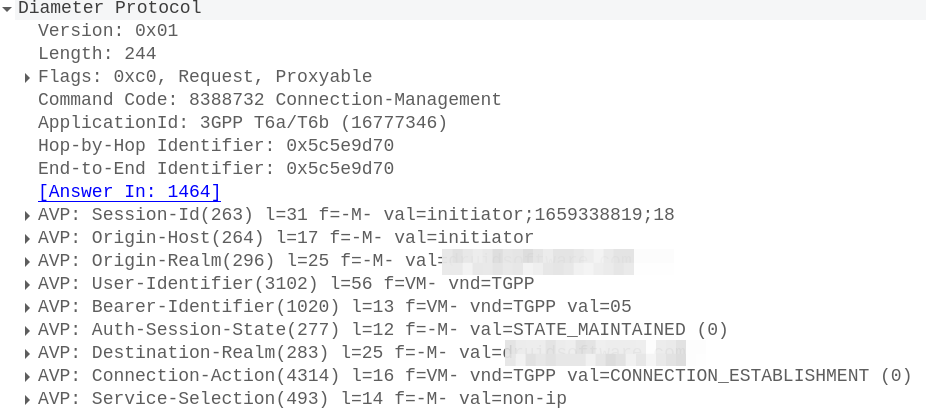
With this, the MME sends a Connection Management Request (CMR) towards the SCEF specified in the SCEF-ID returned by the HSS.
The Connection Management Request / Response
The MME now sends a Diameter T6a Connection Management Request to the SCEF in the Update Location Answer,
In it we have a Session-Id, which continues for the life of our NIDD session, the service-selection which contains our APN (In our case “non-ip”) and the User-Identifier AVP which contains the MSISDN and/or IMSI of the subscriber.
To accept this, the SCEF sends back a Connection-Management-Answer to confirm we’re all good to go:
At this point our SCEF now knows about the subscriber who’s just attached to our network, and correlates it with the APN and the session-ID.
On the S1 side the connection is confirmed and we’re ready to roll.
Mobile Originated Data Request / Response
When the UE wants to send NIDD it’s carried in NAS messaging, so we see an Uplink NAS transport from the UE and inside the NAS payload itself is our HEX data.
Our MME grabs this out and sends it in the form of of a Mobile-Originated-Data-Request (MODR) to the SCEF, along with the same Session-ID that was setup earlier:
At this stage our Non-IP Data is exposed over the T8 RESTful API, which we won’t cover in this post.
The Equipment Identity Register (EIR) is a pretty handy function in 3GPP networks.
Via the Diameter based S13 interface, the MME, is able to query the EIR to ask if a given IMEI & IMSI combination should be allowed to attach.
This allows stolen / grey market / unauthorized devices (IMEIs) to be rejected from the network, the EIR can have a list of “bad” IMEIs that if seen will reject the request.
It also allows us to lock a SIM (IMSI) to a given device (IMEI) or type of device – We can use this for say a Fixed Wireless service, to lock the SIMs (IMSIs) to a range of modems (IMEI Prefixes).
Lastly it gives us insight and analytics into the devices used on the network, by mapping the IMEI to a device, we can say that IMEI 1234567890 is an Apple iPhone 12 Pro Max, or a Nokia Fastmile 5G-24W-A.
PyHSS supports all these capabilities, so let’s have a look at how we’d manage / access them.
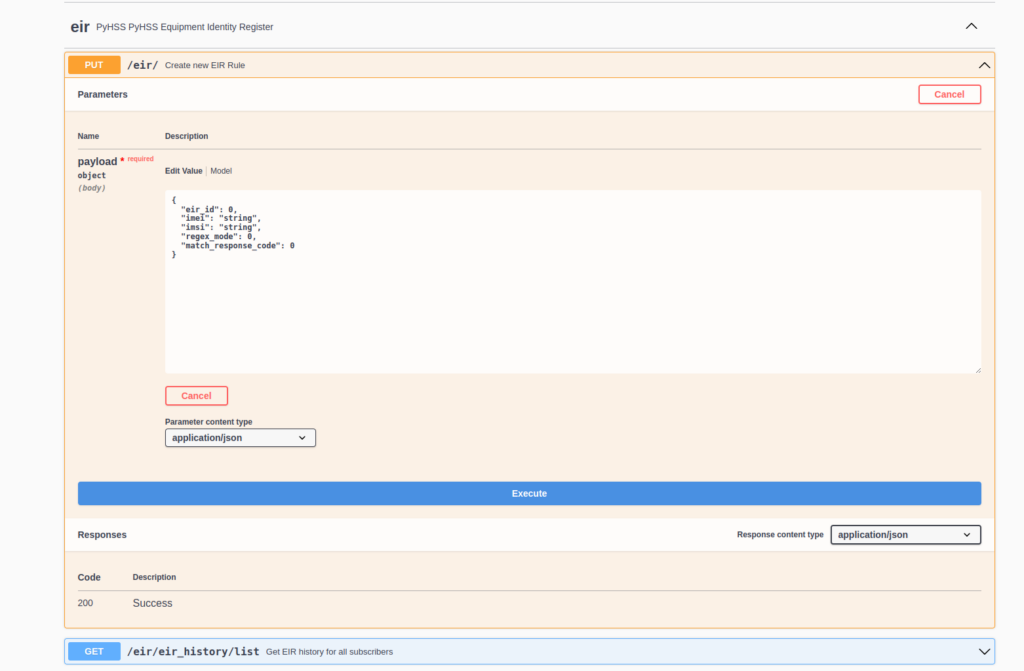
Setting up EIR Rules
These rules are set via the RESTful API in PyHSS.
The Equipment Identity Register built into PyHSS supports matching in one of two modes, set by regex_mode.
In Exact Mode (regex_mode: 0) matches are based on an exact matching IMEI, and matching the IMSI if set (If IMSI is set to nothing (”), then only the IMEI is evaluated).
Exact Mode is suited for IMEI/IMSI locking, to ensure a SIM is locked to a particular device, or to blacklist stolen devices.
Regex Mode (regex_mode: 1) matches based on Regex, this is suited for whitelisting IMEI prefixes for say, specific validated vendors.
The match_response_code maps to the Equipment-Status AVP output, so specified values are:
0 : ‘Whitelist’
1: ‘Blacklist’
2: ‘Greylist’
Some end to end examples of this provisioned into the API:
If the IMEI starts with 777 and the IMSI is 1234123412341234 then return 2 (Greylist).
No Match Behaviour
If there is no match from the backend, then the config parameter no_match_response dictates the response code returned (Blacklist/Whitelist/Greylist).
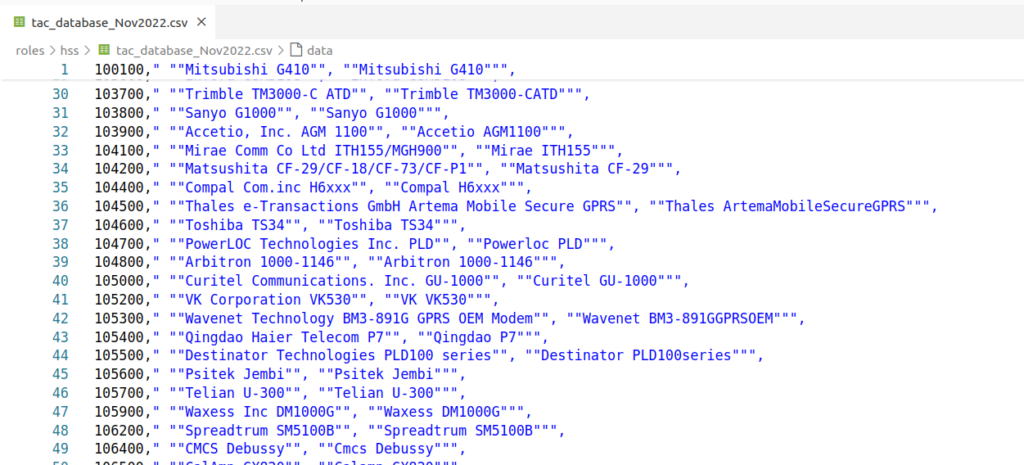
Mapping Type Allocation Codes (TACs) to IMEIs
There are several data feeds of the Type Allocation Codes (TACs) which map a given IMEI prefix to a model number.
TAC database extract
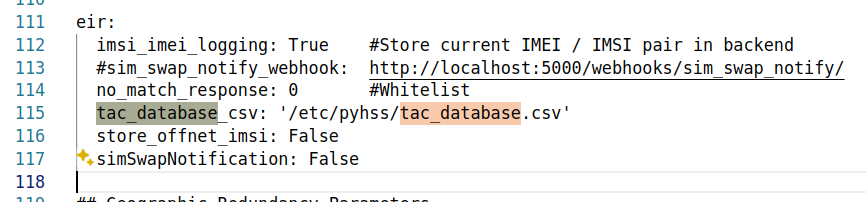
Unfortunately, this data is not freely available, so we can’t bundle it with PyHSS, but if you have the IMEI Database, you can load it into PyHSS using Redis, to allow us to report on this data.
In your config.yaml you’ll just need to set the tac_database parameter, which will read the data on startup.
PyHSS YAML Config extract
Triggering on SIM Swap
If we keep track of the current IMSI/IMEI combination used for each SIM/Device, we can get notified every time it changes.
You might want to use this to trigger OTA provisioning or clear old data in your IMS.
For that we can use the sim_swap_notify_webhook in the config to send a HTTP POST to a given endpoint to inform it that a SIM is now in a different device.
We also have to have imsi_imei_logging set to true in the Config in order to log the history.
