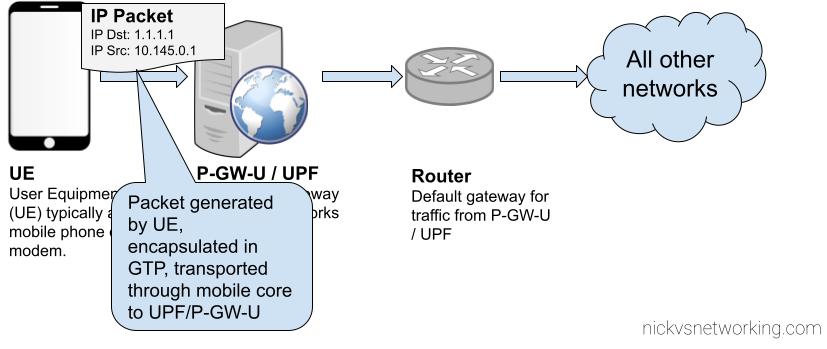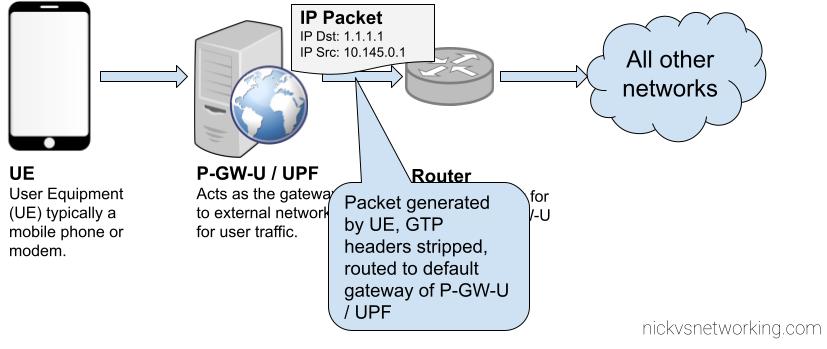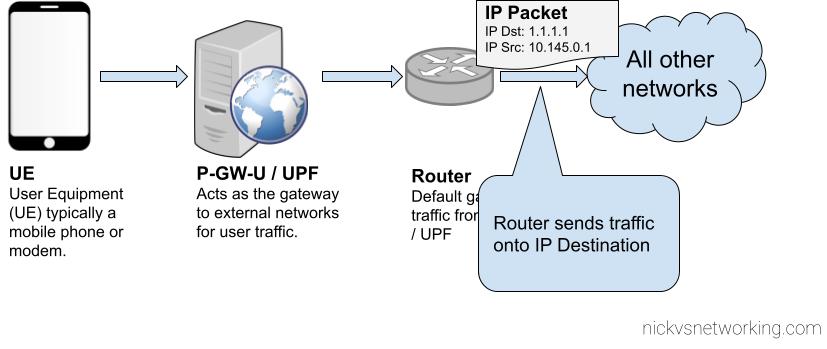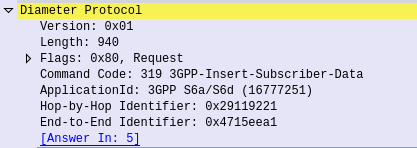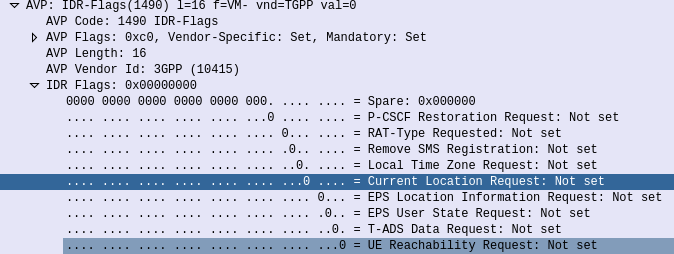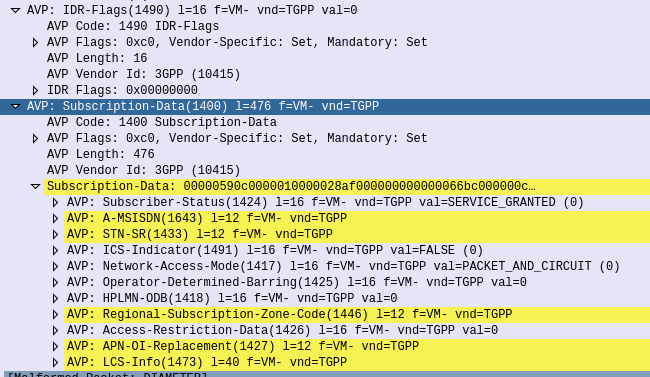
So you have a VoIP service and you want to rate the calls to charge your customers?
