Even before 5G was released, the arms race to claim the “fastest” speeds on LTE, NSA and SA networks has continued, with pretty much every operator claiming a “first” or “fastest”.
I myself have the fastest 5G network available* but I thought I’d look at how big the values are we can put in for speed, these are the Maximum Bitrate Values (like AMBR) we can set on an APN/DNN, or on a Charging Rule.
*Measurement is of the fastest 5G network in an eastward facing office, operated by a person named Nick, in a town in Australia. Other networks operated by people other than those named Nick in eastward facing office outside of Australia were not compared.
The answer for Release 8 LTE is 4294967294 bytes per second, aka 4295 Mbps 4.295 Gbps.
Not bad, but why this number?
The Max-Requested-Bandwidth-DL AVP tells the PGW the max throughput allowed in bits per second. It’s a Unsigned32 so max value is 4294967294, hence the value.
But come release 15 some bright spark thought we may in the not to distant future break this barrier, so how do we go above this?
The answer was to bolt on another AVP – the “Extended-Max-Requested-BW-DL” AVP ( 554 ) was introduced, you might think that means the max speed now becomes 2x 4.295 Gbps but that’s not quite right – The units was shifted.
This AVP isn’t measuring bits per second it’s measuring kilobits per second.
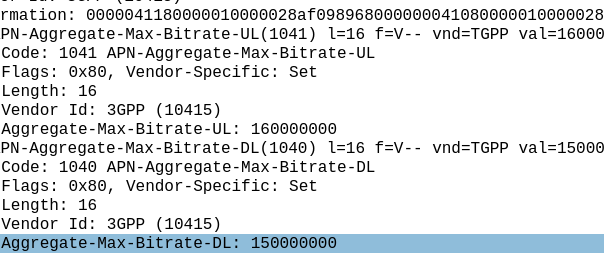
So the standard Max-Requested-Bandwidth-DL AVP gives us 4.3 Gbps, while the Extended-Max-Requested-Bandwidth gives us a 4,295 Gbps.
We add the Extended-Max-Requested-Bandwidth AVP (4295 Gbps) onto the Max-Requested Bandwidth AVP (4.3 Gbps) giving us a total of 4,4299.3 Gbps.
I started off just updating the SPN, OPN, etc, etc, but I had a suspicion there were still references.
I confirmed this pretty easily with Wireshark, first I started a trace in Wireshark of the APDUs: I enabled capturing on a USB Interface:
modprobe usbmon
Then we need to find where our card reader is connected, running ‘lsusb‘ lists all the USB devices, and you can see here’s mine on Bus 1, Device 49.
Then fired up Wireshark, selected USB Bus 01 to capture all the USB traffic on the bus.
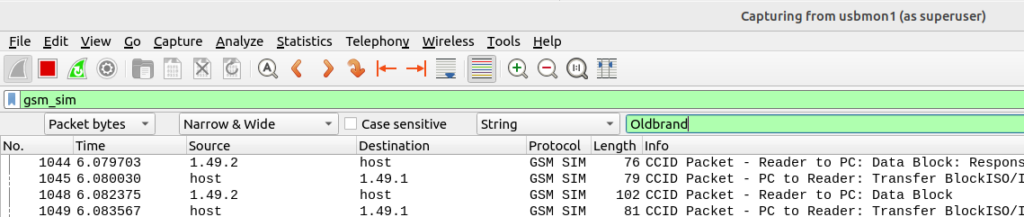
Then I ran the “export” command in PySIM to read the contents of all the files on the SIM, and jumped back over to Wireshark. (PySIM decodes most files but not all – Whereas this method just looks for the bytes containing the string)
From the search menu in Wireshark I searched the packet bytes for the string containing the old brand name, and found two more EFs I’d missed.
For anyone playing along at home, using this method I found references to the old brand name in SMSP (which contains the network name) and ADN (Which had the customer support number as a contact with the old brand name).
Short one, The other day I needed to add a Network Appearance on an SS7/SS7 M3UA linkset.
Network Appearances on M3UA links are kinda like a port number, in that they allow you to distinguish traffic to the same point code, but handled by different logical entities.
When I added the NA parameter on the Linkset nothing happened.
If you’re facing the same you’ll need to set:
cs7 multi-instance
In the global config (this is the part I missed).
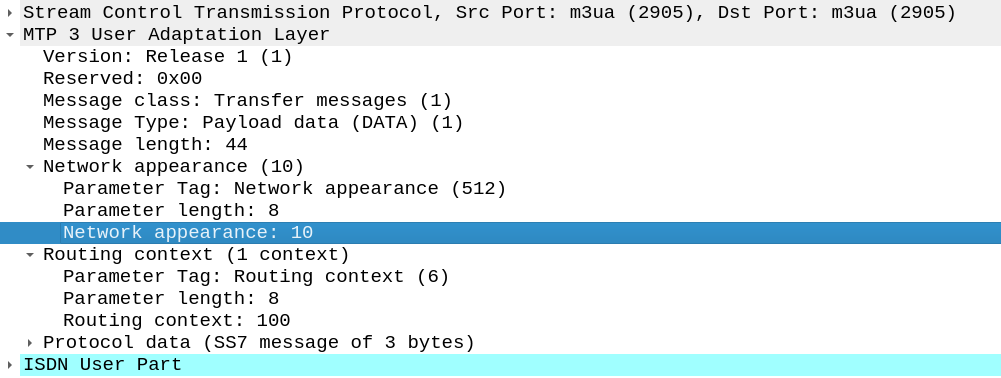
Then select the M3UA linkset you want to change and add the network-appearance parameter:
network-appearance 10
And bingo, you’ll start seeing it in your M3UA traffic:
The Binding Support Function is used in 4G and 5G networks to allow applications to authenticate against the network, it’s what we use to authenticate for XCAP and for an Entitlement Server.
Rather irritatingly, there are two BSF addresses in use:
If the ISIM is used for bootstrapping the FQDN to use is:
bsf.ims.mncXXX.mccYYY.pub.3gppnetwork.org
But if the USIM is used for bootstrapping the FQDN is
bsf.mncXXX.mccYYY.pub.3gppnetwork.org
You can override this by setting the 6FDA EF_GBANL (GBA NAF List) on the USIM or equivalent on the ISIM, however not all devices honour this from my testing.
In the past I had my iFCs setup to look for the P-Access-Network-Info header to know if the call was coming from the IMS, but it wasn’t foolproof – Fixed line IMS subs didn’t have this header.
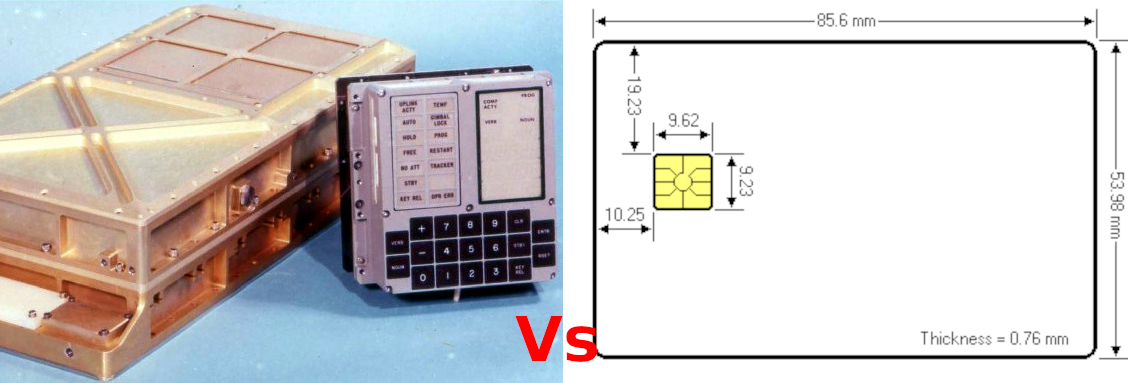
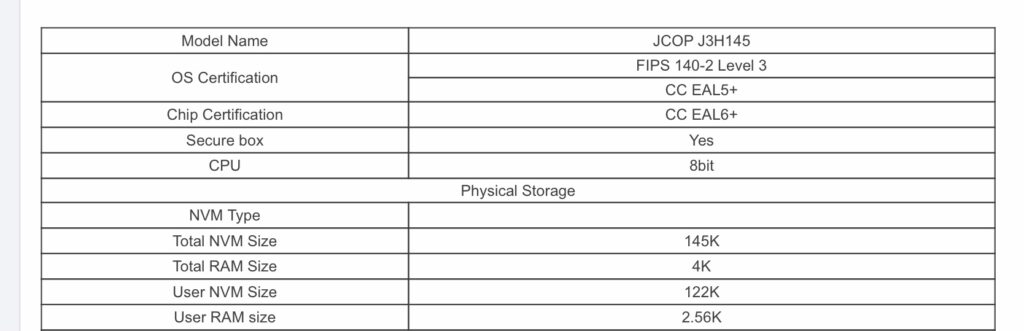
The first thing people learn about SIMs or the Smart Cards that the SIM / USIM app runs on, is that “There’s a little computer in the card”. So how little is this computer, and what’s the computing power in my draw full of SIMs?
So for starters the SIM manufacturers love their NDAs, so I can’t post the chip specifications for the actual cards in my draw, but here’s some comparable specs from a seller selling Java based smart cards online:
Specs for Smart Card
4K of RAM is 4069 bytes. For comparison the Apollo Guidance Computer had 2048 words of RAM, but each “word” was 16 bits (two bytes), so actually this would translate to 4069 bytes so equal with one of these smart cards in terms of RAM – So the smart card above is on par with the AGC that took humans to the moon in terms of RAM, althhough the SIMs would be a wee bit larger if they were also using magnetic core memory like the AGC!
The Nintendo Entertainment System was powered by a MOS Technology 6502, it had access to 2K of RAM, two the Smart Card has twice as much RAM as the NES, so it could get you to the moon and play Super Mario Bros.