Reporting on IMEIs
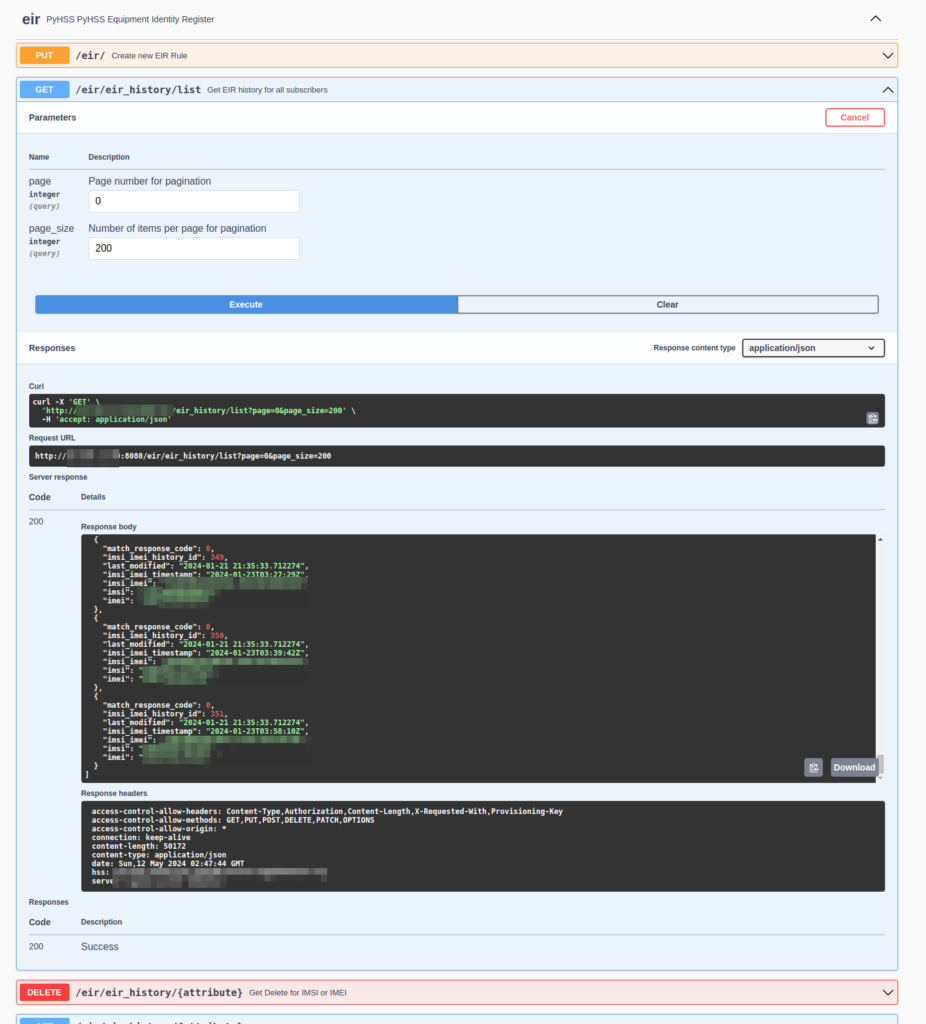
We can also log/capture historical data about IMSI/IMEI combinations.
We use this from a customer support perspective to be able to see if a customer has recently changed phones, so if they call support, our staff can ask the customer about it to help troubleshoot.
“I can see you were connected previously on a Samsung Galaxy S22, but now you’re using a Nokia 3310, did the issues happen before you moved phones?”
This is super handy.
We can get a general log of IMSI vs IMEI like this:
Feed of IMSI vs IMEI along with a timestamp and the response that was sent back
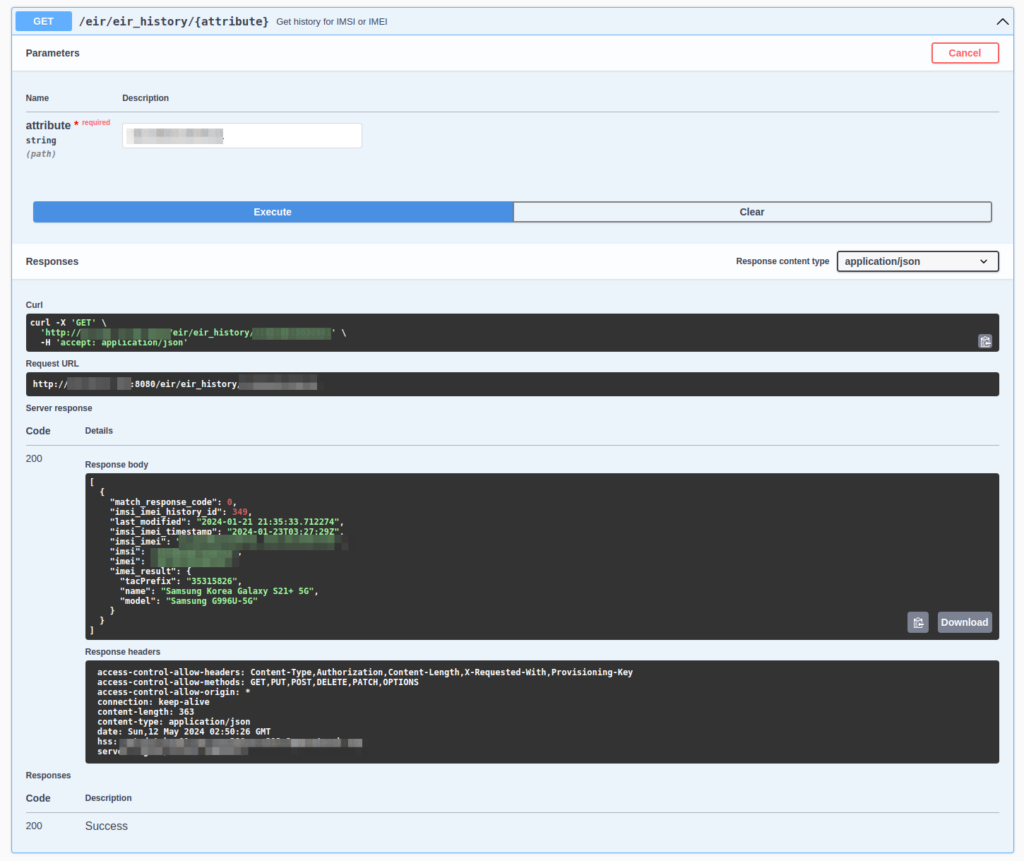
But what’s more useful is searching for a IMSI or an IMEI and then getting back a full list of devices / SIMs that have been used.
Searching for an IMSI I can see it’s only ever been used in this Samsung Galaxy
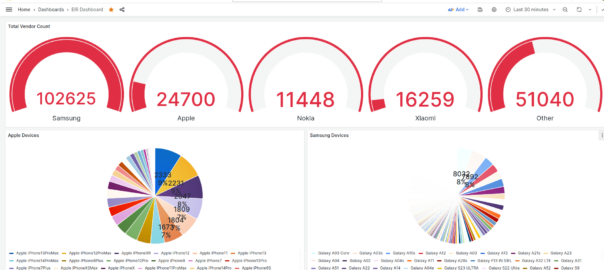
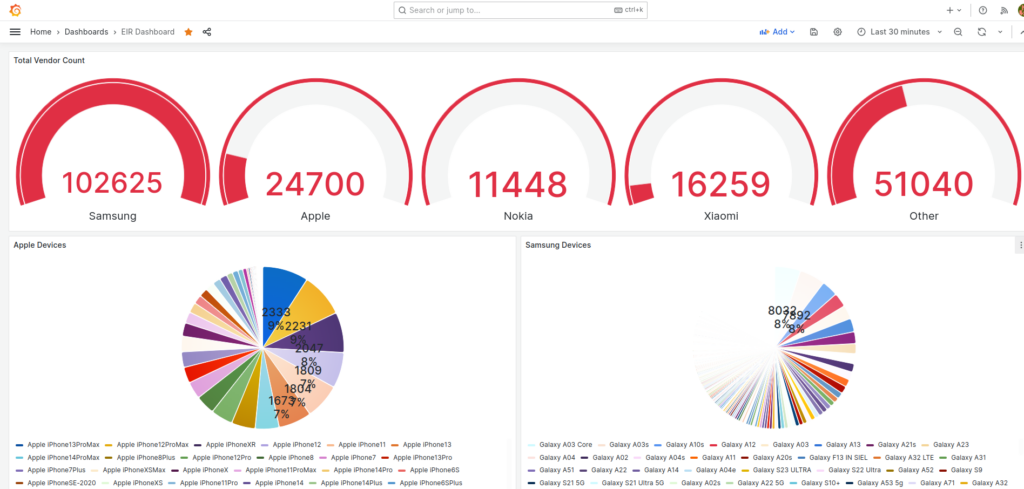
Lastly via Grafana we export all this data, which allows us to visualize this data and build dashboards showing the devices on the network.