You’re running a mobile network and you need to meter data used by subscribers?
Need to do least-cost routing?
You want to offer prepaid mobile services?
Want to integrate with Asterisk, Kamailio, FreeSWITCH, Radius, Diameter, Packet Core, IMS, you name it!
Well friends, step right up, because today, we’re talking CGrates!
So before we get started, this isn’t going to be a 5 minute tutorial, I’ve a feeling this may end up a big multipart series like some of the others I’ve done.
There is a learning curve here, and we’ll climb it together – but it is a climb.
Installation
Let’s start with a Debian based OS, installation is a doddle:
sudo wget -O - https://apt.cgrates.org/apt.cgrates.org.gpg.key | sudo apt-key add - echo "deb http://apt.cgrates.org/debian/ nightly main" | sudo tee /etc/apt/sources.list.d/cgrates.list sudo apt-get update sudo apt-get install cgrates -y apt-get install mysql-server redis-server git -y
We’re going to use Redis for the DataDB and MariaDB as the StorDB (More on these concepts later), you should know that other backend options are available, but for keeping things simple we’ll just use these two.
Next we’ll get the database and config setup,
cd /usr/share/cgrates/storage/mysql/ ./setup_cgr_db.sh root CGRateS.org localhost cgr-migrator -exec=*set_versions -stordb_passwd=CGRateS.org
Lastly we’ll clone the config files from the GitHub repo:
https://github.com/nickvsnetworking/CGrates_Tutorial
Rating Concepts
So let’s talk rating.
In its simplest form, rating is taking a service being provided and calculating the cost for it.
The start of this series will focus on voice calls (With SMS, MMS, Data to come), where the calling party (The person making the call) pays, so let’s imagine calling a Mobile number (Starting with 614) costs $0.22 per minute.
To perform rating we need to determine the Destination, the Rate to be applied, and the time to charge for.
For our example earlier, a call to a mobile (Any number starting with 614) should be charged at $0.22 per minute. So a 1 minute call will cost $0.22 and a 2 minute long call will cost $0.44, and so on.
We’ll also charge calls to fixed numbers (Prefix 612, 613, 617 and 617) at a flat $0.20 regardless of how long the call goes for.
So let’s start putting this whole thing together.
Introduction to RALs
RALs is the component in CGrates that takes care of Rating and Accounting Logic, and in this post, we’ll be looking at Rating.