What about comparing Non-Volatile Memory (Storage)? Well, the smart card has 145KB of ROM / NVM, while Apollo flew with 36,864 words of RAM, each word is two bits to 73,728 Bytes, so roughly half of what the Smart Card has – Winner – Smart Card, again, without relying on core rope memory like AGC.
SIM cards are clocked kinda funkily so comparing processor speeds is tricky. Smart Cards are clocked off the device they connect to, which feeds them a clock signal via the CLK pin. The minimum clock speed is 1Mhz while the max is 5Mhz.
Now I’m somewhat of a hoarder when it comes to SIM Cards; in the course of my work I have to deal with a lot of SIMs…
Generally when we’re getting SIMs manufactured, during the Batch Approval Process (BAP) the SIM vendor will send ~25 cards for validation and testing. It’s not uncommon to go through several revisions. I probably do 10 of these a year for customers, so that’s 250 cards right there.
Then when the BAP is done I’ll get another 100 or so production cards for the lab, device testing, etc, this probably happens 3 times a year.
So that’s 550 SIMs a year, I do clean out every so often, but let’s call it 1000 cards in the lab in total.
In terms of ROM that gives me a combined 141.25 MB, I could store two Nintendo 64 games, or one Mini CD of data, stored across a thousand SIM cards – And you thought installing software from a few floppies was a pain in the backside, imagine accessing data from 1000 Smart Cards!
What about tying the smart cards together to use as a giant RAM BUS? Well our 1000 cards give us a combined 3.91 MB of RAM, well that’d almost be enough to run Windows 95, and enough to comfortably run Windows 3.1.
Practical do do any of this? Not at all, now if you’ll excuse me I think it’s time I throw out some SIMs…
If you’ve ever worked in roaming, you’ll probably have had the misfortune of dealing with Transferred Account Procedures aka TAP files.
It’s used for billing a 2G GSM call right up to 5G data usage, if you use a service while roaming, somewhere in the world there’s a TAP file with your usage in it.
A brief history of TAP
TAP was originally specified by the GSMA in 1991 as a standard CDR interchange format between operators, for use in roaming scenarios.
Notice I said GSMA – Not 3GPP – This means there’s no 3GPP TS docs for this, it’s defined by the industry lobby group’s members, rather than the standards body.
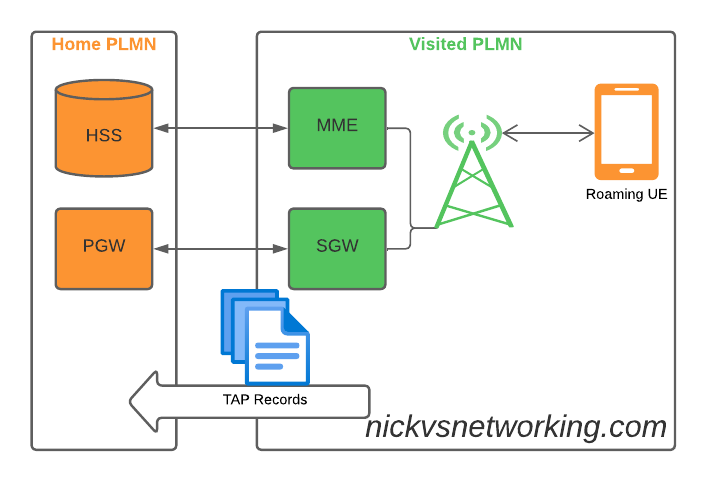
So what does this actually mean? Well, if you’re MNO A and a customer from MNO B roams into your network, all the calls, SMS and data consumed by the roaming subscriber from MNO B will need to be billed to MNO B, by you, MNO A.
If a network operator wants to get paid for traffic used on their network by roaming subscribers, they’d better send out a TAP file to the roamer’s home network.
TAP is the file format generated my MNO A and sent to MNO B, containing all the usage charges that subscribers from MNO B have racked up while roaming into your network.
These are broken down into “Transactions” (CDRs), for events like making a call, connecting a PDN session and consuming data, or sending a text.
In the beginning of time, GSM provided only voice calling service. This meant that the only services a subscriber could consume while roaming was just making/receiving voice calls which were billed at the end of each month. – This meant billing was equally simple, every so often the visisted network would send the TAP files for the voice calls made by subscribers visited other networks, to the home networks, which would markup those charges, and add them onto the monthly invoice for each subscriber who was roaming.
But of course today, calling accounts for a tiny amount of usage on the network, but this happened gradually while passing through the introduction of SMS, CAMEL services, prepaid services, mobile data, etc. For all these services that could be offered, the TAP format had to evolve to handle each of these scenarios.
As we move towards a flat IP architecture, where voice calls and SMS sent while roaming are just data, TAP files for 4G and 5G networks only need to show data transactions, so the call objects, CAMEL parameters and SMS objects are all falling by the wayside.
What’s inside a TAP File
TAP uses the most beloved of formats – ASN1 to encode the data. This means it is strictly formatted and rigidly specified.
Each file contains a Sequence Number which is a monotonically increasing number, which allows the receiver to know if any files have been missed between the file that’s being currently parsed, an the previous file.
They also have a recipient and sender TADIG code, which is a code allocated by GSMA that uniquely identifies the sender and the recipient of the file.
The TAP records exist in one of two common format, Notification Records and transferBatch records.
These files are exchanged between operators, in practice this means “Dumped on an FTP server as agreed between the two”.
TAP Notification Records
Notifications are the simplest of TAP records and are used when there aren’t any CDRs for roaming events during the time period the TAP file covers.
These are essentially blank TAP files generated by the visited network to let the home network know it’s still there, but there are no roaming subs consuming services in that period.
Notification files are really simple, let’s take a look as one shown as JSON:
When we have services to bill and records to charge, that’s when instead we generate a transferBatch record.
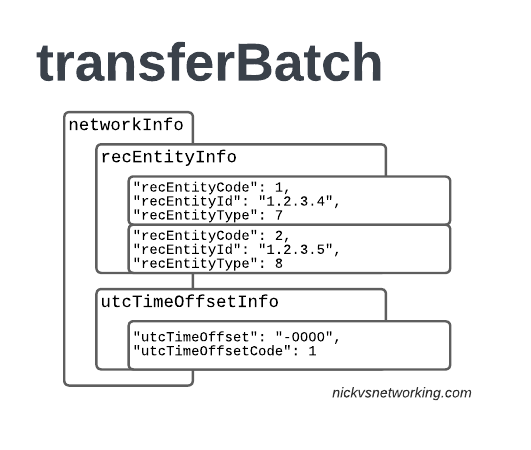
It looks something like this:
There’s a lot going on in here, so let’s break it down section by section.
accountingInfo
The accountingInfo section specifies the currency, exchange rate parameters.
Keep in mind a TAP record generated by an operator in the US, would use USD, while the receiver of the file may be a European MNO dealing in EUR.
This gets even more complicated if you’re dealing with more obscure currencies where an intermediary currency is used, that’s where we bring in SDRs (“Special Drawing Right”) that map to the dollar value to be charged, kinda – the roaming agreement defines how many SDRs are in a dollar, in the example below we’re not using any, but you do see it.
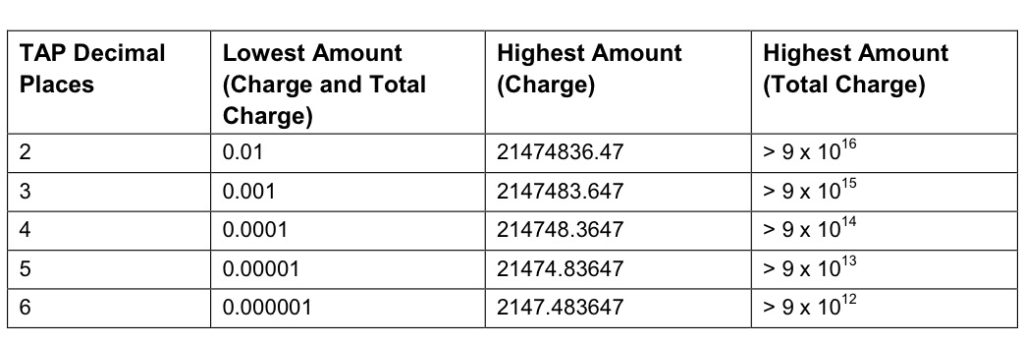
When it comes to numbers and decimal places, TAP doesn’t exactly make it easy.
Significant Digits are defined by counting the first number before the decimal point and all the numbers to the right of the decimal point, so for example the number 1.234 would be 4 significant digits (1 digit before the decimal point and 3 digits after it).
Decimal Places are not actually supported for the Value fields in the TAP file. This is tricky because especially today when roaming tariffs are quite low, these values can be quite small, and we need to represent them as an integer number. TAP defines decimal places as the number of digits after the decimal place.
When it comes to the maximum number of decimal places, this actually impacts the maximum number we can store in the field – as ASN1 strictly enforce what we put in it.
The auditControlInfo section contains the number of CDRs (callEventDetailsCount) contained in the TAP file, the timestamp of the first and last CDR in the file, the total charge and any tax charged.
All of the currency information was provided in the accountingInfo so this is just giving us our totals.
A CDR has 30 days from the time it was generated / service consumed by the roamer, to be baked into a TAP file. After this we can no longer charge for it, so it’s important that the earliestCallTimeStamp is not more than 30 days before the fileCreationTimeStamp seen in batchControlInfo.
batchControlInfo
The batchControlInfo section specifies the time the TAP file became available for transfer, the time the file was created (usually the same), the sequence number and the sender / recipient TADIG codes.
As mentioned earlier, we track sequence number so the receiver can know if a TAP file has been missed; for example if you’ve got TAP file 1 and TAP file 3 comes in, you can determine you’ve missed TAP file 2.
Now we’re getting to the meat & potatoes of our TAP record, the CDRs themselves.