Visualizing EIR Data in Grafana
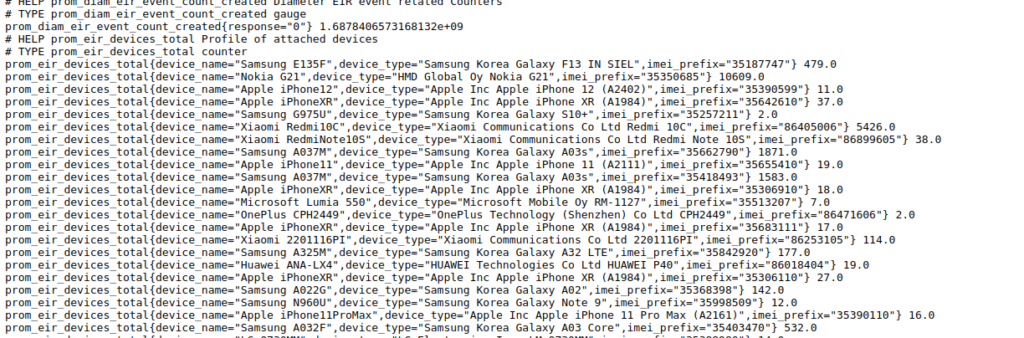
PyHSS includes a Promethues exporter, when it comes to prom_eir_devices_total it lists each seen Type Allocation Code / UE in the network, along with the number we’ve seen of each.
Raw it looks like this:
But visualized in Grafana we can get a dashboard to give us a breakdown per vendor:
Hello Nick, thank you for the article. What is the use of the OPc key to be derived from OP key ? Why can’t it just be a random key like Ki ?
It’s a super good question, and something I see a lot of operators get “wrong” from a security best practices perspective.
Refresher on OP vs OPc Keys
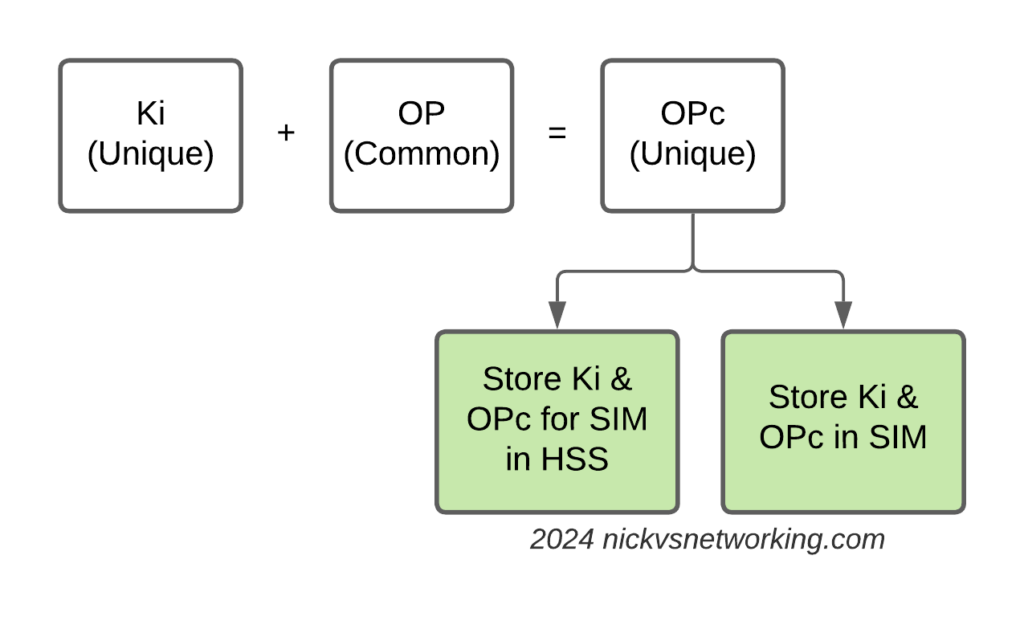
The “OP Key” is the “operator” key, and was (historically) common for an operator.
This meant all SIMs in the network had a common OP Key, and each SIM had a unique Ki/K key.
The SIM knew both, and the HSS only needed to know what the Ki was for the SIM, as they shared a common OP Key (Generally you associate an index which translates to the OP Key for that batch of SIMs but you get the idea).
But having common key material is probably not the best idea – I’m sure there was probably some reason why using a common key across all the SIMs seemed like a good option, and the K / Ki key has always been unique, so there was one unique key per SIM, but previously, OP was common.
Over time, the issues with this became clear, so the OPc key was introduced. OPc is derived from mushing the K & OP key together. This means we don’t need to expose / store the original OP key in the SIM or the HSS just the derived OPc key output.
This adds additional security, if the Ki for a SIM were to be exposed along with the OP for that operator, that’s half the entropy lost. Whereas by storing the Ki and OPc you limit the blast radius if say a single SIMs data was exposed, to only the data for that particular SIM.
This is how most operators achieve this today; there is still a common OP Key, locked away in a vault alongside the recipe for Coca-cola and the moon landing set.
But his OP Key is no longer written to the SIMs or stored in the HSS.
Instead, during the personalization process (The bit in manufacturing where SIMs get the unique data written to them (The IMSI & keys)) a derived OPc key is written to the card itself, and to the output files the operator then loads into their HSS/HLR/AuC.
This is not my preferred method for handling key material however, today we get our SIM manufacturers to randomize the OP key for every card and then derive an OPc from that.
This means we have two unique keys for each SIM, and even if the Ki and OP were to become exposed for a SIM, there is nothing common between that SIM, and the other SIMs in the network.
Do we want our Ki to leak? No. Do we want an OP Key to leak? No. But if we’ve got unique keys for everything we minimize the blast radius if something were to happen – Just minimizes the risk.
How does one encode / interpret the value of this AVP / IE was the question I set out to answer.
TS 29.274 says:
For the encoding of this information element see 3GPP TS 32.298
TS 32.298 says:
The functional requirements for the Charging Characteristics as well as the profile and behaviour bits are further defined in normative Annex A of TS 32.251
TS 32.251 Annex A says:
The Charging Characteristics parameter consists of a string of 16 bits designated as Behaviours (B), freely defined by Operators, as shown in TS 32.298 [51]. Each bit corresponds to a specific charging behaviour which is defined on a per operator basis, configured within the PCN and pointed when bit is set to “1” value.
After a few circular references I found this is imported from 32.298.
Finally we find some solid answers hidden away in TS 132 215, under the Charging Characteristics Profile index.
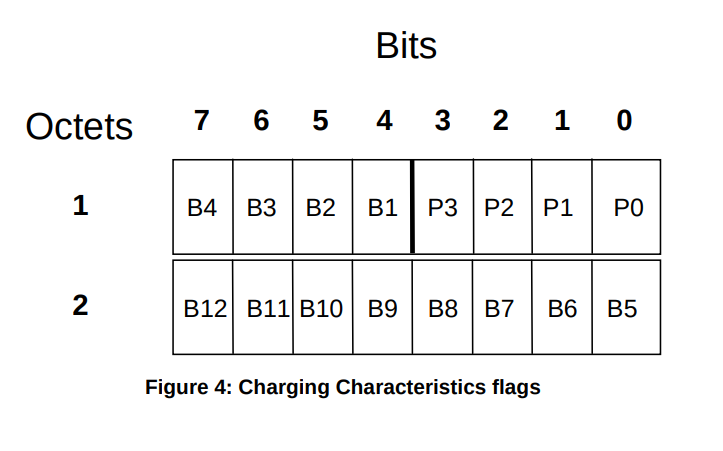
Charging Characteristics consists of a string of 16 bits designated as Profile (P) and Behaviour (B), shown in Figure 4. The first four bits (P) shall be used to select different charging trigger profiles, where each profile consists of the following trigger sets:
S-CDR: activate/deactivate CDRs, time limit, volume limit, maximum number of charging conditions, tariff times;
G-CDR: same as SGSN, plus maximum number of SGSN changes;
M-CDR: activate/deactivate CDRs, time limit, and maximum number of mobility changes;
SMS-MO-CDR: activate/deactivate CDRs;
SMS-MT-CDR: active/deactivate CDRs.
The Charging Characteristics field allows the operator to apply different kind of charging methods in the CDRs. A subscriber may have Charging Characteristics assigned to his subscription. These characteristics can be supplied by the HLR to the SGSN as part of the subscription information, and, upon activation of a PDP context, the SGSN forwards the charging characteristics to the GGSN on the Gn / Gp reference point according to the rules specified in Annex A of TS 32.251 [11].
This information can be used by the GSNs to activate CDR generation and control the closure of the CDR or the traffic volume containers (see clause 5.1.2.2.23) and is included in CDRs transmitted to nodes handling the CDRs via the Ga reference point. It can also be used in nodes handling the CDRs (e.g., the CGF or the billing system) to influence the CDR processing priority and routing.
These functions are accomplished by specifying the charging characteristics as sets of charging profiles and the expected behaviour associated with each profile.
The interpretations of the profiles and their associated behaviours can be different for each PLMN operator and are not subject to standardisation. In the present document only the charging characteristic formats and selection modes are specified.
The functional requirements for the Charging Characteristics as well as the profile and behaviour bits are further defined in normative Annex A of TS 32.251 [11], including the definitions of the trigger profiles associated with each CDR type.
The format of charging characteristics field is depicted in Figure 4. Px (x =0..3) refers to the Charging Characteristics Profile index. Bits classified with a “B” may be used by the operator for non-standardised behaviour (see Annex A of TS 32.251 [11]).
Right, well hopefully next time someone goes looking for this info you’ll find it a bit more easily than I did!
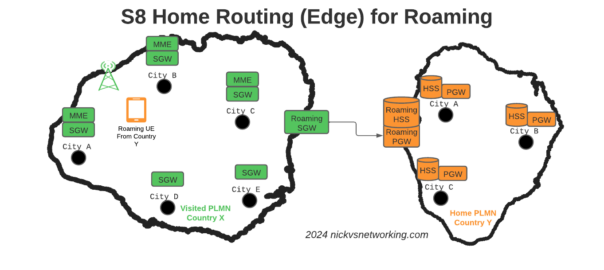
The S8 Home Routing approach for LTE Roaming works really well, as more and more operators are switching off their legacy circuit switched 2G/3G networks and shifting to LTE & VoLTE for roaming, we’re seeing more an more S8-HR deployments.
