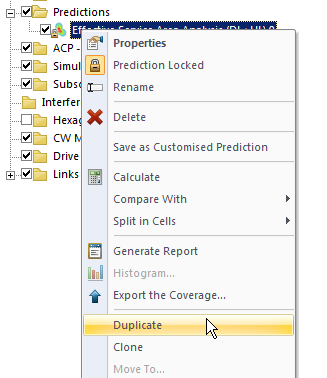
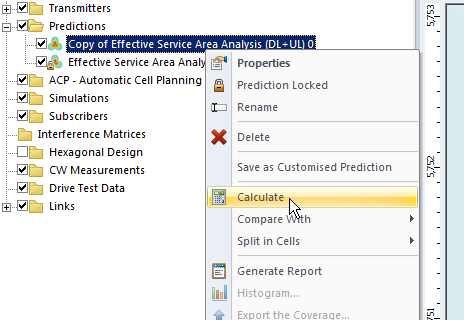
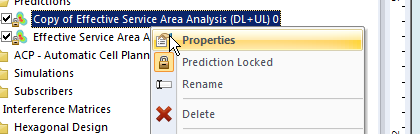
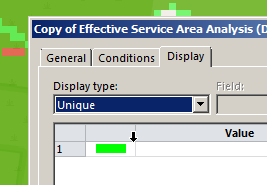
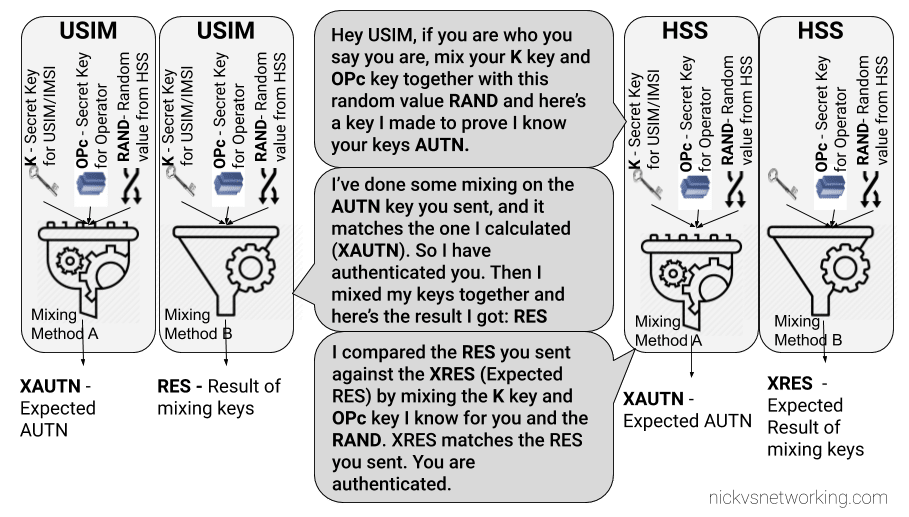
I’ve talked about how LTE’s EUTRAN / EPC has no knowledge about voice calls or SMS and instead relies on IMS/VoLTE for these services.
Circuit Switched Fallback allows UEs to use a 2G or 3G network (Circuit Switched network) if their device isn’t connected to the IMS network to make calls as the 2G/3G network can handle the voice call or SMS routing via the Mobile Switching Center in the 2G/3G network.
However for incoming calls destined to the UE (Mobile Terminated) the MSC needs a way to keep track of which MME is serving the UE so it can get a message to the MME and the MME can relay it to the UE, to tell it to drop to a 2G or 3G network (Circuit Switched network).
The signalling between the MME (In the LTE EPC) and the MSC (In the GSM/UTRAN core) is done over the SGs interface.
While the SGs interface is primarily for managing user location state across multiple RAN types, it’s got a useful function for sending SMS over SGi, allowing users on an LTE RAN to send SMS via the MSC of the 2G/3G network (GSM/UTRAN core).