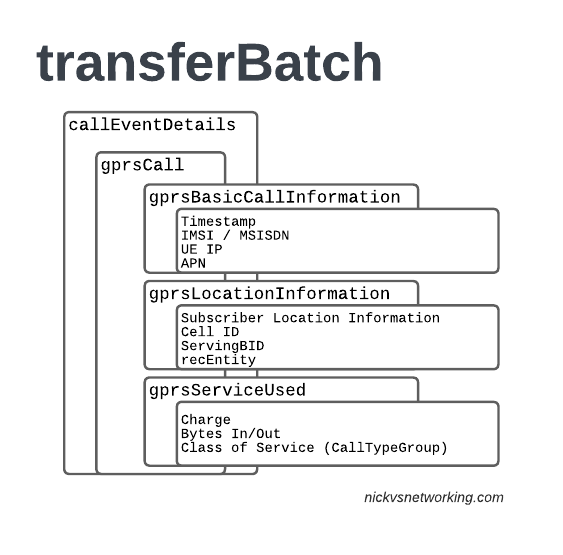
In LTE networks these are just records of data consumption, so let’s take a look inside the gprsCall records under callEventDetails:
In the gprsBasicCallInformation we’ve got as the name suggests the basic info about the data usage event. The time when the session started, the charging ID, the IMSI and the MSISDN of the subscriber to charge, along with their IP and the APN used.
Next up we have the gprsLocationInformation – rates and tariffs may be set based on the location of the subscriber, so we need to identify the area the sub was using the services to select correct tariff / rate for traffic in this destination.
The recEntity is the index number of the SGW / PGW used for the transaction (more on that later).
Next we have the gprsServiceUsed which, again as the name suggests, details the services used and the charge.
chargeDetailList contains the charged data (Made up of dataVolumeIncoming + dataVolumeOutgoing) and the cost.
The chargeableUnits indicates the actual data consumed, however most roaming agreements will standardise on some level of rounding, for example rounding up to the nearest Kilobyte (1024 bytes), so while a sub may consume 1025 bytes of data, they’d be billed for 2045 bytes of data. The data consumed is indicated in the chargeableUnits which indicates how much data was actually consumed, before any rounding policies where applied, while the amount that is actually charged (When taking into account rounding policies) isindicated inside Charged Units.
In the example below data usage is rounded up to the nearest 1024 bytes, 134390 bytes rounds up to the nearest 1024 gives you 135168 bytes.
As this is data we’re talking bytes, but not all bytes are created equal!
VoLTE traffic, using a QCI1 bearer is more valuable than QCI 9 cat videos, and TAP records take this into account in the Call Type Groups, each of which has a different price – Call Type Level 1 indicates the type of traffic, for S8 Home Routed LTE Traffic this is 10 (HGGSN/HP-GW), while Call Type Level 2 indicates the type of traffic as mapped to QCI values:
So Call Type Level 2 set to 20 indicates that this is “20 Unspecified/default LTE QCIs”, and Call Type Level 3 can be set to any value based on a defined inter-operator tariff.
recEntityType 7 means a PGW and contains the IP of the PGW in the Home PLMN, while recEntityType 8 means SGW and is the SGW in the Visited PLMN.
So this means if we reference recEntityCode 2 in a gprsCall, that we’re referring to an SGW at 1.2.3.5.
Lastly also got the utcTimeOffsetInfo to indicate the timezones used and assign a unique code to it.
Using the Records
We as humans? These records aren’t meant for us.
They’re designed to be generated by the Visited PLMN and sent to to the home PLMN, which ingests it and pays the amount specified in the time agreed.
Generally this is an FTP server that the TAP records get dumped into, and an automated bank transfer job based on the totals for the TAP records.
Testing of the TAP records is called “TADIG Testing” and it’s something we’ll go into another day, but in essence it’s validating that the output and contents of the files meet what both operators think is the contract pricing and specifications.
So that’s it! That’s what’s in a TAP record, what it does and how we use it!
GSMA are introducing BCE – Billing & Charging Evolution, a new standard, designed to last for the next 30+ years like TAP has. It’s still in its early days, but that’s the direction the GSMA has indicated it would like to go.
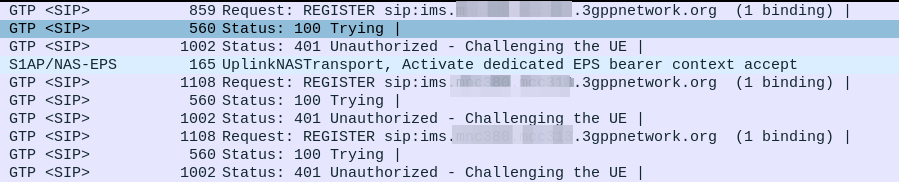
Everything was working on the IMS, then I go to bed, the next morning I fire up the test device and it just won’t authenticate to the IMS – The S-CSCF generated a 401 in response to the REGISTER, but the next REGISTER wouldn’t pass.
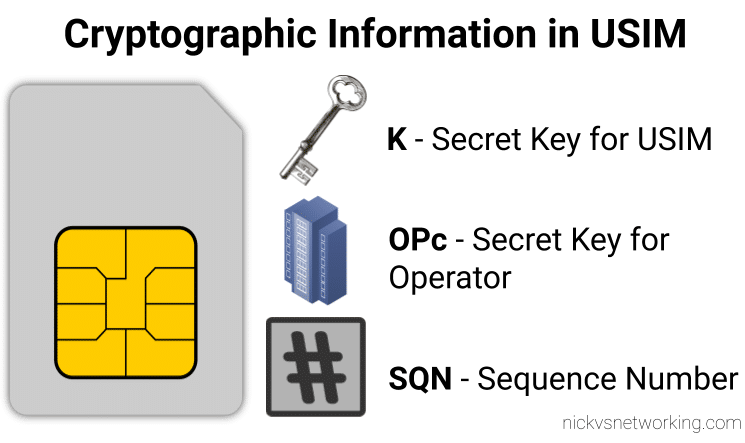
When we generate the vectors (for IMS auth and standard auth) one of the inputs to generate the vectors is the Sequence Number or SQN.
This SQN ticks over like an odometer for the number of times the SIM / HSS authentication process has been performed.
There is some leeway in the SQN – It may not always match between the SIM and the HSS and that’s to be expected. When the MME sends an Authentication-Information-Request it can ask for multiple vectors so it’s got some in reserve for the next time the subscriber attaches, and that’s allowed.
But there are limits to how far out our SQN can be, and for good reason – One of the key purposes for the SQN is to protect against replay attacks, where the same vector is replayed to the UE. So the SQN on the HSS can be ahead of the SIM (within reason), but it can’t be behind – Odometers don’t go backwards.
So the issue was with the SQN on the SIM being out of Sync with the SQN in the IMS, how do we know this is the case, and how do we fix this?
Well there is a resync mechanism so the SIM can securely tell the HSS what the current SQN it is using, so the HSS can update it’s SQN.
When verifying the AUTN, the client may detect that the sequence numbers between the client and the server have fallen out of sync. In this case, the client produces a synchronization parameter AUTS, using the shared secret K and the client sequence number SQN. The AUTS parameter is delivered to the network in the authentication response, and the authentication can be tried again based on authentication vectors generated with the synchronized sequence number.
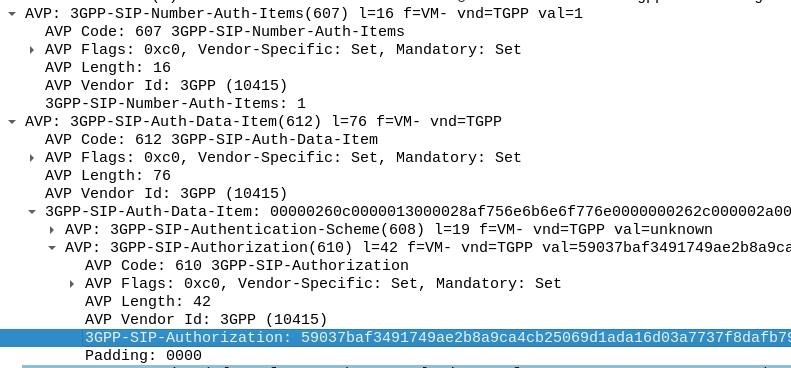
In our example we can tell the sub is out of sync as in our Multimedia Authentication Request we see the SIP-Authorization AVP, which contains the AUTS (client synchronization parameter) which the SIM generated and the UE sent back to the S-CSCF. Our HSS can use the AUTS value to determine the correct SQN.
SIP-Authorization AVP in the Multimedia Authentication Request means the SQN is out of Sync and this AVP contains the RAND and AUTN required to Resync
Note: The SIP-Authorization AVP actually contains both the RAND and the AUTN concatenated together, so in the above example the first 32 bytes are the AUTN value, and the last 32 bytes are the RAND value.
So the HSS gets the AUTS and from it is able to calculate the correct SQN to use.
Then the HSS just generates a new Multimedia Authentication Answer with a new vector using the correct SQN, sends it back to the IMS and presto, the UE can respond to the challenge normally.
Misunderstood, under appreciated and more capable than people give it credit for, is our PCRF.
But what does it do?
Most folks describe the PCRF in hand wavy-terms – “it does policy and charging” is the answer you’ll get, but that doesn’t really tell you anything.
So let’s answer it in a way that hopefully makes some practical sense, starting with the acronym “PCRF” itself, it stands for Policy and Charging Rules Function, which is kind of two functions, one for policy and one for rules, so let’s take a look at both.
Policy
In cellular world, as in law, policy is the rules.
For us some examples of policy could be a “fair use policy” to limit customer usage to acceptable levels, but it can also be promotional packages, services like “free Spotify” packages, “Voice call priority” or “unmetered access to Nick’s Blog and maximum priority” packages, can be offered to customers.
All of these are examples of policy, and to make them work we need to target which subscribers and traffic we want to apply the policy to, and then apply the policy.
Charging Rules
Charging Rules are where the policy actually gets applied and the magic happens.
It’s where we take our policy and turn it into actionable stuff for the cellular world.