When LTE was being standardised in 2008, Local Breakout (LBO) and S8 Home Routing were both considered options for how roaming may look. Fast forward to today, and S8 Home routing is the only way roaming is done for modern deployments.
In light of this, there are some “best practices” in an “all S8 Home Routed” world, we’ve developed, that I thought I’d share.
The Basics
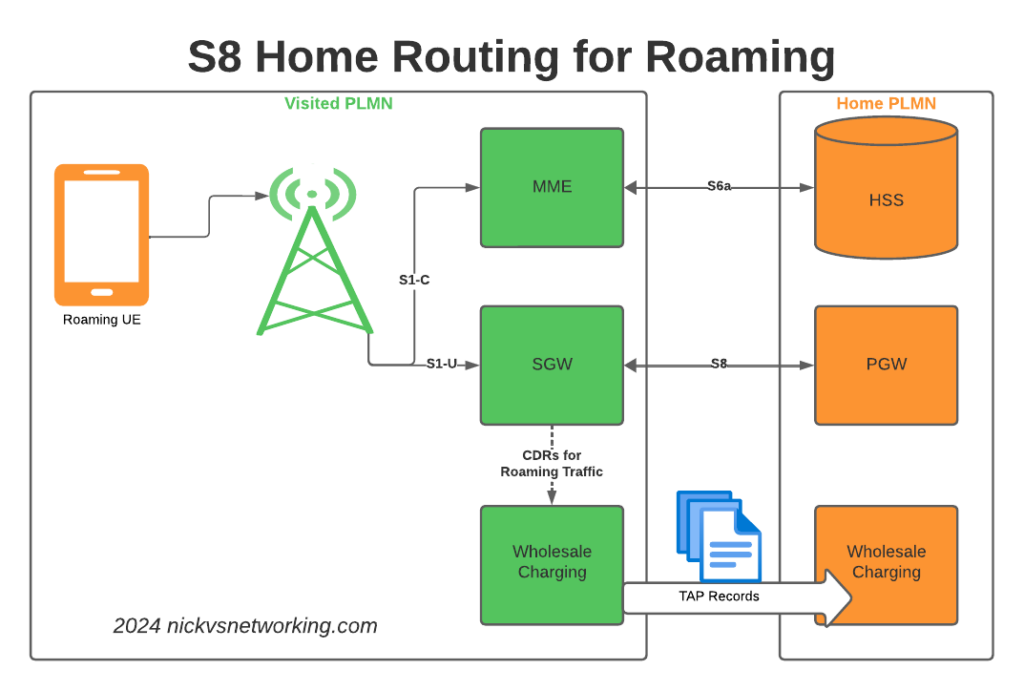
When roaming, the SGW in the Visited Network, sends user traffic back to the PGW in the Home Network.
This means Online/Offline charging, IMS, PCRF, etc, is all done in the Home PLMN. As long as data packets can get from the SGW in the Visited PLMN to the PGW in the Home PLMN, and authentication flows from the Visited MME to the HSS in the Home PLMN, you’re golden.
The Constraints
Of course real networks don’t look as simple as this, in reality a roaming scenario for a visited network has a lot more nodes, which need to be
Building Distributed Packet Core & IMS
Virtualization (VNF / CNF) has led operators away from “big iron” hardware for Packet Core & IMS nodes, towards software based solutions, which in turn offer a lot more flexibility.
Best practice for design of User Plane is to keep the the latency down, by bringing the user plane closer to the user (the idea of “Edge” UPFs in 5GC is a great example of this), and the move away from “big iron” in central locations for SGW and PGW nodes has been the trend for the past decade.
So to achieve these goals in the networks we build, we geographically distribute the core network.
This means we’ve got quite a few S-GW, P-GW, MME & HSS instances across the network. There’s some real advantages to this approach:
From a redundancy perspective this allows us to “spread the load” and build far more resilient networks. A network with 20 smaller HSS instances spread around the country, is far more resilient than 2 massive ones, regardless of how many power feeds or redundant disks it may have.
This allows us to be more resource efficient. MNOs have always provisioned excess capacity to cater for the loss of a node. If we have 2 MMEs serving a country, then each node has to have at least 50% capacity free, so if one MME were to fail, the other MME could handle the additional load it from it’s dead friend. This is costly for resources. Having 20 MMEs means each MME has to have 5% capacity free, to handle the loss of one MME in the pool.
It also forces our infrastructure teams to manage infrastructure “as cattle” rather than pets. These boxes don’t get names or lovingly crafted, they’re automatically spun up and destroyed without thinking about it.
For security, we only use internal IP addresses for the nodes in our packet core, this provides another layer of protection for the “crown jewels” of our network, so no one messing with BGP filtering can accidentally open the flood gates to our core, as one US operator learned leaving a GGSN open to the world leading to the private information for 100 million customers being leaked.
What this all adds to, is of course, the end user experience. For the end subscriber / customer, they get a better experience thanks to the reduced latency the connection provides, better uptime and faster call setup / SMS delivery, and less cost to deliver services.
I love this approach and could prothletise about it all day, but in a roaming context this presents some challenges.
The distributed networks we build are in a constant state of flux, new capacity is being provisioned in some areas, nodes things decommissioned in others, and our our core nodes are only reachable on internal IPs, so wouldn’t be reachable by roaming networks.
Our Distributed-Core Roaming Solution
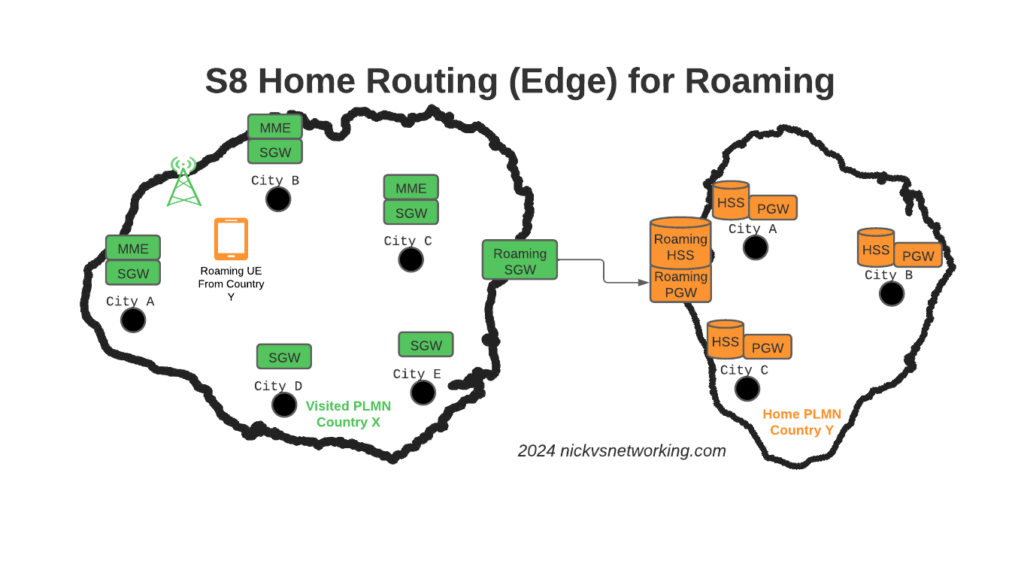
To resolve this we’ve taken a novel approach, we’ve deployed a pair of S-GWs we call the “Roaming SGWs”, and a pair of P-GWs we call the “Roaming PGWs”, these do have public IPs, and are dedicated for use only by roaming traffic.
We really like this approach for a few reasons:
It allows us to be really flexible do what we want inside the network, without impacting roaming customers or operators who use our network for roaming. All the benefits I described from the distributed architectures can still be realised.
From a security standpoint, only these SGW/PGW pairs have public IPs, all the others are on internal IPs. This good for security – Our core network is the ‘crown jewels’ of the network and we only expose an edge to other providers. Even though IPX networks are supposed to be secure, one of the largest IPX providers had their systems breached for 5 years before it was detected, so being almost as distrustful of IPX traffic as Internet traffic is a good thing. This allows us to put these PGWs / SGWs at the “edge” of our network, and keep all our MMEs, as well as our on-net PGW and SGWs, on internal IPs, safe and secure inside our network.
For charging on the SGWs, we only need to worry about collecting CDRs from one set of SGWs (to go into the TAP files we use to bill the other operators), rather than running around hoovering up SGW CDRs from large numbers of Serving Gateways, which may get blown away and replaced without warning.
Of course, there is a latency angle to this, for international roaming, the traffic has to cross the sea / international borders to get to us. By putting it at the edge we’re seeing increased MOS on our calls, as the traffic is as close to the edge of the network as can be.
Caveat: Increased S11 Latency on Core Network sites over Satellite
This is probably not relevant to most operators, but some of our core network sites are fed only by satellite, and the move to this architecture shifted something: Rather than having latency on the S8 interface from the SGW to the PGW due to the satellite hop, we’ve got latency between the MME and the SGW due to the satellite hop.
It just shifts where in the chain the latency lies, but it did lead to us having to boost some timers in the MME and out of sequence deliver detection, on what had always been an internal interface previously.
Evolution to 5G Standalone Roaming
This approach aligns to the Home Routed options for 5G-SA roaming; UPF chaining means that the roaming traffic can still be routed, as seems to be the way the industry is going.