The rates have hierarchical structure, which we’ll go into throughout this post. I took my notepad doodle of how everything fits together and digitized it below:
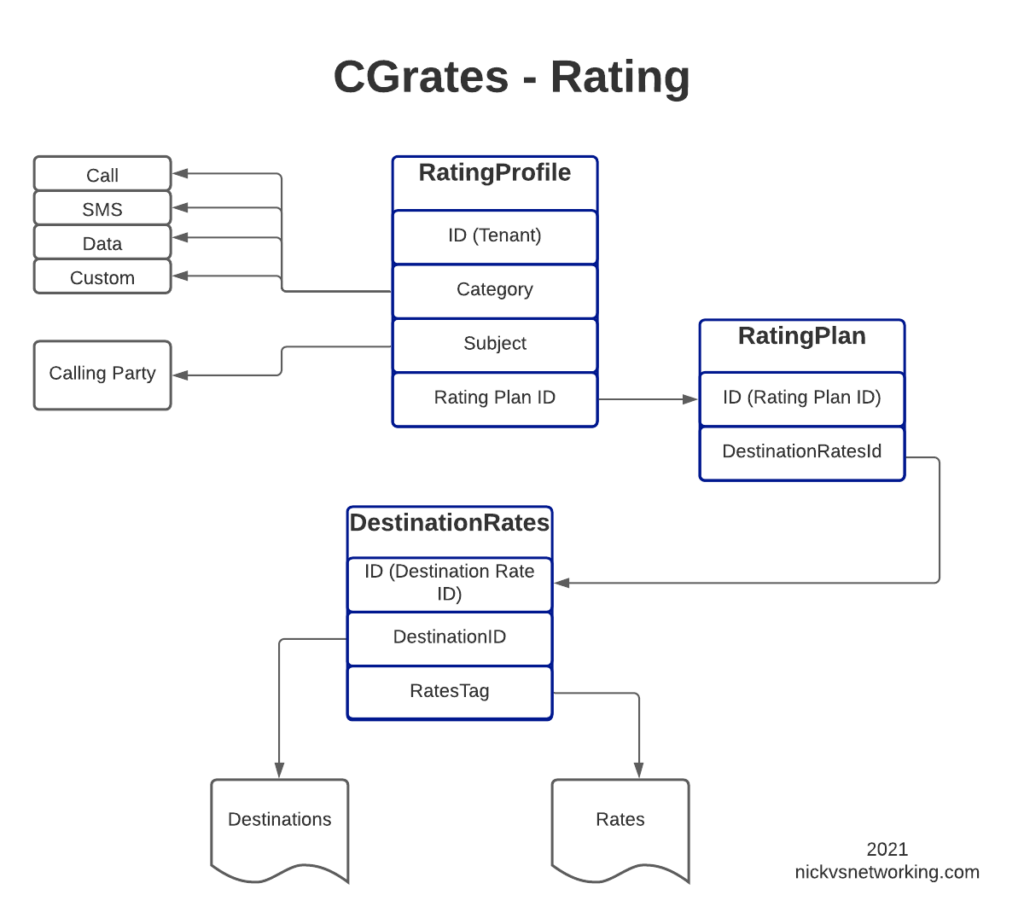
Destinations
Destinations are fairly simple, we’ll set them up in our Destinations.csv file, and it will look something like this:
#Id,Prefix DST_AUS_Mobile,614 DST_AUS_Fixed,612 DST_AUS_Fixed,613 DST_AUS_Fixed,617 DST_AUS_Fixed,618 DST_AUS_Toll_Free,611300 DST_AUS_Toll_Free,611800
Each entry has an ID (referred to higher up as the Destination ID), and a prefix.
Also notice that some Prefixes share an ID, for example 612, 613, 617 & 618 are under the Destination ID named “DST_AUS_Fixed”, so a call to any of those prefixes would match DST_AUS_Fixed.
Rates
Rates define the price we charge for a service and are defined by our Rates.csv file.
#Id,ConnectFee,Rate,RateUnit,RateIncrement,GroupIntervalStart RT_22c_PM,0,22,60s,60s,0s RT_20c_Untimed,20,0,60s,60s,0s RT_25c_Flat,25,0,60s,60s,0s
Let’s look at the fields we have:
- ID (Rate ID)
- ConnectFee – This is the amount charged when the call is answered / connected
- The Rate is how much we will charge, it’s loosely cents, but could be any currency. By default CGrates looks down to 4 decimal places.
- RateUnit is how often this rate is applied in seconds
- RateIncriment is how often this is evaluated in seconds
- GroupIntervalStart – Activates an event when triggered
So let’s look at how this could be done, and the gotchas that exist.
So let’s look at some different use cases and how we’d handle them.
Per Minute Billing
This would charge a rate per minute, at the start of the call, the first 60 seconds will cost the caller $0.25.
At the 61 second mark, they will be charged another $0.25.
60 seconds after that they will be charged another $0.25 and so on.
#Id,ConnectFee,Rate,RateUnit,RateIncrement,GroupIntervalStart RT_25c_PM_PerMinute_Billing,0,25,60s,60s,0s
This is nice and clean, a 1 second call costs $0.25, a 60 second call costs $0.25, and a 61 second call costs $0.50, and so on.
This is the standard billing mechanism for residential services, but it does not pro-rata the call – For example a 1 second call is the same cost as a 59 second call ($0.25), and only if you tick over to 61 seconds does it get charged again (Total of $0.50).
