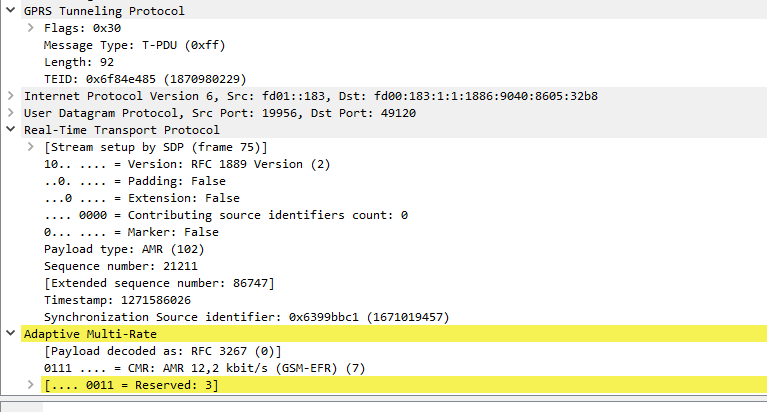
Recently we saw Open5Gs’s Update Location Answer response putting the Subscribed-Periodic-RAU-TAU-Timer AVP in the top level and not in the AVP Code 1400 (APN Configuration) Diameter payload from the HSS to the MME.
But what exactly does the Subscribed-Periodic-RAU-TAU-Timer AVP in the Update Location Answer response do?
Folks familiar with EUTRAN might recognise TAU as Tracking Area Update, while RAU is Routing Area Update in GERAN/UTRAN (UMTS).
Periodic tracking area updating is used to periodically notify the availability of the UE to the network. The procedure is controlled in the UE by the periodic tracking area update timer (timer T3412). The value of timer T3412 is sent by the network to the UE in the ATTACH ACCEPT message and can be sent in the TRACKING AREA UPDATE ACCEPT message. The UE shall apply this value in all tracking areas of the list of tracking areas assigned to the UE, until a new value is received.
Section 5.3.5 of 24301-9b0 (3GPP TS 24.301 V9.11.0)
So the Periodic Tracking Area Update timer simply defines how often the UE should send a Tracking Area Update when stationary (not moving between cells / tracking area lists).
On a PCM (G.711) RTP packet the payload is typically 160 bytes per packet.
But the total size of the frame on the wire is typically ~214 bytes, to carry a 160 byte payload that means 25% of the data being carried is headers.
This is fine for VoIP services operating over fixed lines, but when we’re talking about VoLTE / IMS and the traffic is being transferred over Radio Access Networks with limited bandwidth / resources, it’s important to minimize this as much as possible.
IMS uses the AMR codec, where the RTP payload for each packet is around 90 bytes, meaning up to two thirds of the packet on the wire (Or in this case the air / Uu interface) is headers.
Using ROHC the size of the headers are cut down to only 4-5 bytes, this is because the IPv4 headers, UDP headers and RTP headers are typically the same in each packet – with only the RTP Sequence number, RTP timestamp IPv4 & UDP checksum and changing between frames.
As anyone who’s setup a private LTE network can generally attest, APNs can be a real headache.
SIM/USIM cards, don’t store any APN details. In this past you may remember having to plug all these settings into your new phone when you upgraded so you could get online again.
Today when you insert a USIM belonging to a commercial operator, you generally don’t need to put APN settings in, this is because Android OS has its own index of APNs. When the USIM is inserted into the baseband module, the handset’s OS looks at the MCC & MNC in the IMSI and gets the APN settings automatically from Android’s database of APN details.
There is an option for the network to send the connectivity details to the UE in a special type of SMS, but we won’t go into that.
All this info is stored on the Android OS in apns-full-conf.xml which for non-rooted (stock) devices is not editable.
This file can override the user’s APN configuration, which can lead to some really confusing times as your EPC rejects the connection due to an unrecognized APN which is not what you have configured on the UE’s operating system, but it instead uses APN details from it’s database.
The only way around this is to change the apns-full-conf.xml file, either by modifying it per handset or submitting a push request to Android Open Source with your updated settings.
(I’ve only tried the former with rooted devices)
The XML file itself is fairly self explanatory, taking the MCC and MNC and the APN details for your network:
Once you’ve added yours to the file, inserting the USIM, rebooting the handset or restarting the carrier app is all that’s required for it to be re-read and auto provision APN settings from the XML file.
I recently started working on an issue that I’d seen was to do with the HSS response to the MME on an Update Location Answer.
I took some Wireshark traces of a connection from the MME to the HSS, and compared that to a trace from a different HSS. (Amarisoft EPC/HSS)
The Update Location Answer sent by the Amarisoft HSS to the MME over the S6a (Diameter) interface includes an AVP for “Multiple APN Configuration” which has the the dedicated bearer for IMS, while the HSS in the software I was working on didn’t.
After a bit of bashing trying to modify the S6a responses, I decided I’d just implement my own Home Subscriber Server.
Each Diameter packet has at a the following headers:
Version
This 1 byte field is always (as of 2019) 0x01 (1)
Length
3 bytes containing the total length of the Diameter packet and all it’s contained AVPs.
This allows the receiver to know when the packet has ended, by reading the length and it’s received bytes so far it can know when that packet ends.
Flags
Flags allow particular parameters to be set, defining some possible options for how the packet is to be handled by setting one of the 8 bits in the flags byte, for example Request Set, Proxyable, Error, Potentially Re-transmitted Message,
Command Code
Each Diameter packet has a 3 byte command code, that defines the method of the request,
The IETF have defined the basic command codes in the Diameter Base Protocol RFC, but many vendors have defined their own command codes, and users are free to create and define their own, and even register them for public use.
To allow vendors to define their own command codes, each command code is also accompanied by the Application ID, for example the command code 257 in the base Diameter protocol translates to Capabilities Exchange Request, used to specify the capabilities of each Diameter peer, but 257 is only a Capabilities Exchange Request if the Application ID is set to 0 (Diameter Base Protocol).
If we start developing our own applications, we would start with getting an Application ID, and then could define our own command codes. So 257 with Application ID 0 is Capabilities Exchange Request, but command code 257 with Application ID 1234 could be a totally different request.
Hop-By-Hop Identifier
The Hop By Hop identifier is a unique identifier that helps stateful Diameter proxies route messages to and fro. A Diameter proxy would record the source address and Hop-by-Hop Identifier of a received packet, replace the Hop by Hop Identifier with a new one it assigns and record that with the original Hop by Hop Identifier, original source and new Hop by Hop Identifier.
End-to-End Identifier
Unlike the Hop-by-Hop identifier the End to End Identifier does not change, and must not be modified, it’s used to detect duplicates of messages along with the Origin-Host AVP.
AVPs
The real power of Diameter comes from AVPs, the base protocol defines how to structure a Diameter packet, but can’t convey any specific data or requests, we put these inside our Attribute Value Pairs.