How it Works:
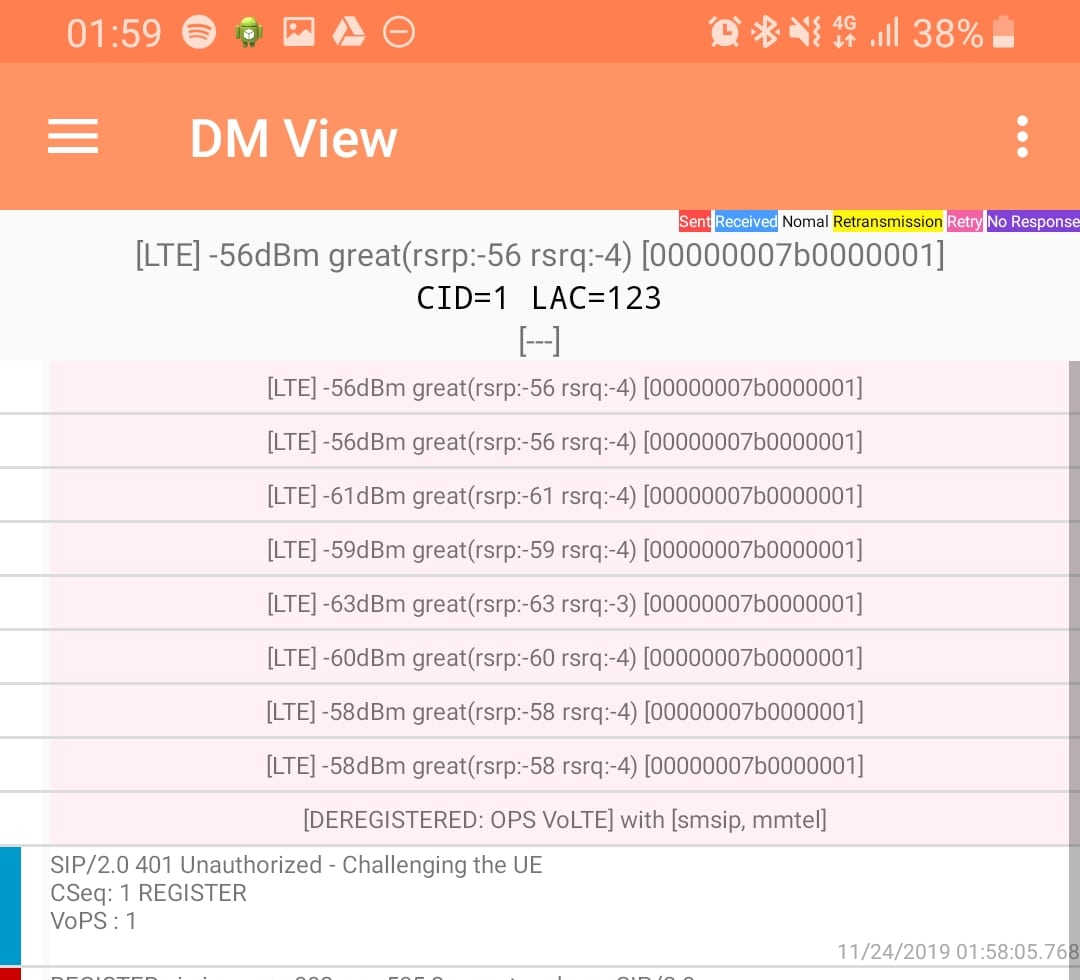
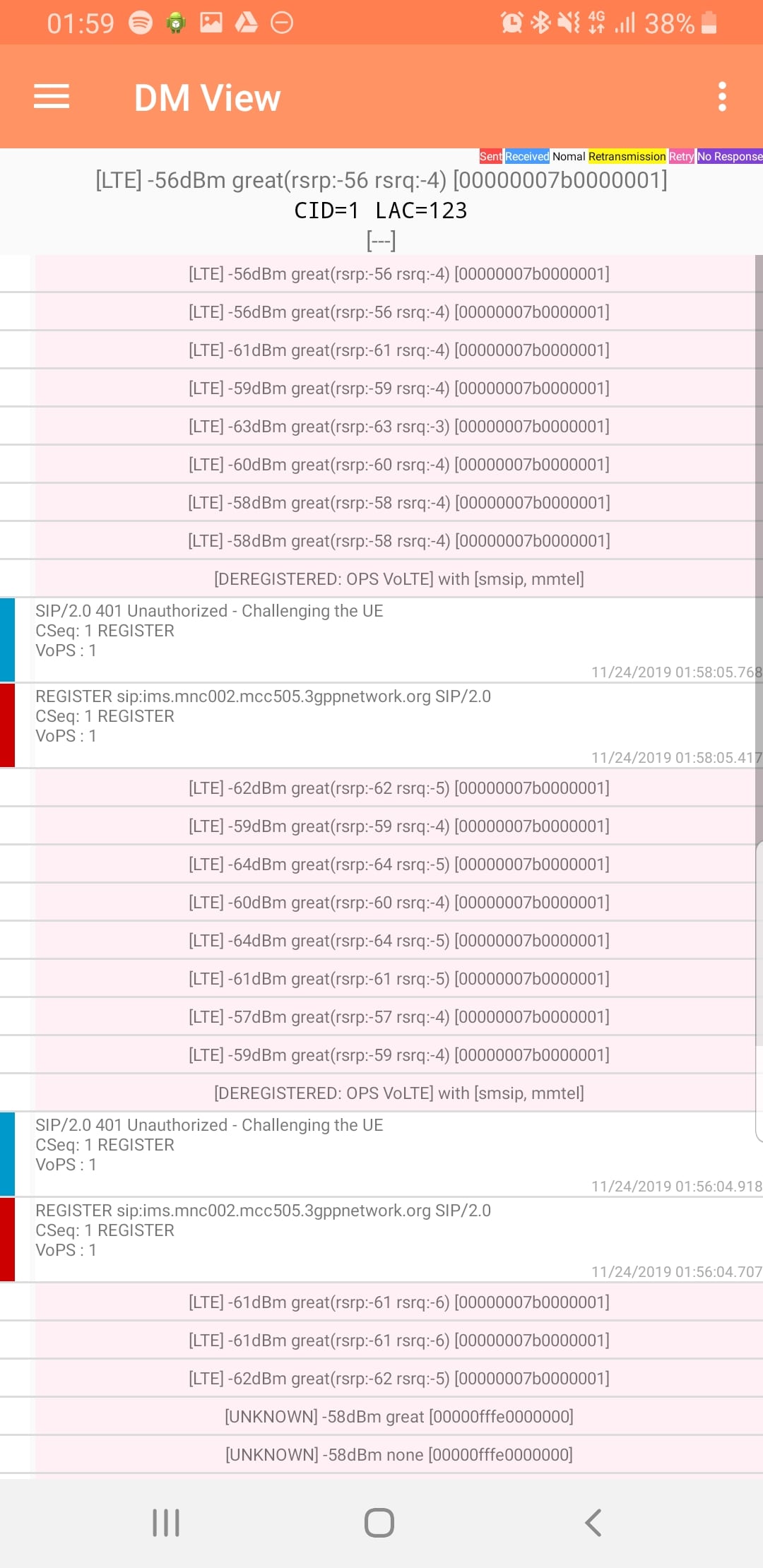
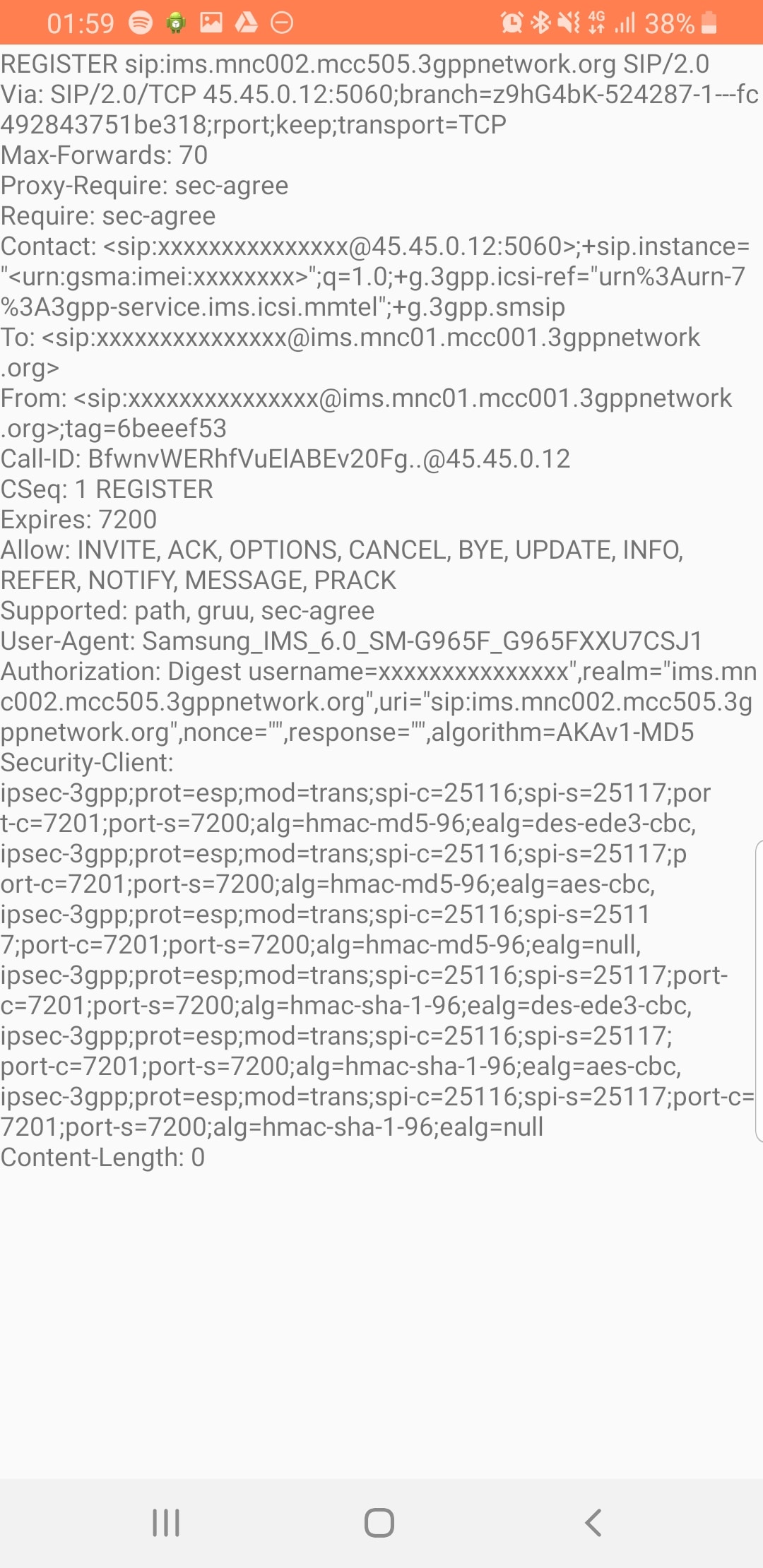
When a UE connects to the LTE RAN (EUTRAN) the MME signals the GSM/UMTS MSC with an SGsAP-LOCATION-UPDATE-REQUEST,
This request includes the IMSI of the subscriber that just attached and the FQDN of the MME serving that UE.