SA roaming is in its infancy, without widely deployed SA networks, we’re not going to see common roaming using SA for a good long while, but I’ll be curious to see if this approach becomes the de facto standard going forward.
Where to from here?
We’re pretty happy with this approach in the networks we’ve been building.
So far it’s made IREG testing easier as we’ve got two fixed points the IPX needs to hit (The DRAs and the SGWs) rather than a wide range of networks.
Operators with a vast number of APNs they need to drop into different VRFs may have to do some traffic engineering here – Our operations are generally pretty flat, but I can see where this may present some challenges for established operators shifting their traffic.
I’d be keen to hear if other operators are taking this approach and if they’ve run into any issues, or any issues others can see in this, feel free to drop a comment below.
Having rated CDRs in CGrateS is great, but in reality, you probably want to get them into a billing system, CSV file, S3 bucket, CRM, invoice, Grafana, SQL table, etc, etc.
The Event Exporter Service (EES (previously called CDRe)) handles exporting CDRs from CGrateS.
Like everything in CGrateS, it’s highly configurable, and, again, like everything in CGrateS, supports every combination of services you can think of, plus a stack you haven’t thought of.
CDRs can be exported one of two ways, in real time, as the CDR is generated (online), or after the fact, exporting from the database containing the CDRs (offline).
Exporting in realtime (online) is a great option if you don’t want (or need) to store the CDRs in CGrateS; if you’re just using CGrateS to rate calls and spit them into a seperate system, this is a fantastic option, as it allows your CGrateS instances to remain light and not get clogged up with lots of old CDRs – That said, of course you can export the CDRs in realtime and still store them in CGrateS, that’s also a totally valid approach as well.
The more traditional approach is offline CDR export, where periodically or when an event is triggered, you scrape up a pile of CDRs and send them to your external systems.
For both options, we’ll need to define at least one exporter in our cgrates.json config file. For this example we’ll define a HTTP POST that we will trigger for realtime (online) CDR exporting, and a CSV file we dump to periodically when called from the API.
So first things first, we enable the EES module in the config:
"ees": {
"enabled": true,
"exporters": [
]
}
We’ll start with defining one exporter, named CSVExporter, that will output files to a folder named “testCSV” in the /tmp/ directory, but you can plonk these files wherever you like:
We’ve got a lot of different types of export available to us, but type *file_csv is the easiest, so that’s where we’ll start.
Setting synchronous to true will mean we’ll only run one export job at a time, but it also means we’ll get back the result via the API, which will allow us to keep track of the ID of the last record we updated, so we don’t export the same record multiple times, more on this later.
Flags allows us to, if we wanted, bounce the event through AttributeS, for example, by adding *attributes to the flags, but in this case, it’s just logging to syslog.
Of course, just enabling ees won’t actually send calls to it, we’ll need to add “ees_conns“: [“*localhost”], to “apiers”: and “cdrs” so they know to bounce the events through it:
If you’ve already got CDRs on your system from our previous tutorial, fantastic, but if not, let’s get up and running with a quick and dirty script to define some destinations, a charger, an account balance and then use some of the balance to generate a CDR:
import cgrateshttpapi
import pprint
import uuid
import datetime
now = datetime.datetime.now()
CGRateS_Obj = cgrateshttpapi.CGRateS('localhost', 2080)
#Define Destinations
CGRateS_Obj.SendData({'method':'ApierV2.SetTPDestination','params':[{"TPid":'cgrates.org',"ID":"Dest_AU_Mobile","Prefixes":["614"]}]})
#Load TariffPlan we just defined from StorDB to DataDB
CGRateS_Obj.SendData({"method":"APIerSv1.LoadTariffPlanFromStorDb","params":[{"TPid":'cgrates.org',"DryRun":False,"Validate":True,"APIOpts":None,"Caching":None}],"id":0})
#Define default Charger
print(CGRateS_Obj.SendData({"method": "APIerSv1.SetChargerProfile","params": [{"Tenant": "cgrates.org","ID": "DEFAULT",'FilterIDs': [],'AttributeIDs' : ['*none'],'Weight': 0,}]}))
account = "Nick_Test_123"
#Add a balance to the account with type *sms with 100 sms events
pprint.pprint(CGRateS_Obj.SendData({"method": "ApierV1.SetBalance","params": [{"Tenant": "cgrates.org","Account": account,"BalanceType": "*sms","DestinationIDs": 'Dest_NZ_Mobile;Dest_AU_Mobile',"Categories": "*any","Balance": {"ID": "100_SMS_Bundle_AU_NZ_Mobile","Value": 100,"Weight": 25}}]}))
#Process CDR Event for a single SMS
pprint.pprint(CGRateS_Obj.SendData({"method": "CDRsV2.ProcessExternalCDR","params": [{"OriginID": str(uuid.uuid1()),"ToR": "*sms","RequestType": "*pseudoprepaid","AnswerTime": now.strftime("%Y-%m-%d %H:%M:%S"),"SetupTime": now.strftime("%Y-%m-%d %H:%M:%S"),"Tenant": "cgrates.org","Account": account,"Destination" : "61412345678","Usage": "1",}]}))
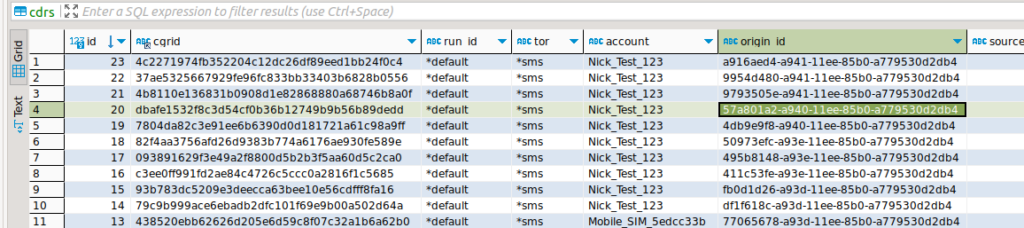
Right, with that out of the way, we should now have something in our CDRs table, a quick SQL query confirms this is the case:
So, as you may have guessed, we’ve called the ExportCDRs API endpoint, we’ve specified which ExporterIDs we want to reference (these link back to the objects in the config, and the one we have defined currently is named CSVExporter).
Setting Verbose: True means that CGrateS gives us back a lot of info from the API call, here’s what we get back:
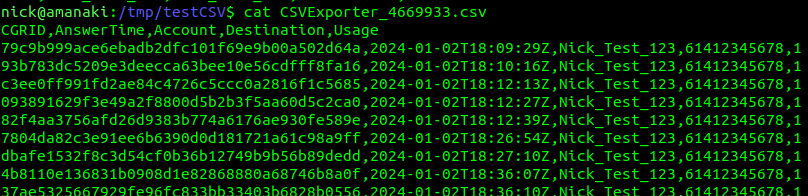
Now that looks pretty positive, we got 12 events of SMS usage exported, which we can see in the file /tmp/testCSV/CSVExporter_21e9bc2.csv – and if we cat out the file, yeap, there’s all the CDRs.
But it’s a bit of a mess, there’s a lot of fields in there, so let’s adjust what goes into the CSV.
Let’s start by filtering what goes into the exporter, to only give us SMS events, of course you could adjust the filters here to target exporting only the records you want, based on anything you can define with Filters (and there’s a lot you can define with filters).
Now we’re only exporting SMS records, so let’s clean up the output of the CSV to just give us the data we want, which is the CDR ID, time, account, destination and usage.
Now after a restart of CGrateS, our exports look like this:
Stunning, truly beautiful, look at that output!
Right, well you may at this point have noticed a problem if you’ve run this more than once. The problem is that is every time we run this, we get all the CDRs since the beginning of time.
But where filtering by date/time falls down, is that if an offline CDR of a call on Monday, only got ingested on Tuesday, it would be missed by the export.
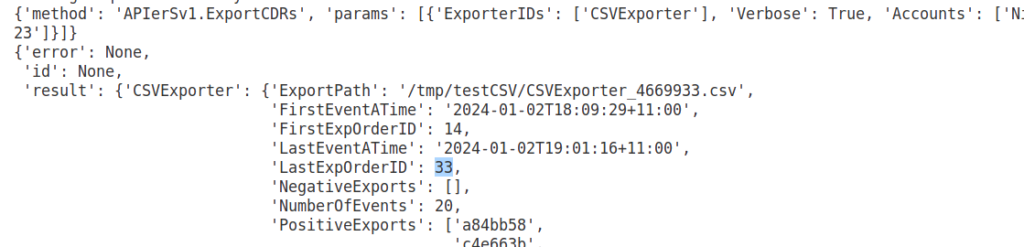
But, setting Verbose: True on the ExportCDRs API call gives us a handy trick, we’ve been told what the highest ID in the CDRs table we just exported in the response from the API in LastExpOrderID field.
If we jump over to the SQL database we use for StorDB, we can see that 33 is the ID of the highest CDR in the system.
So let’s try something, let’s run the exporter again, but this time let’s get all the CDRs where the ID is higher than 33:
#Process CDR Event for a single SMS
pprint.pprint(CGRateS_Obj.SendData({"method": "CDRsV2.ProcessExternalCDR","params": [{"OriginID": str(uuid.uuid1()),"ToR": "*sms","RequestType": "*pseudoprepaid","AnswerTime": now.strftime("%Y-%m-%d %H:%M:%S"),"SetupTime": now.strftime("%Y-%m-%d %H:%M:%S"),"Tenant": "cgrates.org","Account": account,"Destination" : "61412345678","Usage": "1",}]}))
#Trigger export where the OrderID is above 33
result = CGRateS_Obj.SendData({"method":"APIerSv1.ExportCDRs","params":[
{"ExporterIDs": ["CSVExporter"],
"Verbose" : True,
"ExtraArgs" : {
"OrderIDStart" : int(33),
},
"Accounts" : [account]}
]})
pprint.pprint(result)
Boom, now if we have a look at the output we can see the export covered two records, and the last ID was 35.