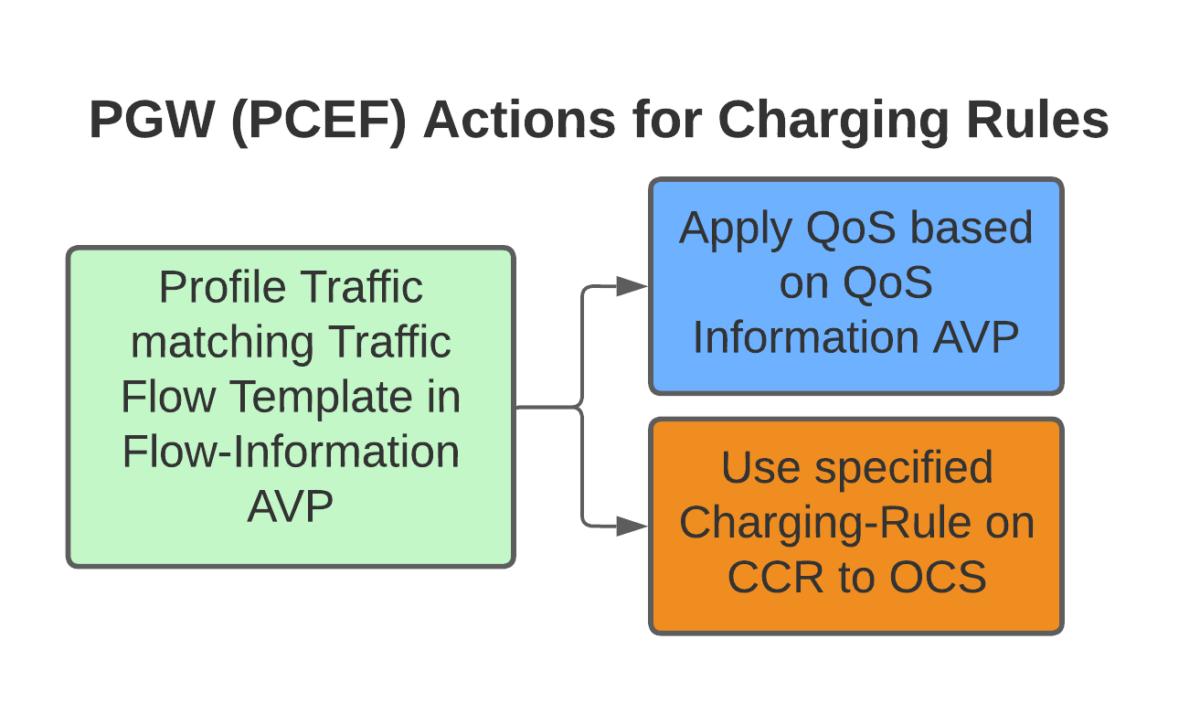
Let’s take an example of “unmetered access to Nick’s Blog and maximum priority” as something we want to offer in all our cellular plans, to provide access that doesn’t come out of your regular usage, as well as provide QCI 5 (Highest non dedicated QoS) to this traffic.
To achieve this we need to do 3 things:
Profile the traffic going to this website (so we capture this traffic and not regular other internet traffic)
Charge it differently – So it’s not coming from the subscriber’s regular balance
Up the QoS (QCI) on this traffic to ensure it’s high priority compared to the other traffic on the network
So how do we do that?
Profiling Traffic
So the first step we need to take in providing free access to this website is to filter out traffic to this website, from the traffic not going to this website.
Let’s imagine that this website is hosted on a single machine with the IP 1.2.3.4, and it serves traffic on TCP port 443. This is where IPFilterRules (aka TFTs or “Traffic Flow Templates”) and the Flow-Description AVP come into play. We’ve covered this in the past here, but let’s recap:
IPFilterRules are defined in the Diameter Base Protocol (IETF RFC 6733), where we can learn the basics of encoding them,
They take the format:
action dir proto from src to dst
The action is fairly simple, for all our Dedicated Bearer needs, and the Flow-Description AVP, the action is going to be permit. We’re not blocking here.
The direction (dir) in our case is either in or out, from the perspective of the UE.
Next up is the protocol number (proto), as defined by IANA, but chances are you’ll be using 17 (UDP) or 6 (TCP).
The from value is followed by an IP address with an optional subnet mask in CIDR format, for example from 10.45.0.0/16would match everything in the 10.45.0.0/16 network.
Following from you can also specify the port you want the rule to apply to, or, a range of ports.
Like the from, the tois encoded in the same way, with either a single IP, or a subnet, and optional ports specified.
And that’s it!
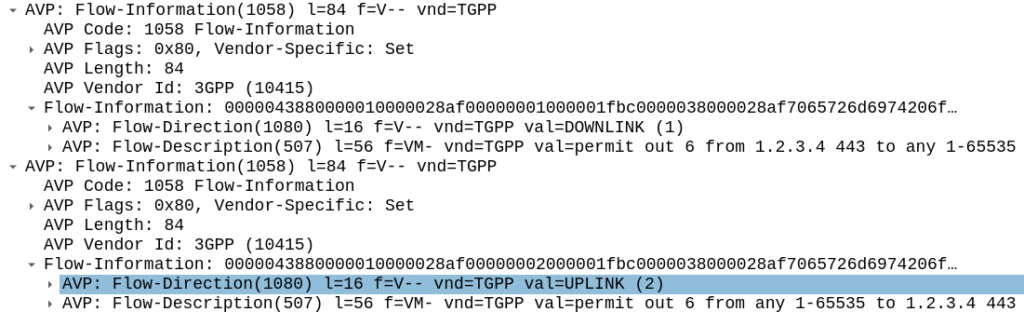
So let’s create a rule that matches all traffic to our website hosted on 1.2.3.4 TCP port 443,
permit out 6 from 1.2.3.4 443 to any 1-65535
permit out 6 from any 1-65535 to 1.2.3.4 443
All this info gets put into the Flow-Information AVPs:
With the above, any traffic going to/from 1.23.4 on port 443, will match this rule (unless there’s another rule with a higher precedence value).
Charging Actions
So with our traffic profiled, the next question is what actions are we going to take, well there’s two, we’re going to provide unmetered access to the profiled traffic, and we’re going to use QCI 4 for the traffic (because you’ll need a guaranteed bit rate bearer to access!).
Charging-Group for Profiled Traffic
To allow for Zero Rating for traffic matching this rule, we’ll need to use a different Rating Group.
Let’s imagine our default rating group for data is 10000, then any normal traffic going to the OCS will use rating group 10000, and the OCS will apply the specific rates and policies based on that.
Rating Groups are defined in the OCS, and dictate what rates get applied to what Rating Groups.
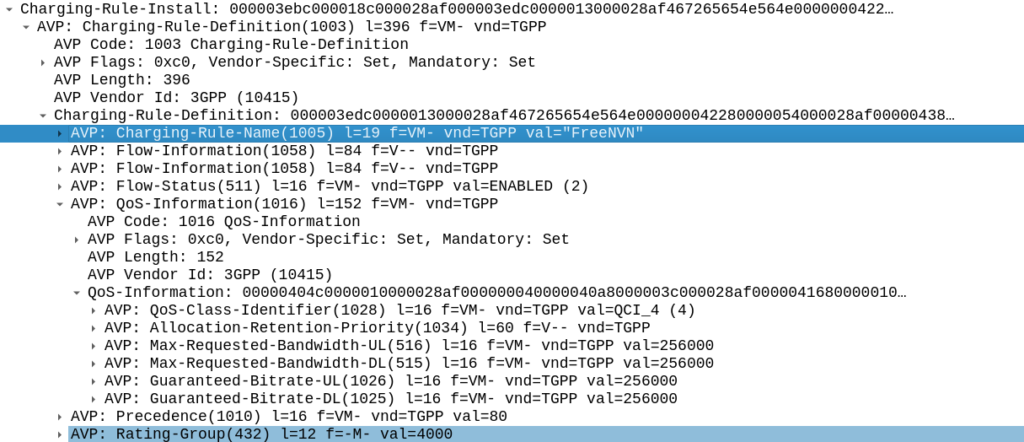
For us, our default rating group will be charged at the normal rates, but we can define a rating group value of 4000, and set the OCS to provide unlimited traffic to any Credit-Control-Requests that come in with Rating Group 4000.
This is how operators provide services like “Unlimited Facebook” for example, a Charging Rule matches the traffic to Facebook based on TFTs, and then the Rating Group is set differently to the default rating group, and the OCS just allows all traffic on that rating group, regardless of how much is consumed.
Inside our Charging-Rule-Definition, we populate the Rating-Group AVP to define what Rating Group we’re going to use.
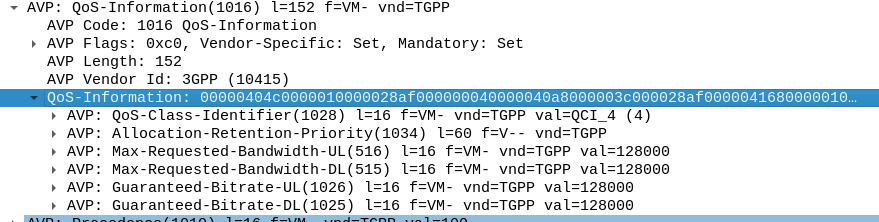
Setting QoS for Profiled Traffic
The QoS Description AVP defines which QoS parameters (QCI / ARP / Guaranteed & Maximum Bandwidth) should be applied to the traffic that matches the rules we just defined.
As mentioned at the start, we’ll use QCI 4 for this traffic, and allocate MBR/GBR values for this traffic.
Putting it Together – The Charging Rule
So with our TFTs defined to match the traffic, our Rating Group to charge the traffic and our QoS to apply to the traffic, we’re ready to put the whole thing together.
So here it is, our “Free NVN” rule:
I’ve attached a PCAP of the flow to this post.
In our next post we’ll talk about how the PGW handles the installation of this rule.
Next we’ll need to define our rt_pyform config, this is a super simple 3 line config file that specifies the path of what we’re doing:
DirectoryPath = "." # Directory to search
ModuleName = "script" # Name of python file. Note there is no .py extension
FunctionName = "transform" # Python function to call
The DirectoryPath directive specifies where we should search for the Python code, and ModuleName is the name of the Python script, lastly we have FunctionName which is the name of the Python function that does the rewriting.