Per Second Billing
If you’re doing a high volume of calls, paying for a 3 second long call where someone’s voicemail answers the call and was hung up, may seem a bit steep to pay the same for that as you would pay for 59 seconds of talk time.
Instead Per Second Billing is more common for high volume customers or carrier-interconnects.
This means the rate still be set at $0.25 per minute, but calculated per second.
So the cost of 60 seconds of call is $0.25, but the cost of 30 second call (half a minute) should cost half of that, so a 30 second call would cost $0.125.
#Id,ConnectFee,Rate,RateUnit,RateIncrement,GroupIntervalStart RT_25c_PM_PerSecond_Billing,0,25,60s,1s,0s
How often we asses the charging is defined by the RateIncrement parameter in the Rate Table.
We could achieve the same outcome another way, by setting the RateIncriment to 1 second, and the dividing the rate per minute by 60, we would get the same outcome, but would be more messy and harder to maintain, but you could think of this as $0.25 per minute, or $0.004166667 per second ($0.25/60 seconds).
Flat Rate Billing
Another option that’s commonly used is to charge a flat rate for the call, so when the call is answered, you’re charged that rate, regardless of the length of the call.
Regardless if the call is for 1 second or 10 hours, the charge is the same.
#Id,ConnectFee,Rate,RateUnit,RateIncrement,GroupIntervalStart RT_25c_Flat,25,0,60s,60s,0s
For this we just set the ConnectFee, leaving the Rate at 0, so the cost will be applied on connection, with no costs applied per time period.
This means a 1 second call will cost $0.25, while a 3600 second call will still cost $0.25.
We charge a connect fee, but no rate.
Linking Destinations to the Rates to Charge
Now we’ve defined our Destinations and our Rates, we can link the two, defining what Destinations get charged what Rates.
This is defined in DestinationRates.csv
#Id,DestinationId,RatesTag,RoundingMethod,RoundingDecimals,MaxCost,MaxCostStrategy DR_AUS_Mobile,DST_AUS_Mobile,RT_22c_PM,*up,4,0.12,*disconnect DR_AUS_Fixed,DST_AUS_Fixed,RT_20c_Untimed,*up,4,0.12,*disconnect DR_AUS_Toll_Free,DST_AUS_Toll_Free,RT_25c_Flat,*up,4,0.12,*disconnect
Let’s look at the Fields,
- ID (Destination Rate ID)
- DestinationID – Refers to the DestinationID defined in the Destinations.csv file
- RatesTag – Referes to the Rate ID we defined in Rates.csv
- RoundingMethod – Defines if we round up or down
- RoundingDecimals – Defines how many decimal places to consider before rounding
- MaxCost – The maximum cost this can go up to
- MaxCostStrategy – What to do if the Maximum Cost is reached – Either make the rest of the call Free or Disconnect the call
So for each entry we’ll define an ID, reference the Destination and the Rate to be applied, the other parts we’ll leave as boilerplate for now, and presto. We have linked our Destinations to Rates.
Rating Plans
We may want to offer different plans for different customers, with different rates.
That’s what we define in our Rating Plans.
#Id,DestinationRatesId,TimingTag,Weight RP_AUS,DR_AUS_Mobile,*any,10 RP_AUS,DR_AUS_Fixed,*any,10 RP_AUS,DR_AUS_Toll_Free,*any,10
- ID (RatingPlanID)
- DestinationRatesId (As defined in DestinationRates.csv)
- TimingTag – References a time profile if used
- Weight – Used to determine what precedence to use if multiple matches
So as you may imagine we need to link the DestinationRateIDs we just defined together into a Rating Plan, so that’s what I’ve done in the example above.
Rating Profiles
The last step in our chain is to link Customers / Subscribers to the profiles we’ve just defined.
How you allocate a customer to a particular Rating Plan is up to you, there’s numerous ways to approach it, but for this example we’re going to use one Rating Profile for all callers coming from the “cgrates.org” tenant:
#Tenant,Category,Subject,ActivationTime,RatingPlanId,RatesFallbackSubject cgrates.org,call,*any,2014-01-14T00:00:00Z,RP_AUS,
Let’s go through the fields here,
- Tenant is a grouping of Customers
- Category is used to define the type of service we’re charging for, in this case it’s a call, but could also be an SMS, Data usage, or a custom definition.
- Subject is typically the calling party, we could set this to be the Caller ID, but in this case I’ve used a wildcard “*any”
- ActivationTime allows us to define a start time for the Rating Profile, for example if all our rates go up on the 1st of each month, we can update the Plans and add a new entry in the Rating Profile with the new Plans with the start time set
- RatingPlanID sets the Rating Plan that is used as we defined in RatingPlans.csv
Loading the Rates into CGrates
At the start we’ll be dealing with CGrates through CSV files we import, this is just one way to interface with CGrates, there’s others we’ll cover in due time.
CGRates has a clever realtime architecture that we won’t go into in any great depth, but in order to load data in from a CSV file there’s a simple handy tool to run the process,
root@cgrateswitch:/home/nick# cgr-loader -verbose -path=/home/nick/tutorial/ -flush_stordb
Obviously you’ll need to replace with the folder you cloned from GitHub.
Trying it Out
In order for CGrates to work with Kamailio, FreeSWITCH, Asterisk, Diameter, Radius, and a stack of custom options, for rating calls, it has to have common mechanisms for retrieving this data.
CGrates provides an API for rating calls, that’s used by these platforms, and there’s a tool we can use to emulate the signaling for call being charged, without needing to pickup the phone or integrate a platform into it.
root@cgrateswitch:/home/nick# cgr-console 'cost Category="call" Tenant="cgrates.org" Subject="3005" Destination="614" AnswerTime="2014-08-04T13:00:00Z" Usage="60s"'
The tenant will need to match those defined in the RatingProfiles.csv, the Subject is the Calling Party identity, in our case we’re using a wildcard match so it doesn’t matter really what it’s set to, the Destination is the destination of the call, AnswerTime is time of the call being answered (pretty self explanatory) and the usage defines how many seconds the call has progressed for.
The output is a JSON string, containing a stack of useful information for us, including the Cost of the call, but also the rates that go into the decision making process so we can see the logic that went into the price.
{
"AccountSummary": null,
"Accounting": {},
"CGRID": "",
"Charges": [
{
"CompressFactor": 1,
"Increments": [
{
"AccountingID": "",
"CompressFactor": 1,
"Cost": 0,
"Usage": "0s"
},
{
"AccountingID": "",
"CompressFactor": 1,
"Cost": 25,
"Usage": "1m0s"
}
],
"RatingID": "febb614"
}
],
"Cost": 25,
"Rates": {
"7d4a755": [
{
"GroupIntervalStart": "0s",
"RateIncrement": "1m0s",
"RateUnit": "1m0s",
"Value": 25
}
]
},
"Rating": {
"febb614": {
"ConnectFee": 0,
"MaxCost": 0.12,
"MaxCostStrategy": "*disconnect",
"RatesID": "7d4a755",
"RatingFiltersID": "7e42edc",
"RoundingDecimals": 4,
"RoundingMethod": "*up",
"TimingID": "c15a254"
}
},
"RatingFilters": {
"7e42edc": {
"DestinationID": "DST_AUS_Mobile",
"DestinationPrefix": "614",
"RatingPlanID": "RP_AUS",
"Subject": "*out:cgrates.org:call:3005"
}
},
"RunID": "",
"StartTime": "2014-08-04T13:00:00Z",
"Timings": {
"c15a254": {
"MonthDays": [],
"Months": [],
"StartTime": "00:00:00",
"WeekDays": [],
"Years": []
}
},
"Usage": "1m0s"
}
So have a play with setting up more Destinations, Rates, DestinationRates and RatingPlans, in these CSV files, and in our next post we’ll dig a little deeper… And throw away the CSVs all together!
Other posts in the CGrateS in Baby Steps series:
- CGrateS Part 1 – Basics of CGrateS
- CGrateS in Baby Steps – Part 2 – Adding Rates and Destinations through the API
- CGrateS in Baby Steps – Part 3 – RatingProfiles & RatingPlans
- CGrateS in Baby Steps – Part 4 – Rating Calls
- CGrateS in Baby Steps – Part 5 – Events, Agents & Subsystems
- All the other posts tagged with CGrateS including SessionS, Attributes, Accounts & Balances, Actions & Action Plans, ActionTriggers, FilterS, StatS, Event Reader, CDR Export.