So as long as we keep track of the LastExpOrderID value, and feed that as in input every time we run ExportCDRs, we can ensure we never miss a CDR, and never get the same CDR twice.
I got an email the other day asking a simple question:
How do I know if a subscriber is VoLTE roaming or not when they send an SMS to charge for it?
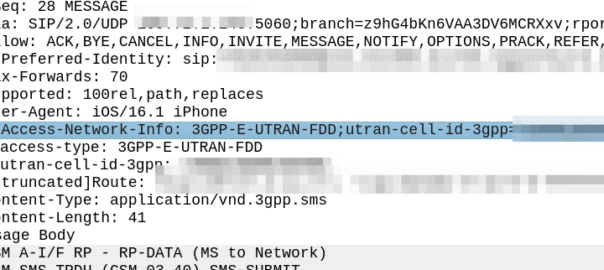
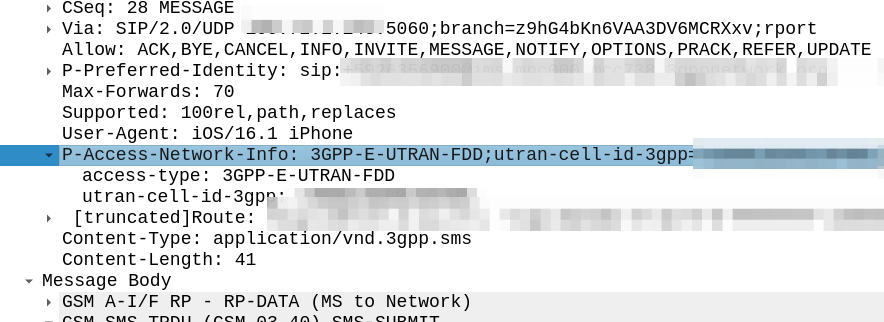
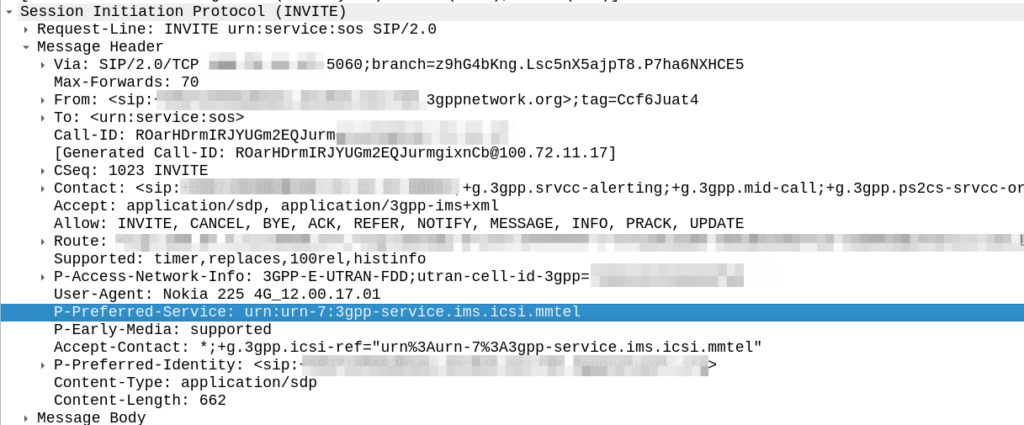
My immediate reaction was to look at the SIP headers, P-Access-Network-Info will tell you where the subscriber is located, end of.
Right?
Well not quite, this will tell the SMSc the location of the subscriber sending the SMS. If the PLMN in the P-Access-Network-Info != the home PLMN, the sub is roaming.
But does this information get passed to the OCS / OFCS?
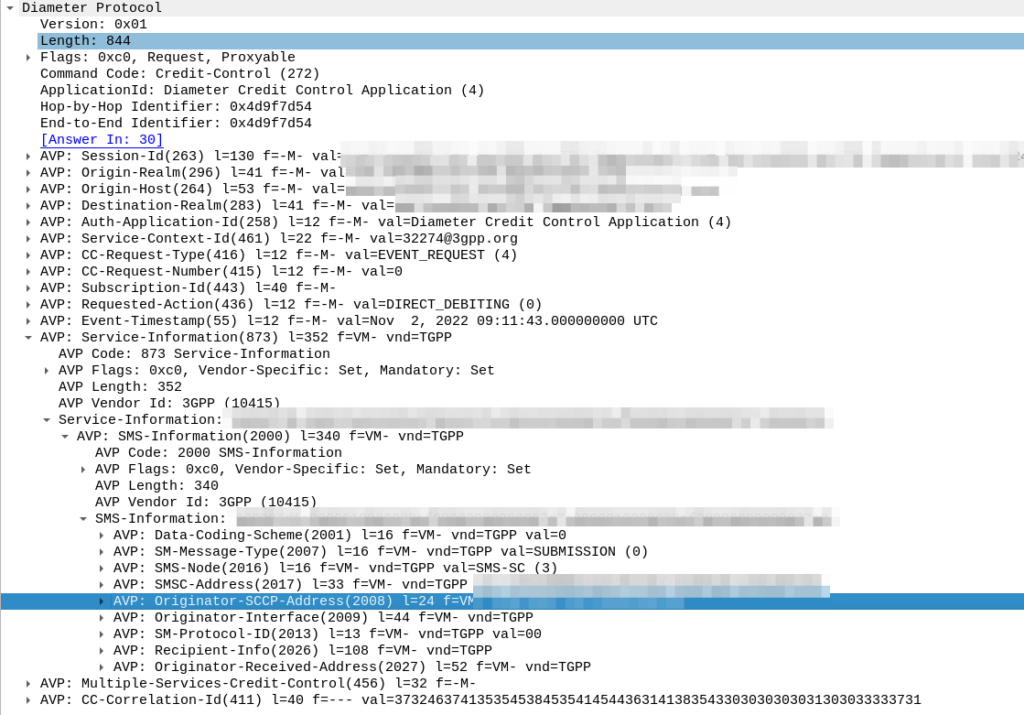
The SMSc uses “Event based charging” to perform credit control, so let’s have a look at what AVPs are present in the Credit Control Request from the SMSc:
Hmm, the SMS-Information AVP (2000) contains a bunch of information about the SMS being sent, but I don’t see anything about the location of the sender in there.
Originator-Interface is just set to “SIP”, of course in a 2G/3G roaming scenario the Originator-SCCP-Address would be that of the Visited PLMN, but for us it is our SCCP address.
Maybe the standard allows for an additional optional AVP in the SMS-Information-AVP we’re missing? Let’s check TS 32.299:
Nope.
So how to deal with this?
While the standards aren’t totally clear on this, we added an IMS-Info AVP and inside that populated the Access-Network-Information directly from the SIP header, and then picked that off inside our OCS in order to apply the correct rules.
Android, being open source, allows us to see how this logic works, and it’s important for operators to understand this logic, as it’s what dictates the behavior in many scenarios.
It’s important to note that I’m not covering Apple here, this information is not publicly available to share for iOS devices, so I won’t be sharing anything on this – Apple has their own ecosystem to handle emergency calling, if you’re from an operator and reading this, I’d suggest getting in touch with your Apple account manager to discuss it, they’re always great to work with.
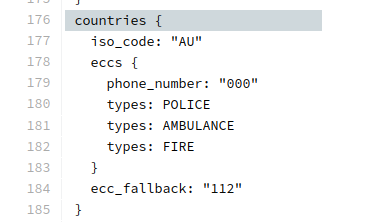
The Android Open Source Project has an “emergency number database”. This database has each of the emergency phone numbers and the corresponding service, for each country.
This file can be read at packages/services/Telephony/ecc/input/eccdata.txt on a phone with engineering mode.
Let’s take a look what’s in mainline Android for Australia:
In our last post we looked at Actions and ActionPlans, and one of the really funky things we can do is setting ActionPlans to trigger on a time schedule or setting ActionTriggers to trigger on an event.
We’re going to build on the examples we had on the last post, so we’ll assume your code is up to the point where we’ve added a Signup Bonus to an account, using an ActionPlan we assigned when creating the account.
In this post, we’re going to create an action that charges $6, called “Action_Monthly_Charge“, and tie it to an ActionPlan called “ActionPlan_Monthly_Charge“, but to demo how this works rather than charging this Monthly, we’re going to charge it every minute.
Then with our balances ticking down, we’ll set up an ActionTrigger to trigger when the balance drops below $95, and alert us.
Defining the Monthly Charge Action
The Action for the Monthly charge will look much like the other actions we’ve defined, except the Identifier is *debitso we know we’re deducting from the balance, and we’ll log to the CDRs table too:
Next we’ll need to wrap this up into an ActionPlan, this is where some of the magic happens. Inside the action plan we can set a once off time, or a recurring time, kinda like Cron.
We’re setting the time to *every_minute so things will happen quickly while we watch, this action will get triggered every 60 seconds. In real life of course, for a Monthly charge, we’d want to trigger this Action monthly, so we’d set this value to *monthly. If we wanted this to charge on the 2nd of the month we’d set the MonthDays to “2”, etc, etc.
If you think the accounts will start getting debited every 60 seconds after applying this, you’d be wrong, we need to associate this ActionPlan with an Account first, this is how we control which accounts get which ActionPlans tied to them, to do this we’ll use the SetAccout API again we’ve been using to create accounts:
Well, for starters the ActionPlan named “ActionPlan_Signup_Bonus” is going to be triggered, as in the ActionPlan it’s Timing is set to *asap, so CGrateS will apply the corresponding Action (“Action_Add_Signup_Bonus“) right away, which will credit the account $99.
But a minute after that, we’ll trigger the ActionPlan named “ActionPlan_Monthly_Charge”, as the timing for this is set to *every_minute, when the Action “Action_Monthly_Charge” is triggered, it’s going to be deducting $6 from the balance.
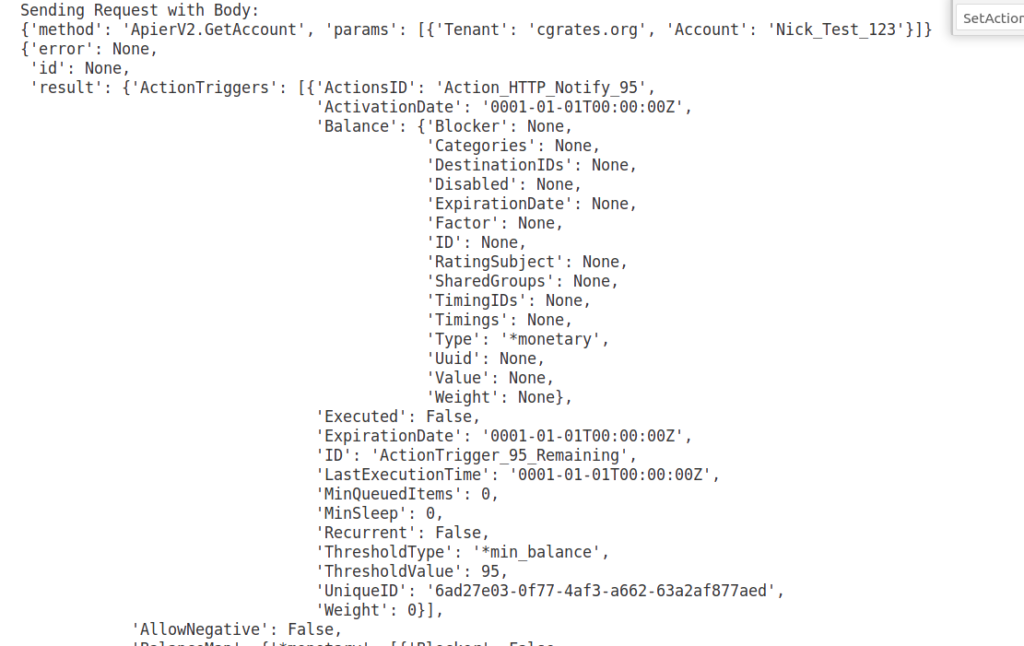
We can check this by using the GetAccount API:
# Get Account Info
pprint.pprint(CGRateS_Obj.SendData({'method': 'ApierV2.GetAccount', 'params': [
{"Tenant": "cgrates.org", "Account": str(Account)}]}))
You should see a balance of $99 to start with, and then after 60 seconds, it should be down to $93, and so on.
Triggering Actions based on Balances with ActionTriggers
Okay, so we’ve set up recurring charges, now let’s get notified if the balance drops below $95, we’ll start, like we have before, with defining an Action, this will log to the CDRs table, HTTP post and write to syslog:
Now we’ll define an ActionTrigger to check if the balance is below $95 and trigger our newly created Action (“Action_HTTP_Notify_95“) when that condition is met:
We’ve defined the ThresholdType of *min_balance, but we could equally set this to ThresholdType to *max_balance, *balance_expired or trigger when a certain Counter has been triggered enough times.
Adding an ActionTrigger to an Account
Again, like the ActionPlan we created before, before the ActionTrigger we just created will be used, we need to associate it with an Account, for this we’ll use the AddAccountActionTriggers API, specify the Account and the ActionTriggerID for the ActionTrigger we just created.
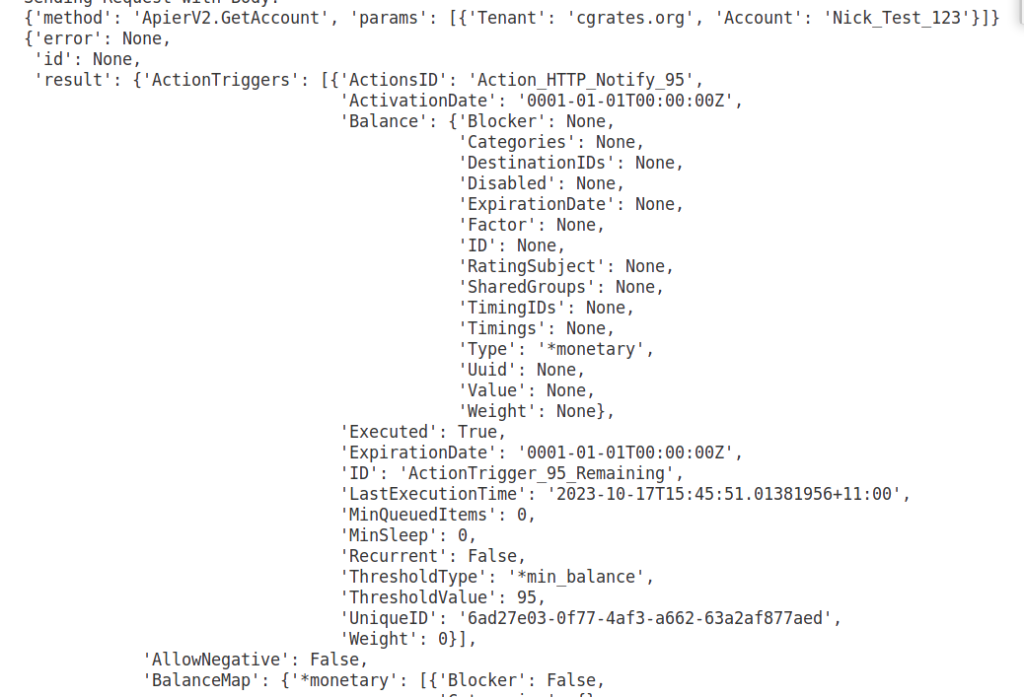
If we run this all together, creating the account with the “ActionPlan_Signup_Bonus” will give the account a $99 Balance. But after 60 seconds, “ActionPlan_Monthly_Charge” will kick in, and every 60 seconds after that, at which point the balance will get to below $95 when CGrateS will trigger the ActionTrigger “ActionTrigger_95_Remaining” and get the HTTP POST to the HTTP endpoint and log entry:
We can check on this using the ApierV2.GetAccount method, where we’ll see the ActionTrigger we just defined.
Checking out the LastExecutionTime we can see if the ActionTrigger been triggered or not.
So using this technique, we can notify a customer when they’ve used a certain amount of their balance, but we can lock out Accounts who have spent more than their allocated spend limit by setting an Action that suspends the Account once it reaches a certain level. We notify customers when balance expires, or if a certain number of counters has been triggered.
In our last post we added a series of different balances to an account, these were actions we took via the API specifically to add a balance.
But there’s a lot more actions we may want to do beyond just adding balance.
CGrateS has the concept of “Actions” which are, as the name suggests, things we want to do to the system.
Some example Actions would be:
Adding / Deducting / Resetting a balance
Adding a CDR log
Enable/Disable an account
Sending HTTP POST request or email notification
Deleting / suspending account
Transferring balances
We can run these actions on a timed basis, or when an event is triggered, and group Actions together to run multiple actions via an ActionTrigger, this means we can trigger these Actions, not just by sending an API request, but based on the state of the subscriber / account.
Let’s look at some examples,
We can define an Action named “Action_Monthly_Fee” to debit $12 from the monetary balance of an account, and add a CDR with the name “Monthly Account Fee” when it does so. We can use ActionTriggers to run this every month on the account automatically.
We can define an Action named “Usage_Warning_10GB” to send an email to the Account owner to inform them they’ve used 10GB of usage, and use ActionTriggers to send this when the customer has used 10GB of their *data balance.
Let’s start basic; to sweeten the deal for new Accounts, we’ll give them $99 of balance to use in the first month they have the service. Rather than hitting the AddBalance API, we’ll define an Action named “Action_Add_Signup_Bonus” to credit $99 of monetary balance to an account.
If you go back to our last post, you should know what we’d need to do to add this balance manually with the AddBalance API, but let’s look at how we can create the same balance add functionality using Actions:
#Add a Signup Bonus of $99 to the account with type *monetary expiring a month after it's added
Action_Signup_Bonus = {
"id": "0",
"method": "ApierV1.SetActions",
"params": [
{
"ActionsId": "Action_Add_Signup_Bonus",
"Actions": [
{
"Identifier": "*topup","BalanceId": "Balance_Signup_Bonus",
"BalanceUuid": "",
"BalanceType": "*monetary",
"Directions": "*out",
"Units": 99,
"ExpiryTime": "*month",
"Filter": "",
"TimingTags": "",
"DestinationIds": "",
"RatingSubject": "",
"Categories": "",
"SharedGroups": "",
"BalanceWeight": 1200,
"ExtraParameters": "",
"BalanceBlocker": "false",
"BalanceDisabled": "false",
"Weight": 10
}
]}]}
pprint.pprint(CGRateS_Obj.SendData(Action_Signup_Bonus))
Alright, this should look pretty familiar if you’ve just come from Account Balances. You’ll notice we’re no longer calling, SetBalance, we’re now calling SetActions, to create the ActionsId with the name “Action_Add_Signup_Bonus“. In “Action_Add_Signup_Bonus” we’ve got an actions we’ll do when “Action_Add_Signup_Bonus” is called. We can define multiple actions, but for now we’ve only got one action defined, which has the Identifier (which defines what the action does) set to *topup to add balance. As you probably guessed, we’re triggering a top up, and setting the BalanceId, BalanceType, Units, ExpiryTime and BalanceWeight just as we would using SetBalance to add a balance.