Now let’s write our Python function for the transformation.
The Python function much have the correct number of parameters, must return a string, and must use the name specified in the config.
The following is an example of a function that prints out all the values it receives:
Note the order of the arguments and that return is of the same type as the AVP value (string).
We can expand upon this and add conditionals, let’s take a look at some more complex examples:
def transform(appId, flags, cmdCode, HBH_ID, E2E_ID, AVP_Code, vendorID, value):
print('[PYTHON]')
print(f'|-> appId: {appId}')
print(f'|-> flags: {hex(flags)}')
print(f'|-> cmdCode: {cmdCode}')
print(f'|-> HBH_ID: {hex(HBH_ID)}')
print(f'|-> E2E_ID: {hex(E2E_ID)}')
print(f'|-> AVP_Code: {AVP_Code}')
print(f'|-> vendorID: {vendorID}')
print(f'|-> value: {value}')
#IMSI Translation - if App ID = 16777251 and the AVP being evaluated is the Username
if (int(appId) == 16777251) and int(AVP_Code) == 1:
print("This is IMSI '" + str(value) + "' - Evaluating transformation")
print("Original value: " + str(value))
value = str(value[::-1]).zfill(15)
The above look at if the App ID is S6a, and the AVP being checked is AVP Code 1 (Username / IMSI ) and if so, reverses the username, so IMSI 1234567 becomes 7654321, the zfill is just to pad with leading 0s if required.
Now let’s do another one for a Realm Rewrite:
def transform(appId, flags, cmdCode, HBH_ID, E2E_ID, AVP_Code, vendorID, value):
#Print Debug Info
print('[PYTHON]')
print(f'|-> appId: {appId}')
print(f'|-> flags: {hex(flags)}')
print(f'|-> cmdCode: {cmdCode}')
print(f'|-> HBH_ID: {hex(HBH_ID)}')
print(f'|-> E2E_ID: {hex(E2E_ID)}')
print(f'|-> AVP_Code: {AVP_Code}')
print(f'|-> vendorID: {vendorID}')
print(f'|-> value: {value}')
#Realm Translation
if int(AVP_Code) == 283:
print("This is Destination Realm '" + str(value) + "' - Evaluating transformation")
if value == "epc.mnc001.mcc001.3gppnetwork.org":
new_realm = "epc.mnc999.mcc999.3gppnetwork.org"
print("translating from " + str(value) + " to " + str(new_realm))
value = new_realm
else:
#If the Realm doesn't match the above conditions, then don't change anything
print("No modification made to Realm as conditions not met")
print("Updated Value: " + str(value))
In the above block if the Realm is set to epc.mnc001.mcc001.3gppnetwork.org it is rewritten to epc.mnc999.mcc999.3gppnetwork.org, hopefully you can get a handle on the sorts of transformations we can do with this – We can translate any string type AVPs, which allows for hostname, realm, IMSI, Sh-User-Data, Location-Info, etc, etc, to be rewritten.
Having a central pair of Diameter routing agents allows us to drastically simplify our network, but what if we want to perform some translations on AVPs?
For starters, what is an AVP transformation? Well it’s simply rewriting the value of an AVP as the Diameter Request/Response passes through the DRA. A request may come into the DRA with IMSI xxxxxx and leave with IMSI yyyyyy if a translation is applied.
So why would we want to do this?
Well, what if we purchased another operator who used Realm X, and we use Realm Y, and we want to link the two networks, then we’d need to rewrite Realm Y to Realm X, and Realm X to Realm Y when they communicate, AVP transformations allow for this.
If we’re an MVNO with hosted IMSIs from an MNO, but want to keep just the one IMSI in our HSS/OCS, we can translate from the MNO hosted IMSI to our internal IMSI, using AVP transformations.
If our OCS supports only one rating group, and we want to rewrite all rating groups to that one value, AVP transformations cover this too.
There are lots of uses for this, and if you’ve worked with a bit of signaling before you’ll know that quite often these sorts of use-cases come up.
So how do we do this with freeDiameter?
To handle this I developed a module for passing each AVP to a Python function, which can then apply any transformation to a text based value, using every tool available to you in Python.
In the next post I’ll introduce rt_pyform and how we can use it with Python to translate Diameter AVPs.
Way back in part 2 we discussed the basic routing logic a DRA handles, but what if we want to do something a bit outside of the box in terms of how we route?
For me, one of the most useful use cases for a DRA is to route traffic based on IMSI / Username. This means I can route all the traffic for MVNO X to MVNO X’s HSS, or for staging / test subs to the test HSS enviroment.
FreeDiameter has a bunch of built in logic that handles routing based on a weight, but we can override this, using the rt_default module.
In our last post we had this module commented out, but let’s uncomment it and start playing with it:
In the above code we’ve uncommented rt_default and rt_redirect.
You’ll notice that rt_default references a config file, so we’ll create a new file in our /etc/freeDiameter directory called rt_default.conf, and this is where the magic will happen.
A few points before we get started:
This overrides the default routing priorities, but in order for a peer to be selected, it has to be in an Open (active) state
The peer still has to have advertised support for the requested application in the CER/CEA dialog
The peers will still need to have all been defined in the freeDiameter.conf file in order to be selected
So with that in mind, and the 5 peers we have defined in our config above (assuming all are connected), let’s look at some rules we can setup using rt_default.
Intro to rt_default Rules
The rt_default.conf file contains a list of rules, each rule has a criteria that if matched, will result in the specified action being taken. The actions all revolve around how to route the traffic.
So what can these criteria match on? Here’s the options:
Item to Match
Code
Any
*
Origin-Host
oh=”STR/REG”
Origin-Realm
or=”STR/REG”
Destination-Host
dh=”STR/REG”
Destination-Realm
dr=”STR/REG”
User-Name
un=”STR/REG”
Session-Id
si=”STR/REG”
rt_default Matching Criteria
We can either match based on a string or a regex, for example, if we want to match anything where the Destination-Realm is “mnc001.mcc001.3gppnetwork.org” we’d use something like:
#Low score to HSS02
dr="mnc001.mcc001.3gppnetwork.org" : dh="hss02" += -70 ;
Now you’ll notice there is some stuff after this, let’s look at that.
We’re matching anything where the destination-host is set to hss02 (that’s the bit before the colon), but what’s the bit after that?
Well if we imagine that all our Diameter peers are up, when a message comes in with Destination-Realm “mnc001.mcc001.3gppnetwork.org”, looking for an HSS, then in our example setup, we have 4 HHS instances to choose from (assuming they’re all online).
In default Diameter routing, all of these peers are in the same realm, and as they’re all HSS instances, they all support the same applications – Our request could go to any of them.
But what we set in the above example is simply the following:
If the Destination-Realm is set to mnc001.mcc001.3gppnetwork.org, then set the priority for routing to hss02 to the lowest possible value.
So that leaves the 3 other Diameter peers with a higher score than HSS02, so HSS02 won’t be used.
Let’s steer this a little more,
Let’s specify that we want to use HSS01 to handle all the requests (if it’s available), we can do that by adding a rule like this:
#Low score to HSS02
dr="mnc001.mcc001.3gppnetwork.org" : dh="hss02" += -70 ;
#High score to HSS01
dr="mnc001.mcc001.3gppnetwork.org" : dh="hss01" += 100 ;
But what if we want to route to hss-lab if the IMSI matches a specific value, well we can do that too.
#Low score to HSS02
dr="mnc001.mcc001.3gppnetwork.org" : dh="hss02" += -70 ;
#High score to HSS01
dr="mnc001.mcc001.3gppnetwork.org" : dh="hss01" += 100 ;
#Route traffic for IMSI to Lab HSS
un="001019999999999999" : dh="hss-lab" += 200 ;
Now that we’ve set an entry with a higher score than hss01 that will be matched if the username (IMSI) equals 001019999999999999, the traffic will get routed to hss-lab.
But that’s a whole IMSI, what if we want to match only part of a field?
Well, we can use regex in the Criteria as well, so let’s look at using some Regex, let’s say for example all our MVNO SIMs start with 001012xxxxxxx, let’s setup a rule to match that, and route to the MVNO HSS with a higher priority than our normal HSS:
#Low score to HSS02
dr="mnc001.mcc001.3gppnetwork.org" : dh="hss02" += -70 ;
#High score to HSS01
dr="mnc001.mcc001.3gppnetwork.org" : dh="hss01" += 100 ;#Route traffic for IMSI to Lab HSS
un="001019999999999999" : dh="hss-lab" += 200 ;
#Route traffic where IMSI starts with 001012 to MVNO HSS
un=["^001012.*"] : dh="hss-mvno-x" += 200 ;
Let’s imagine that down the line we introduce HSS03 and HSS04, and we only want to use HSS01 if HSS03 and HSS04 are unavailable, and only to use HSS02 no other HSSes are available, and we want to split the traffic 50/50 across HSS03 and HSS04.
Firstly we’d need to add HSS03 and HSS04 to our FreeDiameter.conf file:
Then in our rt_default.conf we’d need to tweak our scores again:
#Low score to HSS02
dr="mnc001.mcc001.3gppnetwork.org" : dh="hss02" += 10 ;
#Medium score to HSS01
dr="mnc001.mcc001.3gppnetwork.org" : dh="hss01" += 20 ;
#Route traffic for IMSI to Lab HSS
un="001019999999999999" : dh="hss-lab" += 200 ;
#Route traffic where IMSI starts with 001012 to MVNO HSS
un=["^001012.*"] : dh="hss-mvno-x" += 200 ;
#High Score for HSS03 and HSS04dr="mnc001.mcc001.3gppnetwork.org" : dh="hss02" += 100 ;dr="mnc001.mcc001.3gppnetwork.org" : dh="hss04" += 100 ;
One quick tip to keep your logic a bit simpler, is that we can set a variety of different values based on keywords (listed below) rather than on a weight/score:
Behaviour
Name
Score
Do not deliver to peer (set lowest priority)
NO_DELIVERY
-70
The peer is a default route for all messages
DEFAULT
5
The peer is a default route for this realm
DEFAULT_REALM
10
REALM
15
Route to the specified Host with highest priority
FINALDEST
100
Rather than manually specifying the store you can use keywords like above to set the value
In our next post we’ll look at using FreeDiameter based DRA in roaming scenarios where we route messages across Diameter Realms.