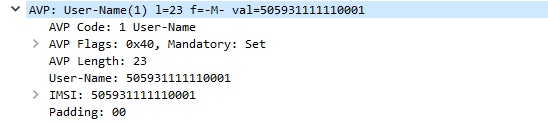
Let’s take a look at a simple Diameter request, it’s got all the boilerplate headers we talked about, and contains an AVP with the username.
Here we can see we’ve got an AVP with AVP Code 1, containing a username
Let’s break this down a bit more.
AVP Codes are very similar to the Diameter Command Codes/ApplicationIDs we just talked about.
Combined with an AVP Vendor ID they define the information type of the AVP, some examples would be Username, Session-ID, Destination Realm, Authentication-Info, Result Code, etc.
AVP Flags are again like the Diameter Flags, and are made up a series of bits, denoting if a parameter is set or not, at this stage only the first two bits are used, the first is Vendor Specific which defines if the AVP Code is specific to an AVP Vendor ID, and the second is Mandatory which specifies the receiver must be able to interpret this AVP or reject the entire Diameter request.
AVP Length defines the length of the AVP, like the Diameter length field this is used to delineate the end of one AVP.
AVP Vendor ID
If the AVP Vendor Specific flag is set this optional field specifies the vendor ID of the AVP Code used.
AVP Data
The payload containing the actual AVP data, this could be a username, in this example, a session ID, a domain, or any other value the vendor defines.
AVP Padding
AVPs have to fit on a multiple of a 32 bit boundary, so padding bits are added to the end of a packet if required to total the next 32 bit boundary.
3GPP selected Diameter protocol to take care of Authentication, Authorization, and Accounting (AAA).
It’s typically used to authenticate users on a network, authorize them to use services they’re allowed to use and account for how much of the services they used.
In a EPC scenario the Authentication function takes the form verifying the subscriber is valid and knows the K & OP/OPc keys for their specific IMSI.
The Authorization function checks to find out which features, APNs, QCI values and services the subscriber is allowed to use.
The Accounting function records session usage of a subscriber, for example how many sessional units of talk time, Mb of data transferred, etc.
Diameter Packets are pretty simple in structure, there’s the packet itself, containing the basic information in the headers you’d expect, and then a series of one or more Attribute Value Pairs or “AVPs”.
These AVPs are exactly as they sound, there’s an attribute name, for example username, and a value, for example, “Nick”.
This could just as easily be for ordering food; we could send a Diameter packet with an imaginary command code for Food Order Request, containing a series of AVPs containing what we want. The AVPs could belike Food: Hawian Pizza, Food: Garlic Bread, Drink: Milkshake, Address: MyHouse. The Diameter server could then verify we’re allowed to order this food (Authorization) and charge us for the food (Accounting), and send back a Food Order Response containing a series of AVPs such as Delivery Time: 30 minutes, Price: $30.00, etc.
Diameter packets generally take the form of a request – response, for example a Capabilities Exchange Request contains a series of AVPs denoting the features supported by the requester, which is sent to a Diameter peer. The Diameter peer then sends back a Capabilities Exchange Response, containing a series of AVPs denoting the features that it supports.
Diameter is designed to be extensible, allowing vendors to define their own type of AVP and Diameter requests/responses and 3GPP have defined their own types of messages (Diameter Command Codes) and types of data to be transferred (AVP Codes).
LTE/EPC relies on Diameter and the 3GPP/ETSI defined AVP / Diameter Packet requests/responses to form the S6a Interface between an MME and a HSS, the Gx Interface between the PCEF and the PCRF, Cx Interface between the HSS and the CSCF, and many more interfaces used for Authentication in 3GPP networks.
ARP in LTE is not the Ethernet standard for address resolution, but rather the Allocation and Retention Policy.
A scenario may arise where on a congested cell another bearer is requested to be setup.
The P-GW, S-GW or eNB have to make a decision to either drop an existing bearer, or to refuse the request to setup a new bearer.
The ARP value is used to determine the priority of the bearer to be established compared to others,
For example a call to an emergency services number on a congested cell should drop any other bearers so the call can be made, thus the request for bearer for the VoLTE call would have a higher ARP value than the other bearers and the P-GW, S-GW or eNB would drop an existing bearer with a lower ARP value to accommodate the new bearer with a higher ARP value.
ARP is only used when setting up a new bearer, not to determine how much priority is given to that bearer once it’s established (that’s defined by the QCI).
MBR stands for Maximum Bit Rate, and it defines the maximum rate traffic can flow between a UE and the network.
It can be defined on several levels:
MBR per Bearer
This is the maximum bit rate per bearer, this rate can be exceeded but if it is exceeded it’s QoS (QCI) values for the traffic peaking higher than the MBR is back to best-effort.
AMBR
Aggregate Maximum Bit Rate – Maximum bit rate of all Service Data Flows / Bearers to and from the network from a single UE.
APN-MBR
The APN-MBR allows the operator to set a maximum bit rate per APN, for example an operator may choose to limit the MBR for subscriber on an APN for a MVNO to give it’s direct customers a higher speed.
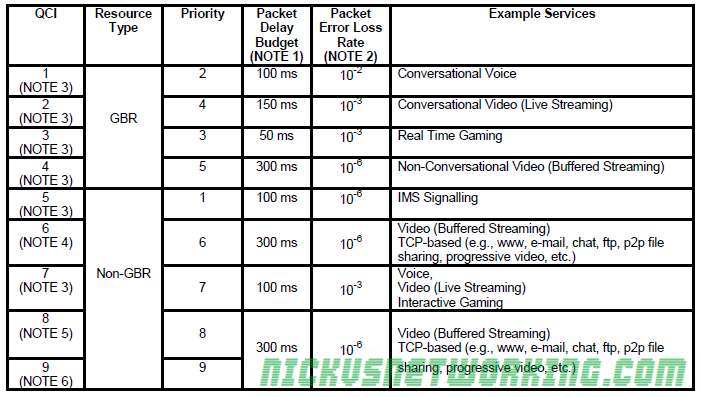
The QCI (Quality Class Indicator) is a value of 0-9 to denote the service type and the maximum delays, packet loss and throughput the service requires.
Different data flows have different service requirements, let’s look at some examples:
A VoLTE call requires low latency and low packet loss, without low latency it’ll be impossible to hold a conversation with long delays, and with high packet loss you won’t be able to hear each other.
On the other hand a HTTP (Web) browsing session will be impervious to high latency or packet loss – the only perceived change would be slightly longer page load times as lost packets are resent and added delay on load of a few hundred ms.
So now we understand the different requirements of data flows, let’s look at the columns in the table above so we can understand what they actually signify:
GBR
Guaranteed Bit Rate bearers means our eNB will reserve resource blocks to carry this data no matter what, it’ll have those resource blocks ready to transport this data.
Even if the data’s not flowing a GBR means the resources are reserved even if nothing is going through them.
This means those resource blocks can’t be shared by other users on the network. The Uu interface in the E-UTRAN is shared between UEs in time and frequency, but with GBR bearers parts of this can be reserved exclusively for use by that traffic.