So how do we use the Action we just created? Well, there’s a lot of options, but let’s start with the most basic – Via the API:
Boom, now we’ll get a CDR created when the Action is triggered.
But let’s push this a bit more and add some more steps in the Action:
As well as adding balance and putting in a CDR to record what we did, let’s also send a notification to our customer via an HTTP API (BYO customer push notification system) and log to Syslog what’s going on.
So what have we done here? We’ve made an ActionPlan named “Action_Add_Signup_Bonus”, which, when associated with an account, will run the Action “Action_Add_Signup_Bonus” as soon as it’s tied to the account, thanks to the Time “*asap“.
Now if we create or update an Account using the SetAccount method, we can set the ActionPlanIds to reference our “ActionPlan_Signup_Bonus” and it’ll be triggered straight away.
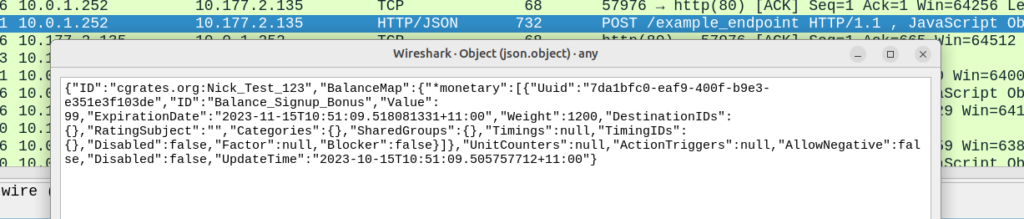
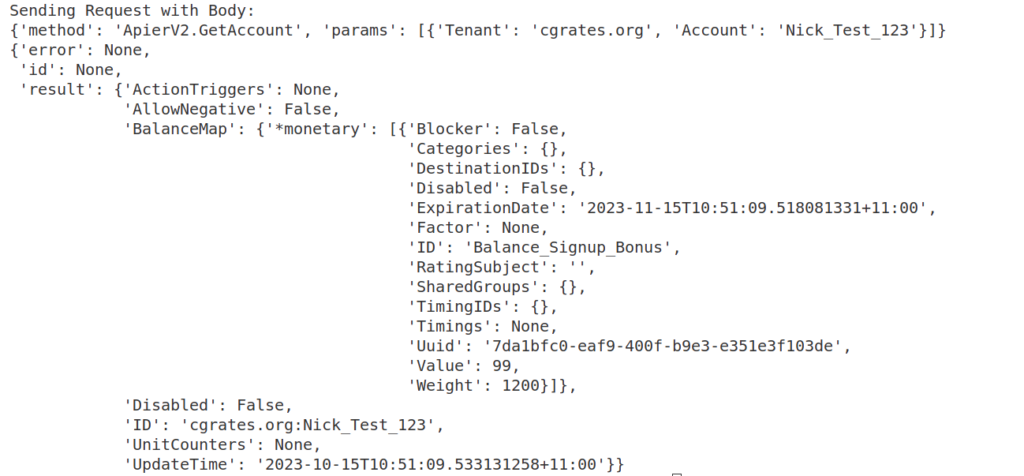
Now if we were to run a GetAccount API call, we’ll see the Account balance assigned that was created by the action Action_Add_Signup_Bonus which was triggered by ActionPlan assigned to the account:
But here’s where it gets interesting, in the ActionPlan we just defined the Time was set to “*asap“, which means the Action is triggered as soon as it was assigned to the account, but if we set the Time value to “*monthly“, the Action would get triggered every month, or *every_minute to trigger every minute, or *month_end to trigger at the end of every month.
I’m trying to keep these posts shorter as there’s a lot to cover. Stick around for our next post, we’ll look at some more ActionTriggers to keep decreasing the balance of the account, and setting up ActionTriggers to send a notification to the customer to tell them when their balance is getting low, or any other event based Action you can think of!
For example, an American visiting the UK, would have 911 on the Emergency Calling Codes list on their SIM card, but in the UK they dial 999 to reach emergency services.
There’s two angles to this, the first is if a roamer dials the emergency calling code of their home country, the other is if they dial the emergency calling code of the country they are in.
Let’s look at the first scenario, where the roamer dials the emergency calling code of their home country.
If our American in the UK abroad dials 911, that number is on the ECC list on the SIM, it’s still flagged as an emergency call, and just goes out with the standard urn:service:sos URN – The network never sees 911 or 999, just that it’s an SOS call that goes to the PSAP.
In this scenario, the fact the dialled number is not passed to the network is actually a positive, we get the intent that the user wants to reach emergency services, and route based on this.
But what if our American friend in need dials 999? That’s the correct number for the end user to dial in the UK after all, but if that’s not in their ECC list on the SIM / device, it’d go through as a regular call right?
If the call does not get flagged as an emergency call on the UE this has its own set of complications and considerations:
S8-Home Routing for VoLTE means that as the UE doesn’t know this is an emergency call, the call will get routed back to the home network. This means the call doesn’t go to the E-CSCF in the visited network, and would probably just get a message saying the number they’ve dialed is unavailable, this would be exactly as if they dialed 999 at home in the US.
But we have a fix for this! On each MME we can set a list of emergency numbers, which would allow our Britt’s phone to know on this network, what the emergency calling codes are, and route the 999 call to the local PSAP, rather than home routing it.
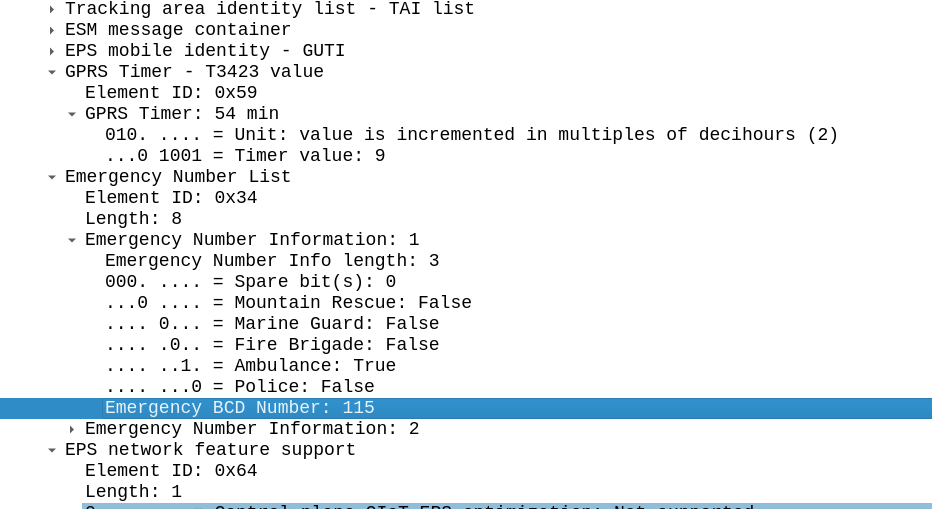
This information is jammed into the Emergency Number List IE in the NAS Attach Accept body.
This means our American visitor in the UK, would know about 999 from the ECC list configured in the roaming operator’s MME.
The purpose of this information element is to encode emergency number(s) for use within the country where the IE is received.
3GPP TS 24.008: 10.5.3.13 – Emergency Number List
Where this becomes more problematic is unauthenticated emergency calling.
For example, a our American visiting the UK, that is not roaming dials 999.
We’ll assume the UK and US operator don’t have a VoLTE roaming agreement because they’ve been kicking the can down the road when it comes to VoLTE roaming… This is super common scenario – last numbers I saw on this were last year with ~50 bilateral VoLTE agreements in place worldwide.
Because the phone is not attached to a local MME, the handset does not know that 999 is an emergency calling code (because it’s not on the SIM), after all, the only way it can get the Emergency Number List is from an MME, and not having been attached to an MME, means the phone does not have the ECC list for the country, so the the handset does not begin the emergency attach procedure to make the call.
Common sense prevails here, on the majority of phones and the majority of SIM profiles, codes like 112 or 911 are treated as emergency calls, but more obscure numbers, such as dialing 999 in the UK or 10111 for South African Police on a handset with US firmware, are not guaranteed to work. Generally dialing the Emergency Calling code in the home network would get you through to some emergency services (although as we talked about in the last post, this might get you routed to the wrong agency in countries where each agency has their own number).
A better way forward?
These days I don’t dial much (apart from if I’m making adjustments on the Step-by-Step exchange), when I call people I do it from contacts, hyperlinks, etc.
There is mountains of research to suggest that asking people to remember codes and phone numbers, is a struggle. A tourist who finds themselves in Tunisia in need of assistance, is unlikely to remember that it’s 190 for an Ambulance, and 198 for Fire.
Perhaps the ECC list on a phone should populate a page of icons from the emergency page on the phone, with the universal icon for each agency, that sends to the URN for that service type?
Countries with a single PSAP could have the URNs for each service type routed to the same place, while countries with seperated PSAPs for each service type, can route accordingly.
Likewise if a country does have a centralised PSAP for all call types, knowing the type that is selected would be useful, for example if the user has pressed fire and is not responsive when the call is answered, the best unit to dispatch would probably be a fire engine.