FreeDiameter has been around for a while, and we’ve covered configuring the FreeDiameter components in Open5GS when it comes to the S6a interface, so you may have already come across FreeDiameter in the past, but been left a bit baffled as to how to get it to actually do something.
FreeDiameter is a FOSS implimentation of the Diameter protocol stack, and is predominantly used as a building point for developers to build Diameter applications on top of.
But for our scenario, we’ll just be using plain FreeDiameter.
So let’s get into it,
You’ll need FreeDiameter installed, and you’ll need a certificate for your FreeDiameter instance, more on that in this post.
Once that’s setup we’ll need to define some basics,
Inside freeDiameter.conf we’ll need to include the identity of our DRA, load the extensions and reference the certificate files:
What I typically refer to as Diameter interfaces / reference points, such as S6a, Sh, Sx, Sy, Gx, Gy, Zh, etc, etc, are also known as Applications.
Diameter Application Support
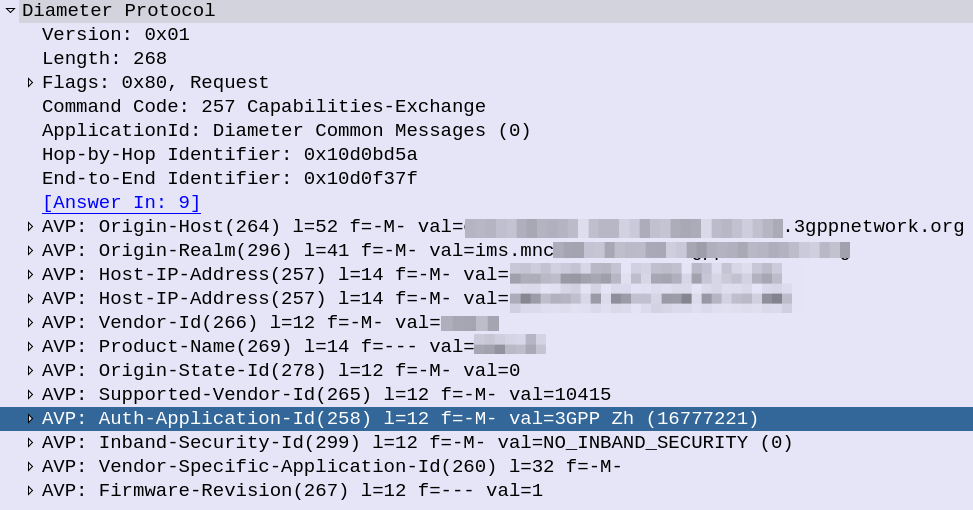
If you look inside the Capabilities Exchange Request / Answer dialog, what you’ll see is each side advertising the Applications (interfaces) that they support, each one being identified by an Application ID.
CER showing support for the 3GPP Zh Application-ID (Interface)
If two peers share a common Application-Id, then they can communicate using that Application / Interface.
For example, the above screenshot shows a peer with support for the Zh Interface (Spoiler alert, XCAP Gateway / BSF coming soon!). If two Diameter peers both have support for the Zh interface, then they can use that to send requests / responses to each other.
This is the basis of Diameter Routing.
Diameter Routing Tables
Like any router, our DRA needs to have logic to select which peer to route each message to.
For each Diameter connection to our DRA, it will build up a Diameter Routing table, with information on each peer, including the realm and applications it advertises support for.
Then, based on the logic defined in the DRA to select which Diameter peer to route each request to.
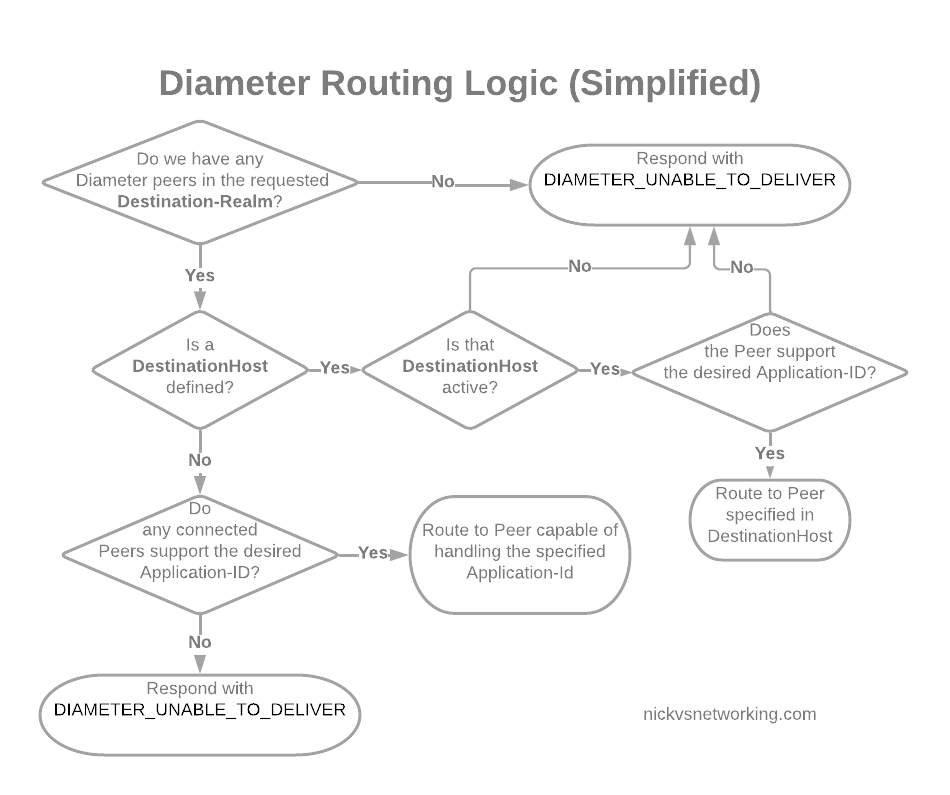
In its simplest form, Diameter routing is based on a few things:
Look at the DestinationRealm, and see if we have any peers at that realm
If we do then look at the DestinationHost, if that’s set, and the host is connected, and if it supports the specified Application-Id, then route it to that host
If no DestinationHost is specified, look at the peers we have available and find the one that supports the specified Application-Id, then route it to that host
Simplified Diameter Routing Table used by DRAs
With this in mind, we can go back to looking at how our DRA may route a request from a connected MME towards an HSS.
Let’s look at some examples of this at play.
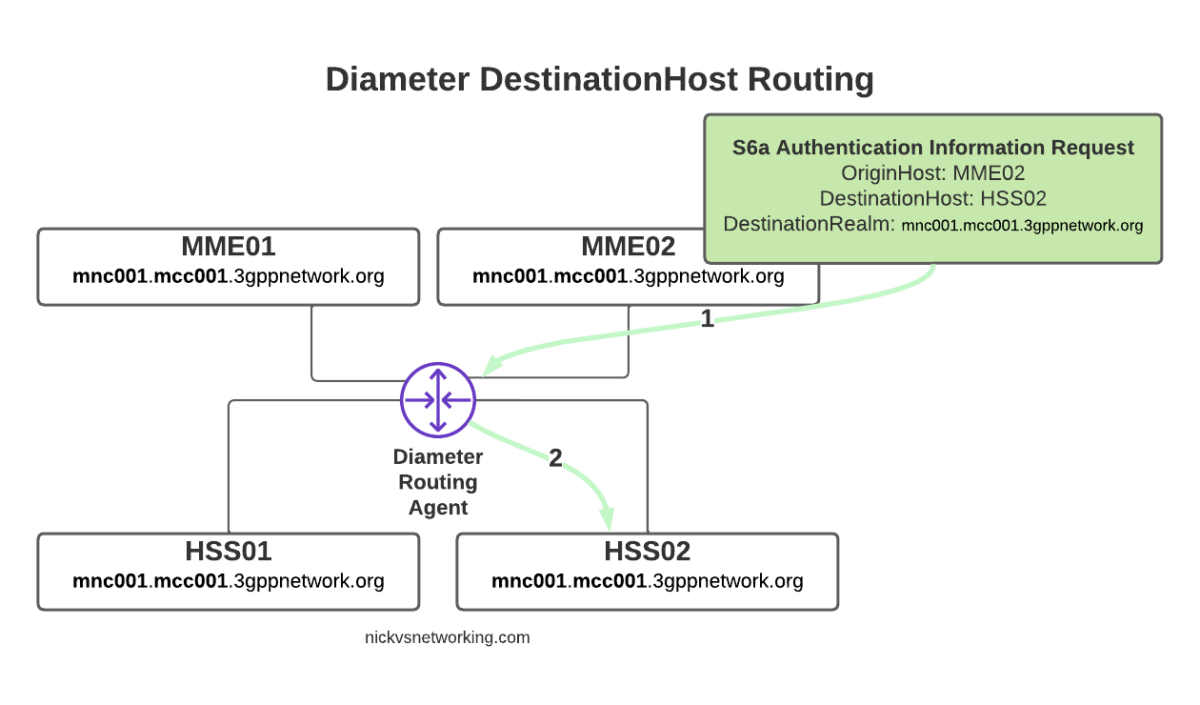
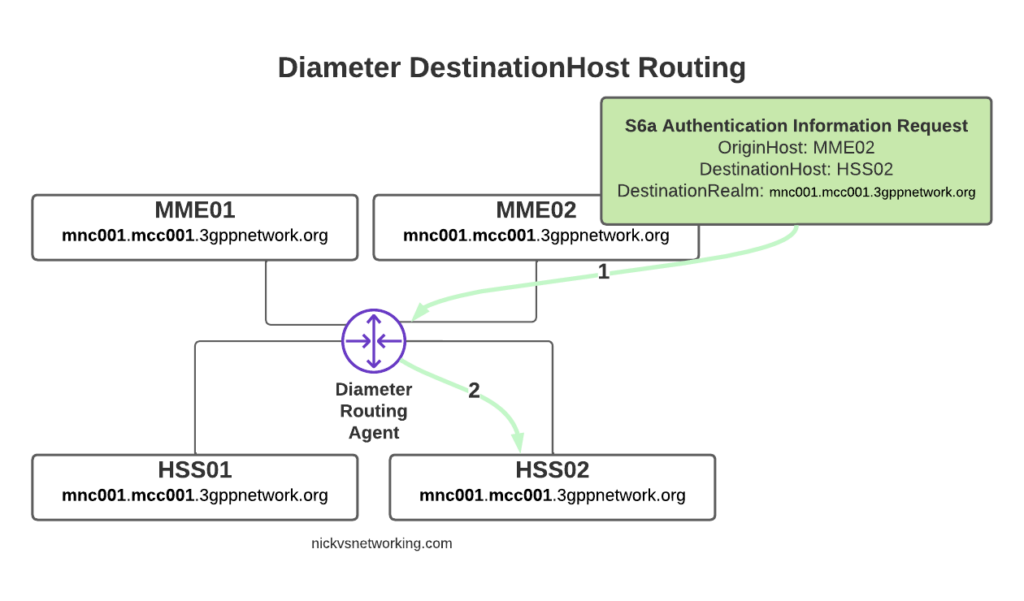
The request from MME02 is for DestinationRealm mnc001.mcc001.3gppnetwork.org, which our DRA knows it has 4 connected peers in (3 if we exclude the source of the request, as we don’t want to route it back to itself of course).