Non-GBR
With a Non-GBR bearer this means there is no guaranteed bit rate, and it’s just best effort.
Non-GBR traffic is scheduled onto resource blocks when they’re not in use by other non-GBR traffic or by GBR traffic.
Priority
The priory value is used for preemption by the PCRF.
The lower the value the more quickly it’ll be processed and scheduled onto the Uu interface.
Packet Delay Budget
Maximum allowable packet delay as measured from P-GW to UE.
Most of the budget relates to the over-the-air scheduling delays.
The eNB uses the QCI information to make its scheduling decisions and packet prioritisation to ensure that the QoS requirements are met on a per-EPS-bearer basis.
(20ms is typically subtracted from this value to account for the radio propagation delay on the Uu interface)
Packet Error Loss Rate (PELR)
This is packets lost on the Uu interface, that have been sent but not confirmed received.
The PELR is an upper boundary for how high this can go, based on the SDUs (IP Packets) that have been processed by the sender on RLC but not delivered up to the next layers (PDCP) by the receiver.
(Any traffic bursting above the GBR is not counted toward the PELR)
GBR is a confusing concept at the start when looking at LTE but it’s actually kind of simple when we break it down.
GBR stands for Guaranteed Bit Rate, meaning the UE is guaranteed a set bit rate for the bearer.
The default bearer is always a non-GBR bearer, with best effort data rates.
Let’s look at non-GBR bearers to understand the need for GBR bearers:
As the Uu (Air) interface is shared between many UEs, each is able to transfer data. Let’s take an example of a cell with two UEs in it and not much bandwidth available.
If UE1 and UE2 are both sending the same amount of data it’ll be evenly split between the two.
But if UE1 starts sending a huge amount of data (high bit rate) this will impact on the other UEs in the cells ability to send data over the air as it’s a shared resource.
So if UE2 needs to send a stream of small but important data over the air interface, while UE2 is sending huge amounts of data, we’d have a problem.
To address this we introduce the concept of a Guaranteed Bit Rate. We tell the eNB that the bearer carrying UE2’s small but important data needs a Guaranteed Bit Rate and it reserves blocks on the air interface for UE2’s data.
So now we’ve seen the need for GBR there’s the counter point – the cost.
While UE1 can still continue sending but the eNB will schedule fewer resource blocks to it as it’s reserved some for UE2’s data flow.
If we introduced more and more UEs each requiring GBR bearers, eventually our non-GBR traffic would simply not get through, so GBR bearers have to be used sparingly.
Note: IP data isn’t like frame relay or circuit switched data that’s consistent, bit rate can spike and drop away all the time. GBR guarantees a minimum bit rate, which is generally tuned to the requirements of the data flow. For example a GBR for a Voice over IP call would reserve enough for the media (RTP stream) but no more, so as not to use up resources it doesn’t need.
We’ve already touched on how subscribers are authenticated to the network, how the network is authenticated to subscribers and how the key hierarchy works for encryption of user data and control plane data.
If the IMSI was broadcast in the clear over the air, anyone listening would have the unique identifier of the subscriber nearby and be able to track their movements.
We want to limit the use of the IMSI over the air to a minimum.
During the first exchange the terminal is forced to send it’s IMSI, it’s the only way we can go about authenticating to the network, but once the terminal is authenticated and encryption of the radio link has been established, the network allocates a temporary identifier to the terminal, called the Temporary Mobile Subscriber Identity (TMSI) by the serving MME.
The TMSI is given to the terminal once encryption is setup, so only the network and the terminal know the mapping between IMSI and TMSI.
The TMSI is used for all future communication between the Network and the Terminal, hiding the IMSI.
The TMSI can be updated / changed at regular intervals to ensure the IMSI-TMSI mapping cannot be ascertained by a process of elimination.
The TMSI is short – only 4 bytes long – and this only has significance for the serving MME.
For the network to ascertain what MME is serving what TMSI the terminal is also assigned a Globally Unique Temporary (UE) Identity (GUTI), to identify the MME that knows the TMSI to IMSI mapping.
The GUTI is made up of the MNC/MCC combination, then an MME group ID to identify the MME group the serving MME is in, a MME code to identify the MME that allocated the TMSI and finally the TMSI itself.
The decision to use the TMSI or GUTI in a dialog is dependant on the needs of the dialog and what information both sides have. For example in an MME change the GUTI is needed so the original IMSI can be determined by the new MME, while in a normal handover the TMSI is enough.
Let’s look at how the Tracking Area Updates work from the point of view of the network.
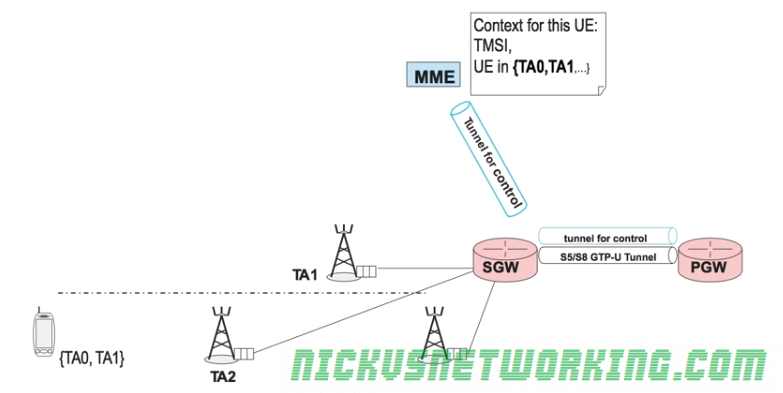
Let’s take an example of a UE which has been sent the Tracking Area List TA0 and TA1, which is currently in ECM_IDLE state served by eNBs in Tracking Area 1.
The UE is moving towards another eNB in Tracking Area 2. As the UE listens on the Broadcast Channel the power of the new eNB overtakes that of the previous eNB, but the UE notes the Tracking Area of the new eNB, which is not on the UE’s Tracking Area List.
So the UE must make a Tracking Area Update to inform the network.
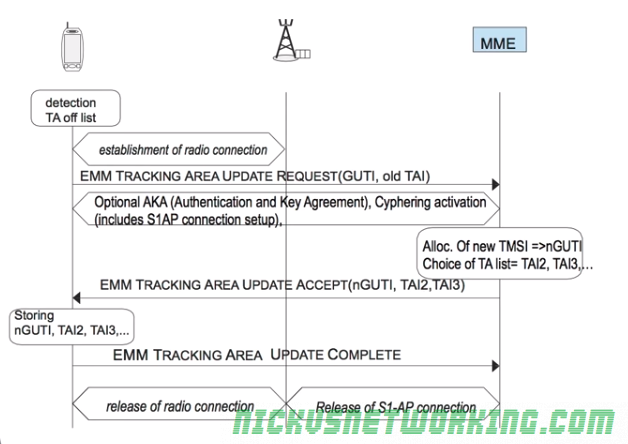
The first thing to do is to establish a radio connection.