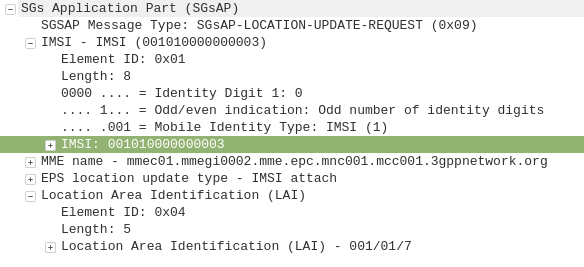
The MSC now knows that IMSI 001010000000003 is currently on LTE RAN served by MME mmec01.mmegi0002.mme.epc.mnc001.mcc001.3gppnetwork.org,
If a call or SMS comes into the MSC destined for the MSISDN of that IMSI, the MSC can page the UE on the LTE RAN to tell it to do an inter-RAN handover to GSM/UMTS.
Setting it Up
In order to get this working you’ll need OsmoMSC in place, your subscribers to exist on OsmoHLR and the LTE HSS – For example Open5GS-HSS.
If you’re not familiar with OsmoMSC or the Osmocom stack I did a series of posts covering them you can find here. If you want to get this setup I’d suggest following the posts on installing the Osmocom Software, setting up the MSC, the STP and the HLR.
Once you’ve done that the additional config on OsmoMSC is fairly simple, we just define a new SGs interface to listen on:
OsmoMSC Config:
sgs local-port 29118 local-ip 0.0.0.0 vlr-name vlr.msc001.mnc001.mcc001.3gppnetwork.org end
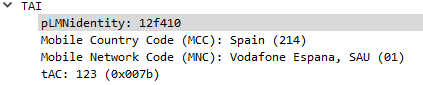
On the Open5GS side we’ve got to include the SGs info the MME config. Keep in mind the Tracking Area Code (TAC) in LTE must exist as the Location Area code (LAC) in GSM, here’s an extract of the MME section of YAML config in the Open5GS MME config:
mme:
freeDiameter: /etc/freeDiameter/mme.conf
s1ap:
gtpc:
sgsap:
addr: 10.0.1.9
map:
tai:
plmn_id:
mcc: 001
mnc: 01
tac: 7
lai:
plmn_id:
mcc: 001
mnc: 01
lac: 7
gummei:
plmn_id:
mcc: 001
mnc: 01
mme_gid: 2
mme_code: 1
tai:
plmn_id:
mcc: 001
mnc: 01
tac: 7
security:
integrity_order : [ EIA1, EIA2, EIA0 ]
ciphering_order : [ EEA0, EEA1, EEA2 ]
network_name:
full: Open5GS
sgw:
gtpc:
addr: 127.0.0.2
addr: 10.0.1.252
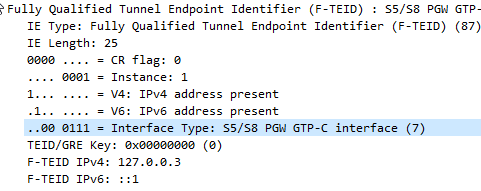
pgw:
gtpc:
addr:
- 127.0.0.3
- ::1Neighbours Configured
The EUTRAN will need to advertise the presence of it’s GERAN neighbours and vise-versa so the UE/terminals know what ARFCN to move to so they don’t need to scan for the presence of other RATs when performing the handover.
Setting this up will depend on your eNB / BSC and goes beyond the scope of this post.
I’ll cover setting up neighbours in a later post as it’s a big topic.
If you don’t have neighbours configured, the handover will still work but will be much slower as the UE will have to scan to find the serving cell it’s reselecting to.