So we have 3 contenders still for who could get the request, but wait! We have a DestinationHost specified, so the DRA confirms the host is available, and that it supports the requested ApplicationId and routes it to HSS02.
So just because we are going through a DRA does not mean we can’t specific which destination host we need, just like we would if we had a direct link between each Diameter peer.
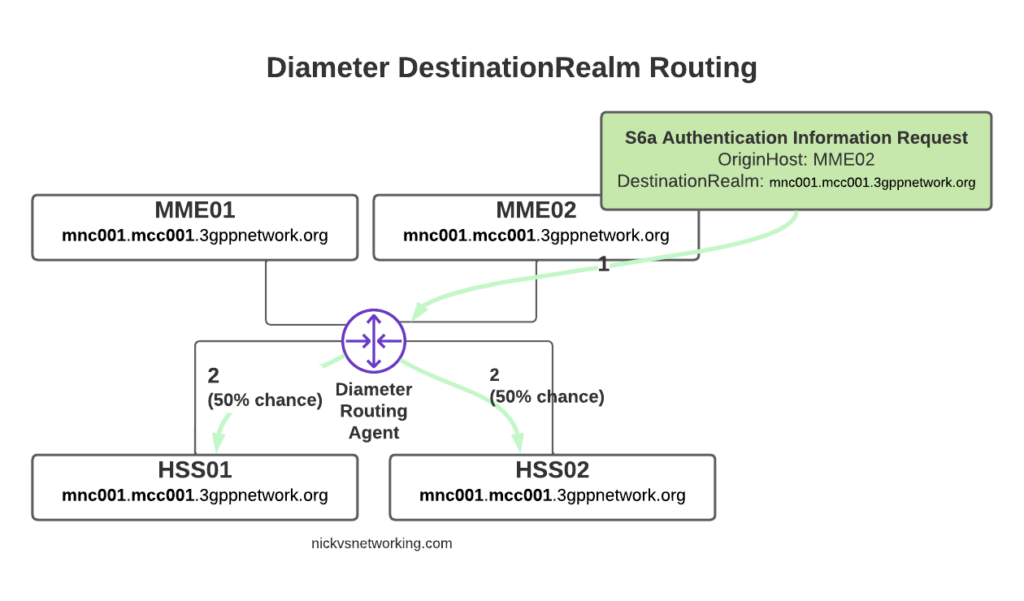
Conversely, if we sent another S6a request from MME01 but with no DestinationHost set, let’s see how that would look.
Again, the request is from MME02 is for DestinationRealm mnc001.mcc001.3gppnetwork.org, which our DRA knows it has 3 other peers it could route this to. But only two of those peers support the S6a Application, so the request would be split between the two peers evenly.
Clever Routing with DRAs
So with our DRA in place we can simplify the network, we don’t need to build peer links between every Diameter device to every other, but let’s look at some other ways DRAs can help us.
Load Control
We may want to always send requests to HSS01 and only use HSS02 if HSS01 is not available, we can do this with a DRA.
Or we may want to split load 75% on one HSS and 25% on the other.
Both are great use cases for a DRA.
Routing based on Username
We may want to route requests in the DRA based on other factors, such as the IMSI.
Our IMSIs may start with 001010001xxx, but if we introduced an MVNO with IMSIs starting with 001010002xxx, we’d need to know to route all traffic where the IMSI belongs to the home network to the home network HSS, and all the MVNO IMSI traffic to the MVNO’s HSS, and DRAs handle this.
Inter-Realm Routing
One of the main use cases you’ll see for DRAs is in Roaming scenarios.
For example, if we have a roaming agreement with a subscriber who’s IMSIs start with 90170, we can route all the traffic for their subs towards their HSS.
But wait, their Realm will be mnc901.mcc070.3gppnetwork.org, so in that scenario we’ll need to add a rule to route the request to a different realm.
DRAs handle this also.
In our next post we’ll start actually setting up a DRA with a default route table, and then look at some more advanced options for Diameter routing like we’ve just discussed.
One slight caveat, is that mutual support does not always mean what you may expect. For example an MME and an HSS both support S6a, which is identified by Auth-Application-Id 16777251 (Vendor ID 10415), but one is a client and one is a server. Keep this in mind!
Answer Question 1: Because they make things simpler and more flexible for your Diameter traffic. Answer Question 2: With free software of course!
All about DRAs
But let’s dive a little deeper. Let’s look at the connection between an MME and an HSS (the S6a interface).
Direct Diameter link between two Diameter Peers
We configure the Diameter peers on MME1 and HSS01 so they know about each other and how to communicate, the link comes up and presto, away we go.
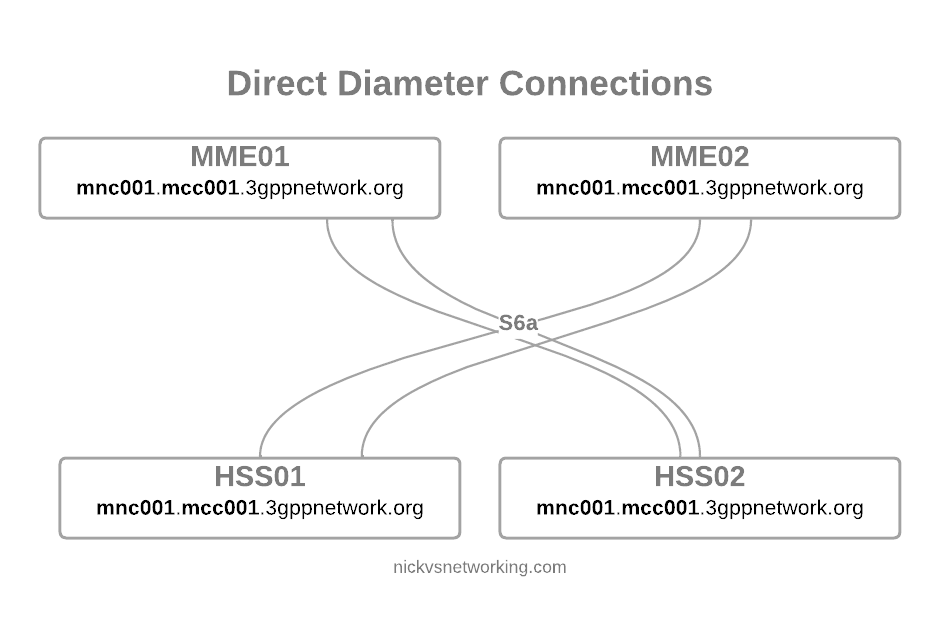
But we’re building networks here! N+1 redundancy and all that, so now we have two HSSes and two MMEs.