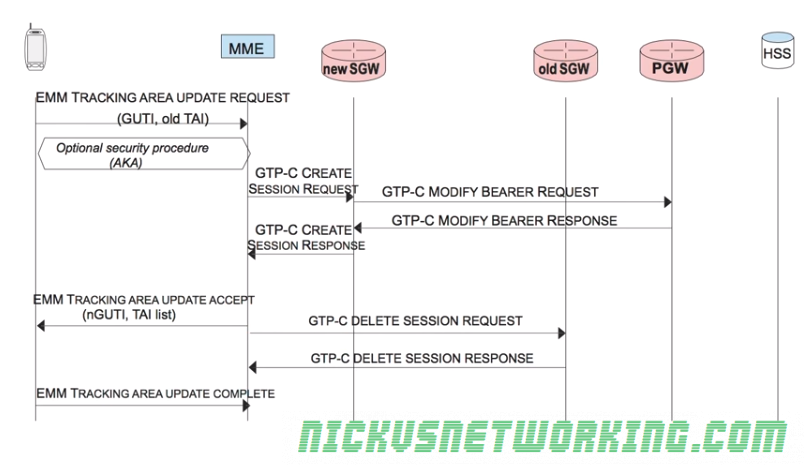
Once the radio connection is setup a S1-AP connection is setup, upon which an NAS message – EMM Tracking Area Update Request is sent which contains the GUIT and old Tracking Area ID, which is sent to the MME.
The MME then sends back a new Tracking Area List for the UE and new TMSI to update the GUTI of the subscriber.
The UE updates it’s GUTI, updates it’s Tracking Area List, sends an EMM TRACKING AREA UPDATE COMPLETE and the UE returns to ECM_IDLE state.
As we’ve seen earlier, the eNB needs a connection to an MME and a S-GW.
However different eNBs may connect to different S-GWs or different MMEs, and our UE may connect to any eNB, so we need a way to handover between S-GWs and MMEs.
Handover to new S-GW
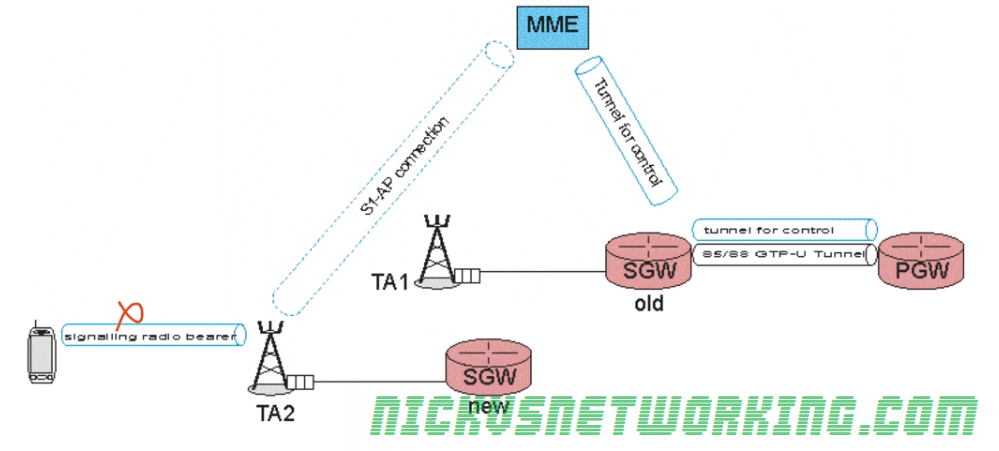
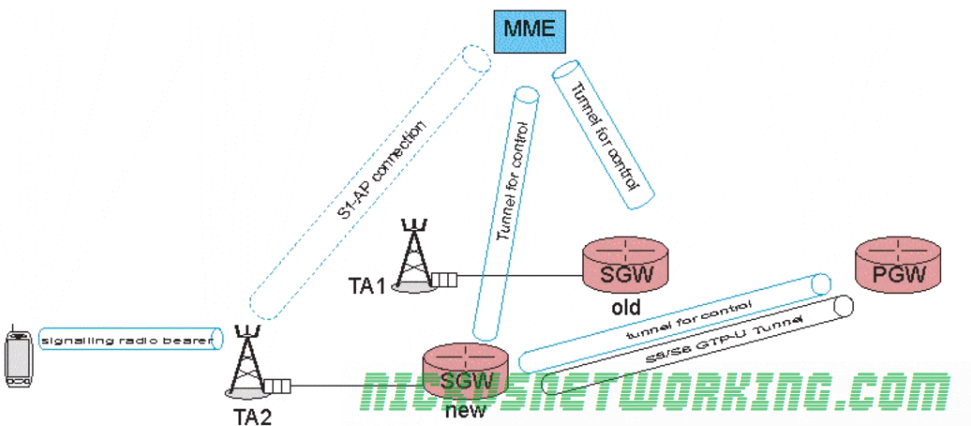
Let’s take a look at a scenario where a UE is moving from one eNB to another, and each of the two eNBs is in a different S-GW.
At the start we have a connection from the MME to the S-GW, a GTP-C tunnel for control information and a GTP-U tunnel (called the S5/58 bearer) that carriers the user data over GTP-U between the P-GW and the S-GW.
As the UE moves to the eNB in TA2 we need the MME to modify the tunnel from the P-GW to the S-GW to change it from connecting the P-GW to the old S-GW and instead connecting the P-GW to the new S-GW.
The MME establishes a new tunnel for control to the new S-GW, and sends a message to the new S-GW to modify the tunnel from the P-GW to the old S-GW to point to the new S-GW.
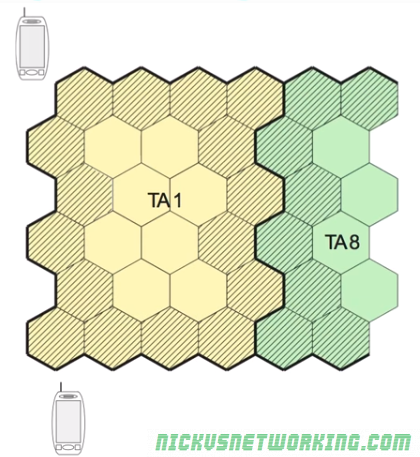
As we saw before larger Tracking Areas minimize the number of UEs between terminals to update their location.
The problem is the cells/eNBs on the edge of the Tracking Area have to handle almost all of the Tracking Area Update requests, to inform the network the UE has moved to a new TA.
The cells on the edges of the tracking area are shaded & handle the vast majority of the Tracking Area / Location Update messages
There’s an obvious imbalance between edge cells that handle almost all of Tracking Area Updates and the central cells inside a Tracking Area that handle very few many Tracking Area Update messages.
As we know we only have one radio interface, and sending Tracking Area Updates eats into our valuable radio resources that can’t be used to carry user data. Because of this users can experience a lower bit rate on edge cells.
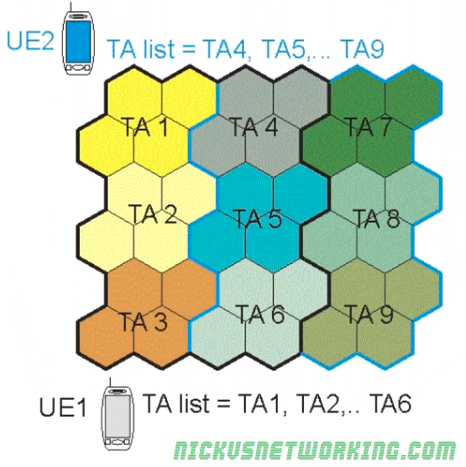
To get around this we group Tracking Areas together into Tracking Area Lists.
A Tracking Area List is provided by the network to the UE, and contains a list of Tracking Areas, so long as the UE stays within the list of Tracking Areas, there is no need for it to send a Tracking Area Update.
You might think this just makes our problem worse, as now at the edges of the cells in the Tracking Area List we have even more signaling traffic, the clever part comes from the fact the network gives out different Tracking Area Lists to different UEs.
In the example below we can see UE2 has a different Tracking Area List to UE1.
This means the cell edges are different for UE1 and UE2, which spreads the signaling load across Tracking Areas, so while UE2 will send a Tracking Area Update when it reaches the border from TA1 to TA4, UE1 will send a Tracking Area Update when it passes from TA6 to TA9.
The other limitation of this is now to reach a UE paging must be sent on all cells in the Tracking Area List.
As we saw with the Network Triggered Service Request, the network needs to know which eNB / cell the UE is currently being served by.
The UE knows which cell it should use as it’s always listening on the broadcast channel to know the received power levels of the nearby eNBs.
Paging
If our UE is in ECM IDLE state and the network needs to contact the UE, the eNB sends sends a Paging Request on the Beacon (Broadcast) Channel with the UE’s RNTI.
The UE is always listening on the Beacon Channel for it’s own RNTI, and when it hears it’s own RNTI it follows the process to come back from ECM_IDLE state to ECM_CONNECTED state.
For this to work the network needs to know which eNB to send the Paging request to.
For this to work our UE would need to inform the network each time it changes eNB, but, as we’ve touched upon several times, minimizing power consumption is a constant architecture constraint in LTE.
So if the UE has to transmit each time a UE moves to a different eNB / Cell, the UE power consumption would be high and the battery life of the UE would be low.
If we imagine driving along a freeway at speed, with each eNB serving an area of 1km, at 60kph, our UE would change cells every minute, and if the UE needs to transmit to let the network know it’s changing location, we’d be transmitting data every 60 seconds even if the UE is sitting in our pocket, all these transmissions would lead to lower battery life on the UE.
Tracking Areas
To work around the power wastage of each UE transmitting data to the network to let it know each time it changes eNB, 3GPP designers decided to group eNBs in the same geographic area into Tracking Areas or TAs.
This means instead of the network knowing exactly which eNB a UE is located in, it has it’s location down to a tracking area made up of several eNBs. (Tens to hundreds of cells per TA)
To go back to our freeway example, we might group all the eNBs along a freeway into one Tracking Area, all of which broadcast the ID of each eNB and the Tracking Area of each eNB.
As the UE moves from one eNB to another eNB in the same Tracking Area, there’s no need for the UE to send a Tracking Area Update message as it’s reamining in the same Tracking Area.
Tracking Area Update messages only need to be sent when the UE moves to an eNB in a different Tracking Area.
UEs can move from cell to cell inside TA1 without needing to update the network. Only when a UE moves from a eNB / cell in TA1 to TA2, does it need to send a Tracking Area Update message to the network.
Paging a Tracking Area
As the network knows the location of our UE down to a tracking area, when it comes time to Page a UE a Paging Request is simply sent from the MME to all eNBs in the Tracking Area that the UE is in.
This means the RNTI of the UE is broadcast out of all eNBs in that tracking Area, and the UE establishes connectivity once again with it’s nearest eNB.
As we discussed before when no data has been sent by a UE for a period of time the eNB will switch from an ECM-Connected state to an ECM-Idle state where there is no radio connection.
ECM-Connected state
So let’s look at the release procedure.
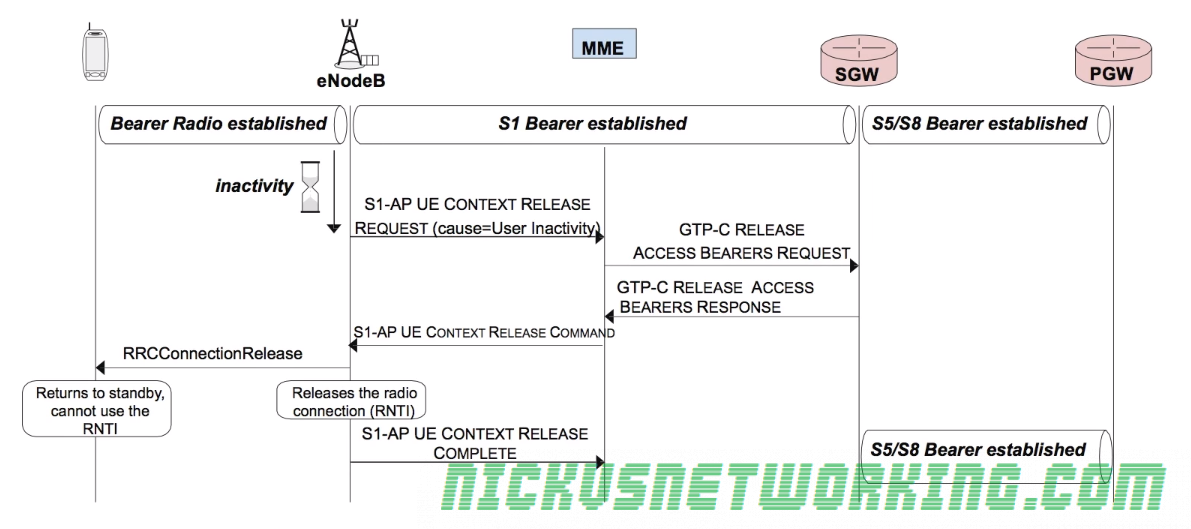
When the transmission timeout (typically 10 – 30 seconds) has expired, meaning a user hasn’t sent data for that length of time, the eNB sends the MME a S1-AP UE Context Release Request with the cause of User Inactivity to denote why the change is being made.
The MME then sends a GTP-C message requesting release of the tunnel between the S-GW and the eNB (GTP-C Release request).
The S-GW sends back a GTP-C Release Access Bearers response, indicating it has cleared down the GTP tunnel between itself and the eNB,
The MME then sends a S1-AP UE Context Release Command to the eNB, and the eNB sends an RRCConnectionRelease which releases the RNTI assigned to that UE removing it’s radio resources.
Finally a S1-AP UE Context Release Complete is sent from eNB to the MME to let the MME know the process has completed.
Release procedure
At this stage the RNTI is no longer active so the UE cannot use the RNTI and therefore cannot be assigned radio resources.
The UE is now in ECM_Idle mode, however as it still has an IP Address allocated and can be bought back it’s in EMM_Regsitered mode.
States
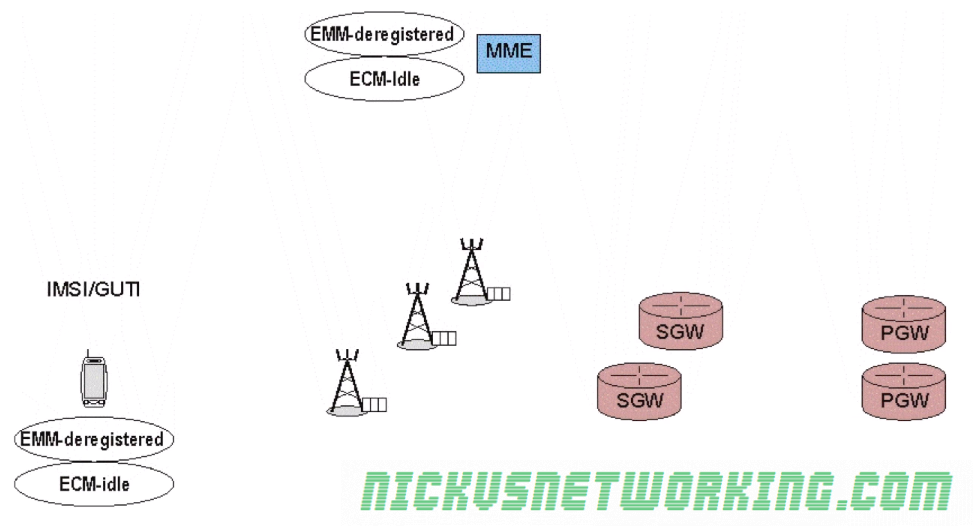
EMM-Deregistered State
UE is disconnected from the network with no radio resources and does not have an IP Address
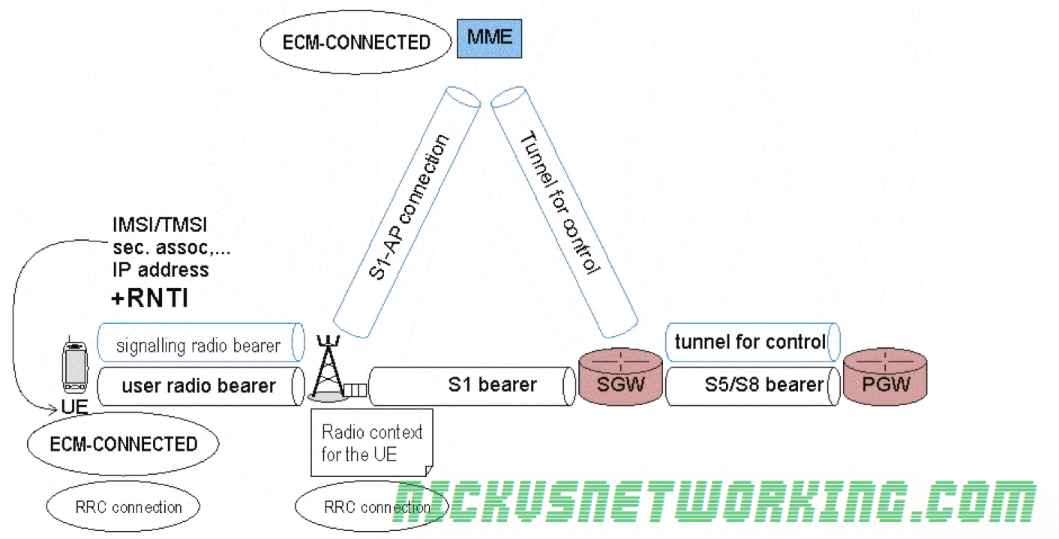
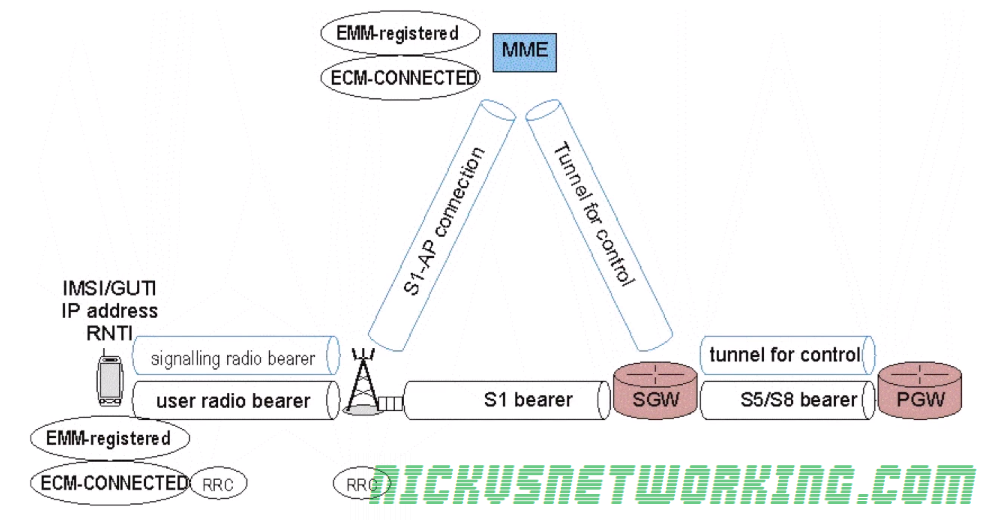
EMM-Registered & ECM-Connected
UE is connected to the network with an IP address
Radio resources (RNTI allocated)
Location of the UE known
All tunnels & connections established
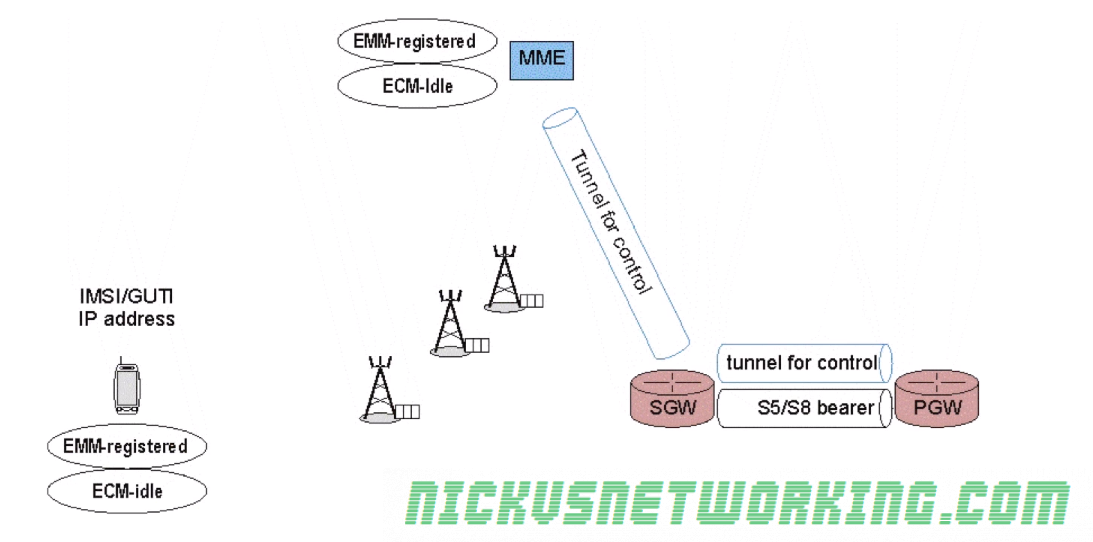
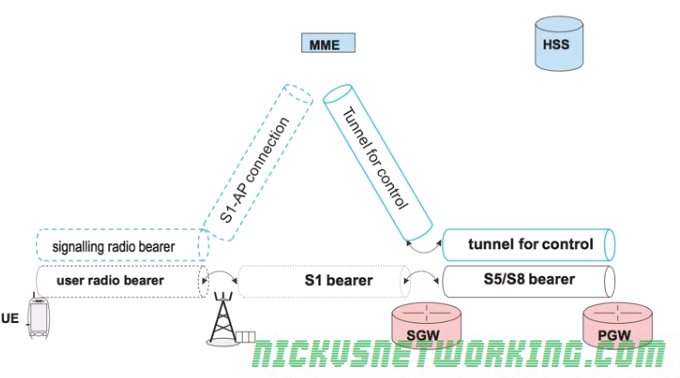
EMM-Regsitered & ECM-Idle
UE has an IP address & appears to be connected
No radio resources (RNTI) currently in use
No tunnels or connection from the eNB to the S-GW & MME.
Tunnel between S-GW and P-GW and the tunnel between the MME and S-GW
A relative location (tracking area) of the UE is available
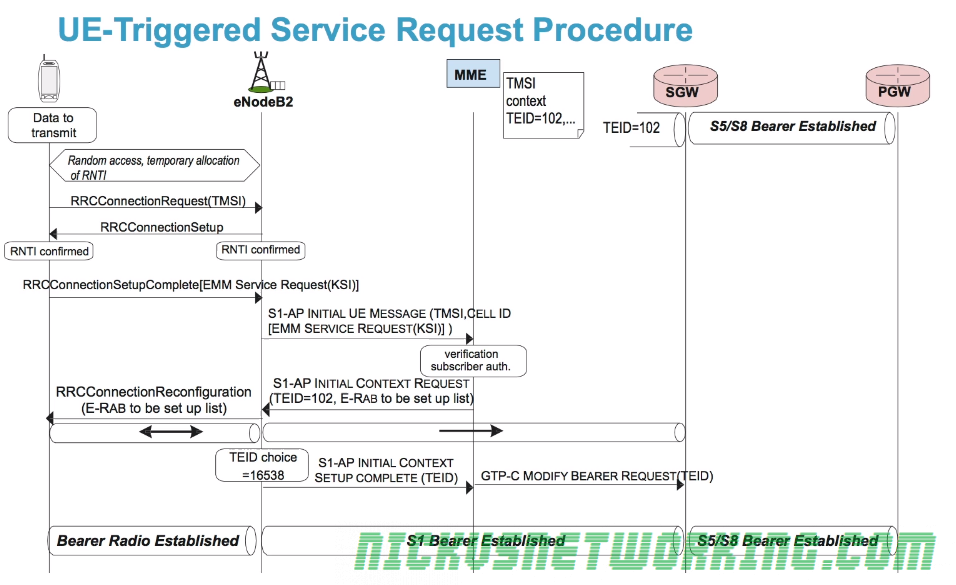
As we just saw when a terminal moves to ECC-Idle while in EMM-Registered state, it releases it’s radio resources, so what happens when the UE needs to send / receive data again?
UE is disconnected from Radio Resources (ECM-Idle & EMM Registered)
While one option could have been to go through the full attach procedure again when the UE is triggered, the 3GPP team wanted the re-connection process to be as fast as possible.
As we saw in the last post we don’t drop the S-GW <-> P-GW tunnel, which saves time on re-establishing a connection. The S1 tunnel is also not completely released; the TEID value from the S-GW end of the tunnel is saved by the MME so it can be reused by the new tunnel when the UE reconnects, without needing to inform the S-GW.
One of the common themes we cover over and over in the 4G discussion is the desire to preserve energy on the UE RF side of things, to extend battery life as much as possible.
The 3GPPs requirements for LTE also included the smallest round trip times, defining less than 5 ms in unload condition, so traffic to the UE must be routed as quickly as possible.
Mobiles are by their very nature, mobile.
This requires UEs to constantly monitor the RF conditions and the signal measurements from different base stations so the UE can determine if it’s time to handoff to another cell due to going further from one eNB and closer to another, or another eNB offering better RF conditions (Strong signal etc).
This requires regular exchanges of messages and checks, but this would take a lot of energy and eat up battery usage.
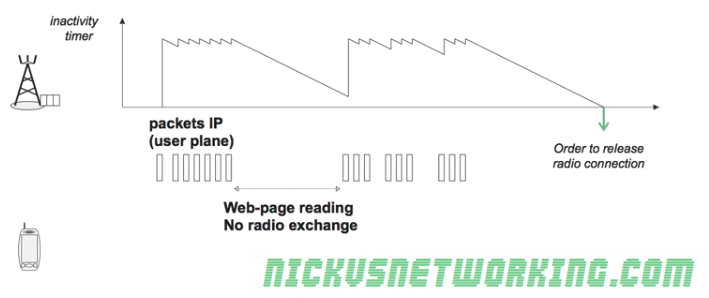
Instead we avoid maintaining the radio connection all the time with the aid of an inactivity timer on the eNB.
For as long as user data is flowing over the air interface the connection is maintained, for example web browsing, the inactivity timer is constantly reset as traffic flows.
However when the eNB detects no packets sent or received by the UE the timer starts counting down from it’s set value.
When the inactivity timer reaches 0 the RRC Connection is released and the UE no longer has an RNTI.
The UE is still listening to an eNB, it’s just not sending data to it it and visa-versa.
As the radio bearer has been removed the UE the S1-AP and S1-UP bearers between the eNB and the MME and the eNB and the S-GW respectively, can be torn down.
This means the MME is no long sure of exactly which eNB the UE is listening on.
This is referred to as ECM_IDLE state as there is no radio connection, and the network is unaware of the precise location of the UE.
An ECM_ACTIVE state is the state when the UE is connected to an eNB with an RNTI and it’s inactivity timer has not reached 0.
The dotted line bearers shown in the image above frequently change between active and inactive based on the ECM_ACTIVE / ECM_INACTIVE state of the bearers.
EPS Mobility Management (EMM) has two states – EMM-Registered (UE reachable) and EMM-Deregistered (UE not reachable).
A UE is in the deregistered state when it is not rechable, for example not currently powered up or in flight mode.
The MME memorizes the state of each UE and it’s context elements such as it’s most recent GUTI, IMSI, security parameters etc.
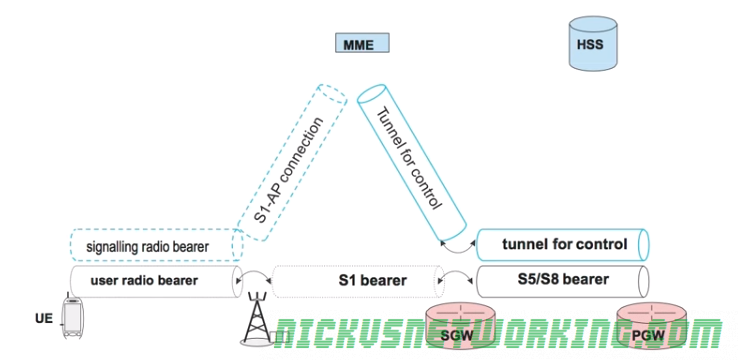
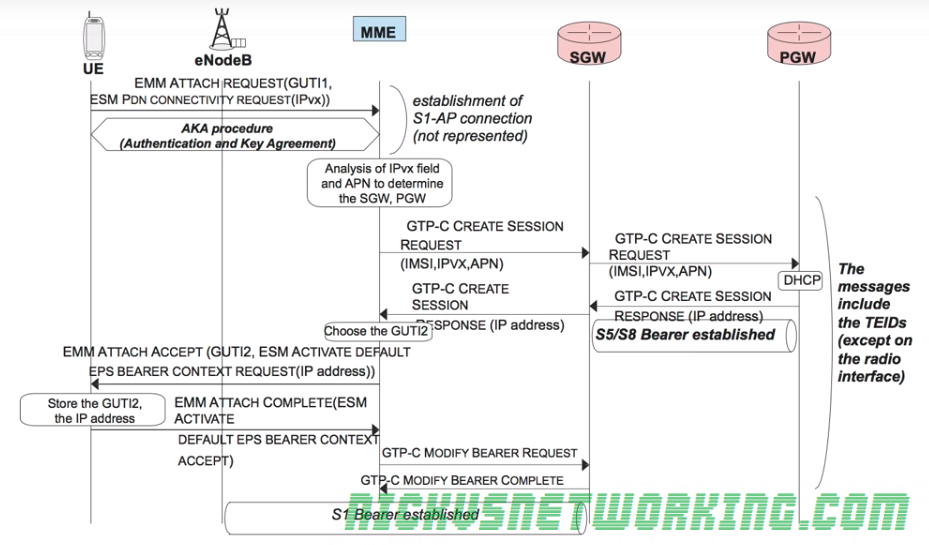
Attach Procedure
To attach to the network a UE sends an EMM Attach Request with it’s most recent GUTI to the MME.
In the same request the UE also includes an ESM PDN Connectivity Request to gain access to the external networks.
The Authentication & Key Agreement procedure is followed between the UE and the MME/HSS to authenticate the network and the subscriber.
One this is done the MME looks at the connectivity requested and the APN of the subscriber, the MME then selects a Serving-Gateway and Packet-Gateway based on the APN.
The MME then sends a GTP-C Create Session Request along with the connectivity requested (IPv4/6), APN and IMSI of the subscriber and it’s allocated TEID for this tunnel to the S-GW.
The S-GW also sends a GTP-C Create Session Request along with the connectivity requested (IPv4/6), APN and IMSI of the subscriber to the P-GW, along with the S-GW’s allocated TEID for this tunnel too.
The P-GW then sends a GTP-C Create Session back to the S-GW containing it’s TEID and it also includes the IP Address to be allocated to the UE.
A GTP session is now setup between the P-GW and the S-GW for this bearer, with the TEID values added to the TEID management tables on both devices. This GTP tunnel is referred to an S5 (home) or an S8 (roaming) Bearer in 3GPP parlance.
Another GTP-C Create Session message with it’s own TEID is also sent from the S-GW to the MME.
The MME, S-GW and P-GW now each know TEID for each of the 2 tunnels setup (MME<->S-GW, S-GW<->P-GW) so have what they need to fill their TEID management tables.
When the MME recieves the GTP-C Create Session with the IP Address for the UE it sends an EMM Attach Accept and a EPS Bearer Context Setup Request containing the IP Address the P-GW allocated to the UE to the UE itself.
The UE stores the allocated IP and sends an acknowledgement to the MME in the form of an EMM Attach Complete message back to the MME.
The MME sends a GTP-C Modify Bearer Request which transfers the bearer setup between MME and SGW and modifies it to be between the SGW and the eNB.
The S-GW sends back a GTP-C Modify Bearer Complete message and modifies the GTP tunnel to be between the SGW and the eNB. A S1 bearer is now established for carrying user data from the eNB to the SGW.
Once this procedure is complete the UE is now in the EMM Registered State meaning it is known to the MME, it has a security association and has an IP Address.
The S-GW and the P-GW also stores the TEIDs for the UE.
Detach Procedure
When a UE detaches from the network (for example it powers down), the network must release all the tunnels for that UE, the MME state must be updated to EMM Deregistered and the MME must also keep a record for the last GUTI and security keys,
To detach from the network the UE sends a RLC UL Information Transfer message containing an EMM Detach Request which includes it’s current GUTI.
As soon as the UE recivers confirmation from the eNB the UE can power down, but the eNB must inform the network of the disconnection so the resources can be released.
The eNB sends a S1Ap Uplink NAS Transport message containing a EMM Detach Request with the UE’s GUTI to the MME.
The MME can then release the security context,
The MME then sends a GTP-C Delete Session Request to the S-GW.
Upon recipt of this request the S-GW requests the P-GW tears down it’s tunnel between the P-GW and S-GW (aka the S5/S8 Bearer) by sending it’s own GTP-C Delete Session Request to the P-GW.
Once the S-GW has confirmation the tunnel has been taken down (In the form of a GTP-C Delete Session Response) the S-GW sends a GTP-C Delete Session Response to the MME.
The MME must signal to the eNB it can release the RNTI and the radio resources. To do this it sends a S1-AP UE Context Release Command which releases the radio bearers and tears down the S1-UP bearer between the eNB and the S-GW.
The eNB then sends a S1-AP UE Context Release Completeto the MME.
Finally the MME sends a Diameter Notification Request (PGW and APN Removed) to the HSS to update the HSS of the user’s status, the HSS signals back with a Diameter Notification Answer and the HSS knows the user is no longer reachable.