Direct Diameter link between 4 Diameter peers
Okay, bit messy, but that’s okay…
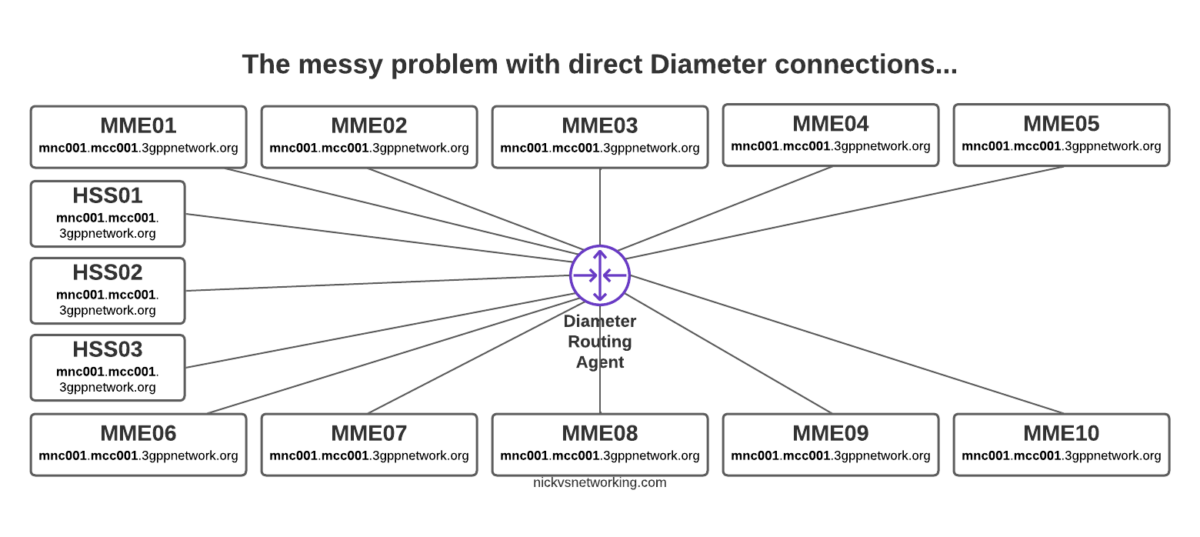
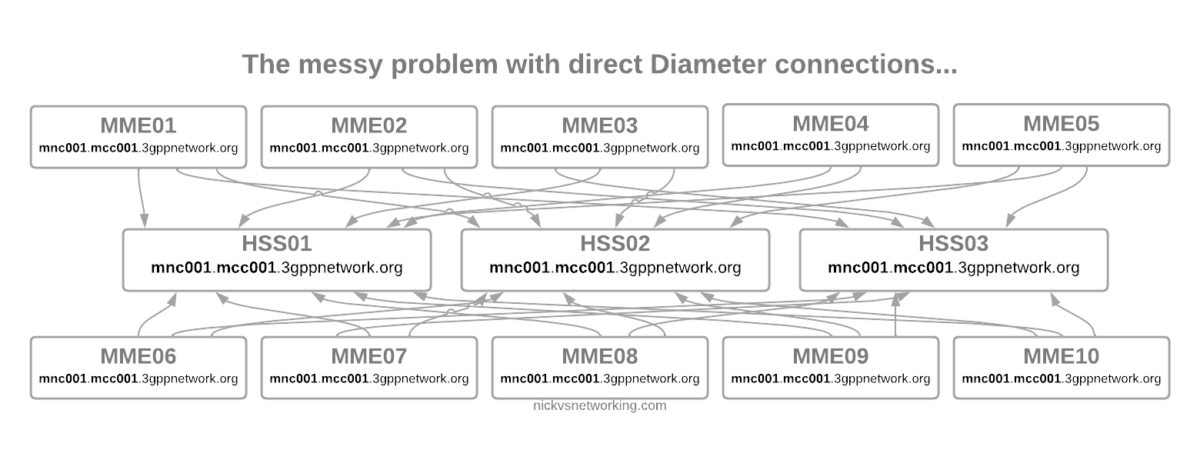
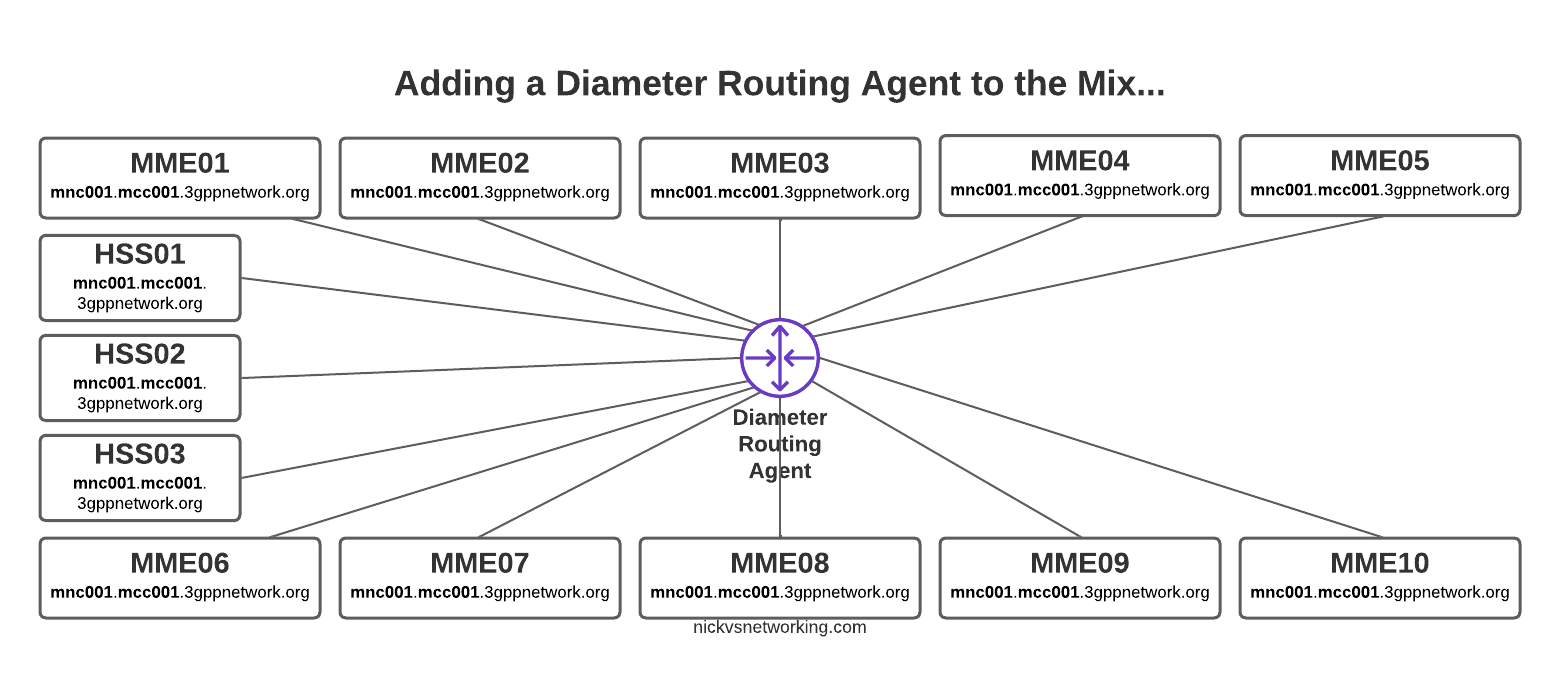
But then our network grows to 10 MMEs, and 3 HSSes and you can probably see where this is going, but let’s drive the point home.
Direct Diameter connections for a network with 10x MME and 3x HSS
Now imagine once you’ve set all this up you need to do some maintenance work on HSS03, so need to shut down the Diameter peer on 10 different MMEs in order to isolate it and deisolate it.
The problem here is pretty evident, all those links are messy, cumbersome and they just don’t scale.
If you’re someone with a bit of networking experience (and let’s face it, you’re here after all), then you’re probably thinking “What if we just had a central system to route all the Diameter messages?”
An Agent that could Route Diameter, a Diameter Routing Agent perhaps…
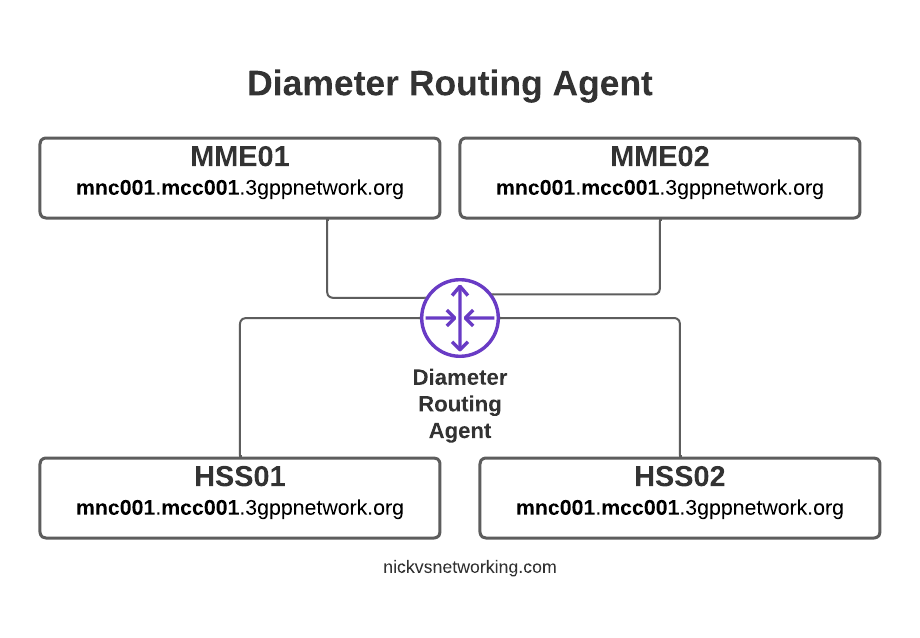
By introducing a DRA we build Diameter peer links between each of our Diameter devices (MME / HSS, etc) and the DRA, rather than directly between each peer.
With Diameter Routing Agent
Then from the DRA we can route Diameter requests and responses between them.
Let’s go back to our 10x MME and 3x HSS network and see how it looks with a DRA instead.
So much cleaner!
Not only does this look better, but it makes our life operating the network a whole lot easier.
Each MME sends their S6a traffic to the DRA, which finds a healthy HSS from the 3 and sends the requests to it, and relays the responses as well.
We can do clever load balancing now as well.
Plus if a peer goes down, the DRA detects the failure and just routes to one of the others.
If we were to introduce a new HSS, we wouldn’t need to configure anything on the MMEs, just add HSS04 to the DRA and it’ll start getting traffic.
Plus from an operations standpoint, now if we want to to take an HSS offline for maintenance, we just shut down the link on the HSS and all HSS traffic will get routed to the other two HSS instances.
In our next post we’ll talk about the Routing part of the DRA, how the decisions are made and all the nuances, and then in the following post we’ll actually build a DRA and start routing some traffic around!
Even if you’re not using TLS in your FreeDiameter instance, you’ll still need a certificate in order to start the stack.
Luckily, creating a self-signed certificate is pretty simple,
Firstly we generate your a private key and public certificate for our required domain – in the below example I’m using dra01.epc.mnc001.mcc001.3gppnetwork.org, but you’ll need to replace that with the domain name of your freeDiameter instance.
If you’re using freeDiameter as part of another software stack (Such as Open5Gs) the below filenames will contain the config for that particular freeDiameter components of the stack: