I started working on a private LTE project a while ago; RAN hardware (eNodeBs) were on the way, down to a shortlist of a few EPC platforms, but I still needed USIMs before anyone was connecting to the network.
So why are custom USIMs a requirement? Can’t you just use any old USIM/SIMs?
For roaming to work between carriers they’ve got to have their HSS / DRA connecting to the DRA or HSS of other carriers, to allow roaming subscribers to access the network, otherwise they too would fall foul of the mutual network authentication and the USIM wouldn’t connect to the network.
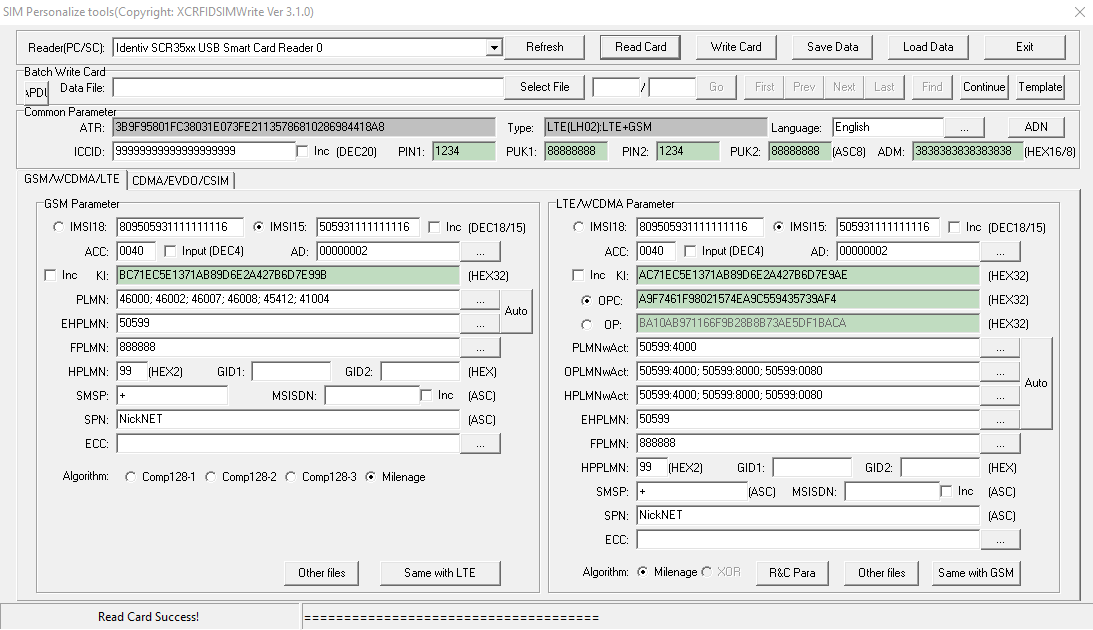
The first USIMs I purchased online through a popular online marketplace with a focus on connecting you to Chinese manufacturers. They listed a package of USIMS, a USB reader/writer that supported all the standard USIM form factors and the software to program it, which I purchased.
The USIMs worked fairly well – They are programmable via a card reader and software that, although poorly translated/documented, worked fairly well.
USIM Programming Interface
K and OP/OPc values could be written to the card but not read, while the other values could be read and written from the software, the software also has the ability to sequentially program the USIMs to make bulk operations easier. The pricing worked out about $8 USD per USIM, which although expensive for the quantity and programmable element is pretty reasonable.
Every now and then the Crypto values for some reason or another wouldn’t get updated, which is exactly as irritating as it sounds.
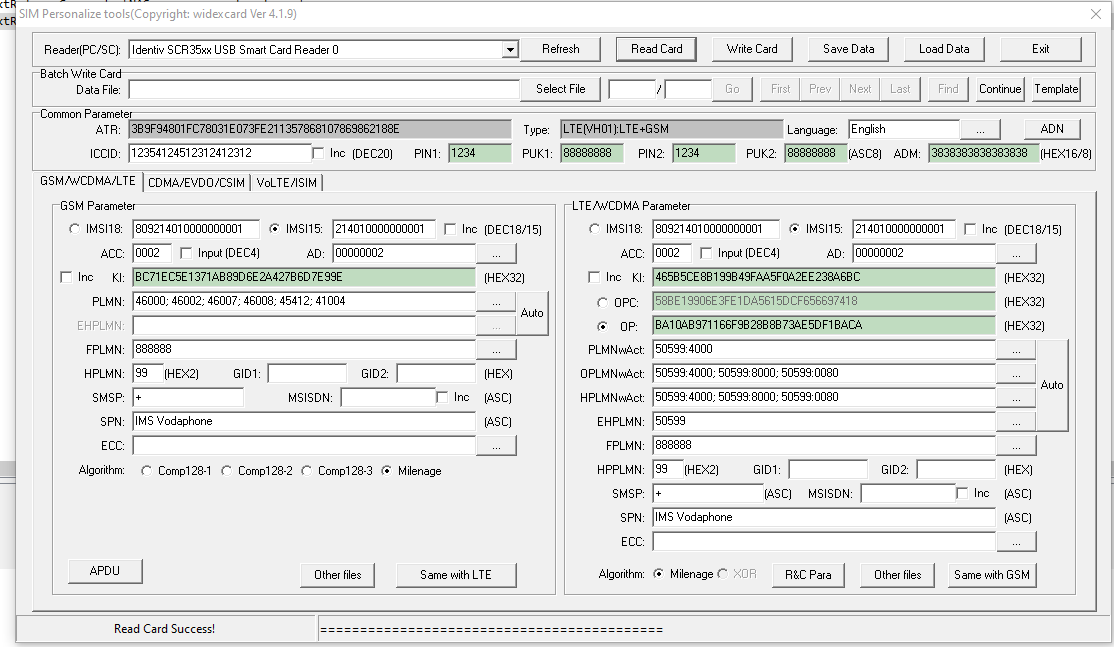
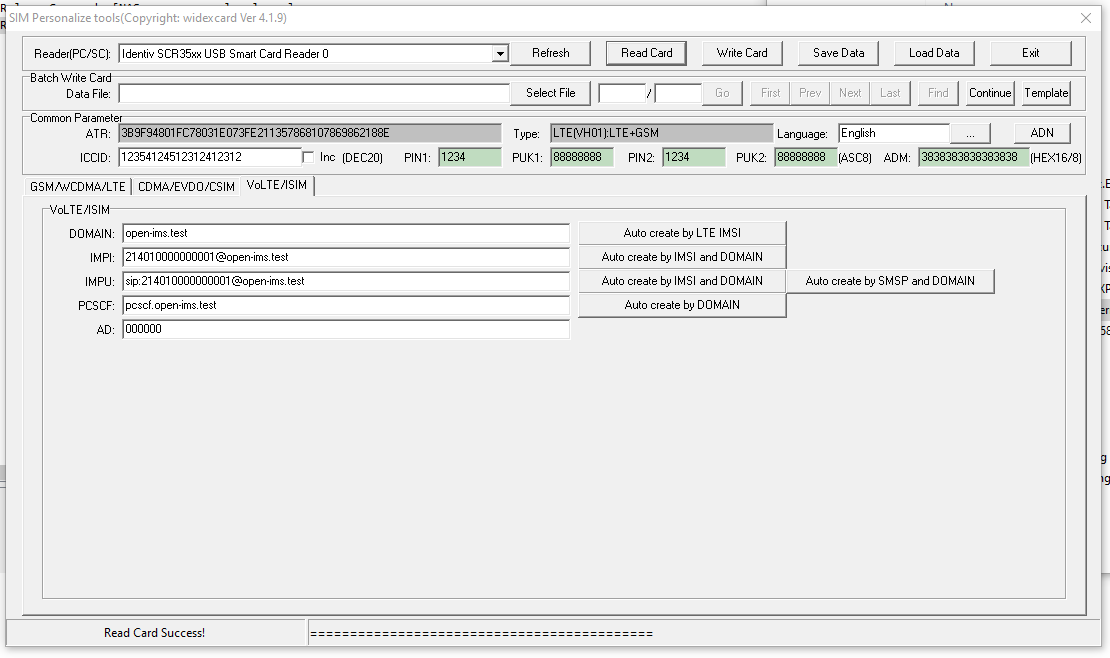
Pretty quickly into the build I learned the USIMs didn’t include an ISIM service on the card, ISIM being the service that runs on the UCCID responsible for IMS / VoLTE authentication.
Again I went looking and reached out to a few manufacturers of USIMs.
The big vendors, Gemalto, Kona, etc, weren’t interested in providing USIMs in quantities less than 100,000 and their USIMs came from the factory pre-programmed, meaning the values could only be changed through remote SIM provisioning, a form of black magic.
In the end I reached out to an OEM manufacturer from China who provided programmable USIM / ISIMs for less than I was paying on the online marketplace and at any quantity I wanted with custom printing options, allocated ICCIDs, etc.
The non-programmable USIMs worked out less than $0.40 USD each in larger quantities, and programmable USIM/ISIMs for about $5 USD.
The software was almost identical except for the additional tab for ISIM operations.
USIM / ISIM programmingISIM parameters
Smart Card Readers
In theory this software and these USIMs could be programmed by any smart card reader.
In practice, the fact that the ISO standard smart card is the same size as a credit card, means most smart card readers won’t fit the bill.
I tried a few smart card readers, from the one built into my Thinkpad, to a Bluedrive II from one of the USIM vendors, in the end the MCR3516 Smart Card Reader which reads 4FF USIMs (Standard ISO size smart card, full size SIM, Micro SIM and Nano SIM form factors, which saved on so much mucking about with form factor adapters etc.
4FF Smart Card Reader for programming SIM/USIM/ISIM
Future Projects
I’ve got some very calls “Multi Operator Neutral Host” (MoNEH) USIMs from the guys at Telet Research I’m looking forward to playing with,
eSIMs are on my to-do list too, and the supporting infrastructure, as well as Over the Air updating of USIMs.
The numbering system lists all the phone numbers in Australia and the carrier they’re assigned to (Donor Carrier when ported).
This means each carrier downloads this data from what is now ACMA (but was at the time ACA) and for each outgoing call look the number up in that data set and route to the correct carrier.
This routing is used when a number has not been ported – The CSP it’s allocated to by ACMA is the CSP to route calls to.
During Porting – Donor & Losing CSP the Same
At the time the number is ported the Losing CSP provides Donor Transit Routing – In practice this is nothing more than a fancy redirection/ forward to the new carrier.
Once the port is completed (and the Emergency Porting Return period has expired) the Losing CSP (who in this case is also the donor CSP) updates their PLNR file, to include the number that’s just been ported out and the new carrier’s code.
During Porting – Donor & Losing CSP Different (3rd Party Porting)
At the time the number is ported the Losing CSP provides Donor Transit Routing – In practice this is nothing more than a fancy redirection/ forward to the new carrier.
Once the port is completed (and the Emergency Porting Return period has expired) the Donor CSP updates their PLNR file, to update the record for the ported number, which previously showed the code of the Losing CSP and now must show the new CSP code.
After Porting – PLNR Update
After the PLNR has been updated by the Donor CPSs, other CPS that participate in porting must update their routing records to ensure they route directly to the Gaining CSP and not to the Donor CSP and rely on Donor Routing.
Donor Routing is only required to be in place for a short time, meaning carriers that don’t update their routes will find the ported destination unreachable once donor transit routing has been stopped.
Why am I still billed after a number is ported out?
The Losing CSP does not need to take any action to disconnect Customer’s Telephone Number(s).
3.4.3
This means just porting out a number from a CSP doesn’t mean billing from the Loosing CSP will stop.
Continuing contractual agreements between the customer and Loosing CSP may still be in place and the customer is responsible for requesting the services be cancelled with the Loosing CSP.
Some CSPs work out that if you’re porting out a number you don’t want their services anymore, but they’re not obliged to and most will do what they can get away with.
What is a Bilateral Peering Agreement?
While a customer is legally entitled to move a number they have full control over (As outlined in Telecommunications Numbering Plan 2015), in practice phone numbers can only be moved from one carrier to another if both CSPs have a Bilateral Peering Agreement with each other.
These agreements primarily sort out the commercials of how much they’ll pay each other per port in / out.
It’s worth also noting that the Code only defines the minimum standard and process, two CSPs that have a bilateral peering agreement in place are able to process ports faster and more efficiently than the minimum standard outlined in the code.
Carriage Service Provider vs Carrier?
I’ve been sing the term Carriage Service Provider and Carrier interchangeably.
The difference as far as the code is concerned is one is who a customer pays for the service, while the other is the provider of the service. Generally it’s safe to assume that the CSP is also the Carrier and not a re-seller.
These numbers can be ported to other CSPs (this is after all what LNP is all about) but after the number is routed to a different carrier the Donor Carrier remains the carrier listed in the Numbering Plan.
The Donor Carrier is responsible for Donor Transit Routing (A temporary redirect to numbers that have been ported away recently) for any numbers that have recently been ported out, and publishing the number and new carrier details for each number ported out in their PLNR file.
These numbers can be ported to other CSPs (this is after all what LNP is all about) but after the number is routed to a different carrier the Donor Carrier remains the carrier listed in the Numbering Plan.
In a scenario where a call needs to route to a destination where the current carrier for that destination is unknown, the call is routed to the Donor Carrier, as that’s who the number is originally allocated to by ACMA.
Upon reciept of a call by the donor carrier to a number that has been ported out, the donor’s switch finds the correct Access Service Deliver (ASD) and redirects the call to them.
This is a temporary service – CSPs are only obliged to do this for 5 days, after which it’s assumed the PLNR file of the donor will have been read by all the other CSPs and they’ll be routing the traffic to the correct CSP and not the Donor CSP.
Third Party Ports
Third Party Porting is where the Donor Carrier is neither the Losing Carrier or the Gaining Carrier. Third Party Porting requires bilateral agreements to be in place between each of the parties involved.
As we just covered ACMA allocates numbers to CSPs, when a number is ported to a different CSP the number is still allocated to the original CSP as far as ACMA and The Numbering System are concerned.
The CSP the number was originally allocated to is the Donor CSP – forever.
Let’s look at a two party port first:
A number is allocated by ACMA to CSP 1
The customer using that number decides to port the to CSP 2 using the standard LNP process
CSP 1 performs Donor Transit Routing for the required 5 days and updates it’s PLNR file to denote that the number has been ported to CSP 2
Now let’s consider a three party port, carrying on from the steps above.
The Customer decides they want to move from CSP 2 to another CSP – CSP 3
At the time of the port the donor CSP (CSP 1) must:
CSP 1 must update it’s PLNR records for this number to denote it’s no longer with CSP 2 but is now with CSP 3
CSP 1 must provide Donor Transit Routing for the required 5 business days – redirecting calls to CSP 3
So even though the number is moving from CSP 2 to CSP 3 as the number was originally allocated to CSP 1, it is, and will always be the Donor Carrier and as such has to provide Donor Transit Routing and update it’s PLNR each time the number is ported.
Port Reversal / Emergency Return
Ports have an emergency return window inside which the port can be reverted. For Cat C ports this invovles the project manager of one CSP contacting the project manager for the other CSP and requesting the return.
In the event the end customer has requested the Port Reversal / Emergency return they’re typically liable for a very hefty fee to do so.
Give Back & Quarantine of Numbers
After a number is no longer required, it’s given back to the donor carrier who places it in quarantine and typically does not reallocate the number for 6 months.
In some cases such as a wronly cancelled number the customer may be able to get a number that’s been cancelled back while it’s in it’s quarantine state, however this is not required and up to the donor carrier.
Including Customer Account Numbers when Porting
Prior to 2016, a customer moving from one CSP to another CSP were required to include their account number (“Service Account Number”) they had with the Loosing CSP to the Gaining CSP when submitting the Port which was verified against the Loosing Carrier’s records to ensure the correct Customer / Service combo.
This led to a lot of ports being rejected unnecessarily due to mismatched account numbers, as such the the requirement to include a valid matching account number with the loosing CSP has been removed.
Service Account is to remain as a mandatory field, and a standard validation but any mismatches are not to be rejected.
Where’s Cat B & Cat D?
Cat B Dropped in 2013 revision due to lack of use.
Cat D is almost the same as a Cat A port but allows services with an active ULL diversion to be ported. These are quite rare and a very specific use case.
Why is my Cat C Port taking so long?
You may find after submitting a port the date you’ve got back for porting is months away. The Loosing Carrier sets the porting date, and as they’re loosing the customer, they’re often not so keen to action the port quickly when they’re loosing the customer after all.
Lead Times are determined by the Losing Carrier. These may vary by product including variations due to the size of the product or the number of sites to which a particular service is offered.
3.5.10
Tidbit: One of Australia’s largest carriers has a 20,000 number per day limit on porting, meaning they’re only able to process up to 20,000 ports per day in or out. Once that limit is reached no more ports can be accepted for that day, so the ports are delayed until the next day, etc, etc, leading to considerable lead times.
The code requires CSPs to keep Service Metrics on porting time-frames, but there’s no penalty for being slow. (Section 3.6)
Third Party ports also take a lot longer due to the requirement to find a time window that suits all 3 carriers.
Can I arrange my numbers to be Ported after-hours?
CSPs are not required to port numbers outside of the “Standard Hours” defined in the code. (Section 3.8.1 )
However, most CSPs have included support for this inside their bilateral agreements with other carriers. This typically costs more for the customer, but also comes with the added risk of if the port fails there are fewer technical / engineering resources available at the Loosing and Gaining Carrier’s respective ends to sort it out if something goes wrong.
What’s a PNO?
Porting Notification Order – A message containing either a Simple Notification Advise (SNO) for Simple (Cat A) ports, or a Complex Notification Advise (CNA) for Complex (Cat C) ports.
Each PNO contains a unique sequential reference number to differentiate / associate the PNO with a particular porting request.
PLNR – Ported Local Number Registry
PLNR is nothing more than a giant text file, containing a list of numbers originally allocated to that CSP but that have been ported to another CSP, and with each number that’s been ported out the carrier code of the CSP it’s now with.
Information to facilitate Call Routing is provided by the Donor Carrier who is required to notify Carriers, via a Ported Local Number Register, that a Port is pending, completed or did not proceed. This relates to all Ports, including Third Party Ports. All participants must use the Ported Local Number Registers to determine the correct Call Routing.
Typically transferred via Web interface:
… a web site that contains a file with a list of Telephone Numbers that have been Ported away from the Donor, or have just returned.
PLNR data is encoded as a fixed-format text file.
What is Re-targeting?
Re-Targeting is a fancy term of changing the date & time.
It’s typically more efficient to re-target a port than withdraw it and resubmit it.
For only two re-targets are allowed for each unique SNA. (Section 4.2.9)
The Australian telecommunications industry was deregulated in 1997, meaning customers could have telecommunications services through a Carriage Service Provider (CSP) of their choice.
In order to increase competition and make it easier to move to a different CSP, the ACMA (Or as they were then the ACA) declared that Local Numbers (Geo numbers / land lines) were a “Portable Service”. This meant that if a customer didn’t like their current Carriage Service Provider (CSP) they could give them the flick (making them the Loosing Carrier), move to a new CSP (Gaining Carrier) but keep their existing phone numbers by moving them to the new carrier in a process known as Local Number Portability (LNP).
The Local Number Portability (LNP) standard was first defined by Comms Alliance in 1999 in ACIF C540 and defines the process of moving numbers between Carriage Service Providers (CSPs), however 22 years later the process can still be a baffling system for many customers, end users and carrier staff to navigate.
Acronyms galore exist and often the porting teams involved themselves aren’t 100% sure what goes on in the porting process.
In 1997 ISDN was first still an emerging technology and porting was typically a customer moving from one PSTN / POTS line provided by one CSP to another PSTN / POTS line provided by a different CSP – a simple port.
Two processes were defined, one for managing simple ports involving moving one simple number from one CSP to another CSP – Called Simple Porting or “Cat A” – which made up the majority of porting requests at the time, and another process for everything else managed by a project manager from the Loosing and Gaining CSP called Complex Porting or “Cat C“.
Simple porting, classified as “Cat A” is used for porting single simple services (numbers).
The Cat A process can only be used for moving a “simple” standalone number – with no additional features – from one carrier to another.
The typical use case for Cat A port is moving a one copper PSTN / POTS line (Active line with no Fax Duet, Line Hunt, etc) from one carrier to another – as I said before, Cat A ports made up the majority of porting requests when the system was first introduced as the vast majority of services were copper POTS lines.
The process is automated at both ends, essentially the carriers send each other the numbers to be moved (more on that later) and their switches automatically process this and begin routing the number.
These ports are typically completed within a few days to a week and the customer gets a notification when the port is completed.
Cat C / Complex Number Porting
For all number porting that don’t meet the very specific requirements of Cat A aren’t met – and sometimes even if they are met, ports are processed as Cat C ports.
Cat C ports require a project manager at both the Gaining Carrier and the Losing Carrier to agree on the details for the port and the move the numbers, each using their own internal process.
Lead times on Cat C ports are long – and getting longer, so from submitting a port to it’s completion can take 90+ days, and there is no confirmation required to the customer to let them know the services have been ported successfully.
Administrative Process of Ports (CatA & CatC)
Strap yourself in for a whirlwind of acronyms…
The Code does not constrain two or more individual industry participants agreeing to different arrangements
Section 1.3.6
Because of this it means this is the minimum standard, some CSPs have improved upon this between each other, however there’s a bit of a catch 22 in that CSPs have no incentive to make porting numbers out easier, as they’re typically losing that customer, so the process is typically not improved upon in any meaningful way that makes the customer experience easier.
Without further ado, here’s what Cat A & Cat C ports look like under the hood…
Note: These all assume the Losing CSP is also the Donor CSP. More on that in the LNP FAQ and Call Routing posts.
Cat A – Simple Porting – Process
Summary
Cat A ports are automated – The process involves CSPs transferring formatted data between each other and the process that goes on for these ports.
The Losing CSP must use the Cat A process if the service meets the requirements to be ported under a Cat A and the Gaining Carrier has submitted it as a Cat A port. This means a Cat A port can’t be rejected by the losing carrier as not a valid Cat A port to be resubmitted as a Cat C port, if it does actually meet the requirements for Cat A porting. That said numbers that are valid in terms of Cat A can be submitted as a Cat C, this is often cheaper than submitting multiple Cat A porting requests when you have more than 5 or so services to be ported.
Here’s a brief summary of the process:
Customer requests port and details are validated
Simple Notification Advice (SNA) is sent to the Losing CSP via a Porting Notification Order (PNO) – Essentially a form send to the losing CSP of the intention to port the service
Losing CSP sends back SNA Confirmation Advice to confirm the service can be ported
Electronic Cutover Advice (ECA) sent by gaining CSP to indicate gaining CSP wanting to initiate port
Losing CSP provides Donor Routing by essentially redirecting calls to the Gaining CSP
ECA Confirmation Advice sent by losing CSP to denote the service has been removed from the losing CSP’s network & number is with gaining CSP as far as they are concerned
Losing CSP updates a big text file (PLNR) with a list of numbers allocated to it, to show the numbers have been ported to a different carrier and indicates which carrier
We’ll talk about the technical process of how the data is transferred, what PLNR is and how routing is managed, later on.
In depth process:
Step 1 – Customer Authority
The Gaining CSP must obtain Customer’s Authority (CA) to port number (Section 4.1.2) – Typically this takes the form of a number porting form filled in by the customer, containing a list of numbers to port, account numbers with losing carrier and date.
If requested by the customer the Losing CSP must explain any costs / termination payments / contractual obligations to the customer (Section 4.1.4), however the Losing CSP cannot reject the port based upon an outstanding contract being in place.
Step 2 – Validation
Before anything technical happens, the Gaining CSP must validate the porting request is valid – this means verifying:
The requested numbers are able to be ported under the selected method (Cat A or Cat C)
Confirming the date of the Customer Authority is less than 90 days old
The requested numbers must be recorded
In practice these 3 steps are typically handled by a single form filled out by the customer in the first step. (Section 4.1.5)
If requested by the Losing CSP this Customer Authority information has to be given to the Losing CSP. This typically happens in cases of disputed ownership / management of a number.
Step 3 – The SNA PNO
Once the Gaining CSP is satisfied the port is valid, a Simple Notification Advice (SNA) is sent to the Losing CSP via a Porting Notification Order (PNO) (Section 4.2.2).
The PNO is essentially a form that includes:
Area Code & Telephone Number of service to be ported
Service Account number with Losing CSP
Porting Category set to Cat A
Date of Customer Authority
The Losing CSP must then validate this info, by checking: (Section 4.2.4)
The requested number is a Simple service (Meets the requirements of Cat A)
Is with the Losing CSP (Has not been ported to another carrier already)
Is not disconnected or pending disconnection at the time the SNA was submitted
The Customer Authority (CA) date is not more than 90 days old
Does not currently have a port request pending
After the Losing CSP has gone through this they will send back a SNA Confirmation Advice if the port request (SNA PNO) is valid or a SNA Reject Advice along with the phone number and reason for rejection if the port request is deemed invalid.
The confirmation, if SNA Confirmation Advice is received, is deemed valid for 30 days, after which the process would have to start again and the SNA PNO would have to be regenerated.
Step 4 – Electronic Cutover Advice (ECA)
After the Losing CSP sends back a SNA Confirmation Advice, the gaining carrier sends the Losing Carrier an Electronic Cutover Advice (ECA) via the Final Cutover Notification Interface (Section 4.2.24 ).
When the Losing CSP get the ECA it’s showtime. The Losing CSP checks that there’s a valid SNAin place for the number to be ported and that it’s less than 2 days old (Section 4.2.27).
If the Losing CSP is not satisfied they send back a ECA Reject Advice listing the reason for rejection within 15 minutes (Section 4.2.32).
If all looks good, the Losing Carrier sends the Gaining CSP back a ECA Confirmation Advice within 15 minutes (Section 4.2.33).
Now is when the magic happens – the Losing CSP “ports out” that number via their internal process, for this they provide temporary Donor Transit Routing – Essentially redirecting any calls that come into the ported number to the new carrier.
Finally the Losing CSP sends a Electronic Completion Advice (ECA) to confirm they’ve processed the port out from their network (Section 4.2.34).
Within a day of the port completing, the Losing CSP updates the Ported Local Number Registry (PLNR) to show the service has been ported out and the identifier of the gaining carrier the number has been ported to. PLNR is nothing more than a giant text file containing a list of all the numbers originally allocated to the Losing CSP and the carrier code they should now be routing to, this data is published so the other CSPs can read it.
Other CSPs read this PLNR data and update their routing tables, meaning the calls will route directly to the new Gaining CSP, and the Donor Routing can be removed on the Losing CSPs switch.
Cat C – Complex Porting – Process
Summary
Cat C ports are a manually project managed, and unlike Cat A are not automated.
This means that the Losing and Gaining CSP must both allocate a “project manager”, the two to liaise with each other (typically via email) to confirm the numbers can be ported and then find a suitable time to port the numbers, finally at the agreed upon date & time each side kicks off their own process to move the numbers and confirm when it’s done.
Porting Number Validation – PNV
Before a Cat C port can be initiated the PNV process is typically called upon to validate the port won’t get rejected. This isn’t mandatory but is often used as PNV is processed relatively quickly which means any issues with the services can be worked out prior to submitting the port request.
The submitted PNV request is very similar to the actual Cat C porting request (CNA), containing the customer’s details and list of services to be ported.
The losing CSP returns the list of numbers each with a response code denoting particulars of the service, and if rejected, a rejection code.
Response Codes:
Reason Code
Reason
P
Prime/Directory Service Number
A
Associated Service Numbers
S
Standalone Number
R
Reserved Number
D
Exchange based diversion
SS
Secondary Service linked to this Number (e.g. DSL)
Reject Codes:
Code
Reason
1
Invalid Customer Authorization date
Whole Request
2
Insufficient information supplied
Whole Request
3
Telephone Number appears to belong to a completely different end customer
Per Number
4
Telephone Numbers relate to cancelled services or services pending cancellation
Per Number
5
Missing / invalid PNV Sequence Number
Per Number
6
Telephone Numbers in the PNV request relate to services which are billed by a service provider other than the Losing Carrier.
Per Number
7
Telephone Numbers are not found / not present on Losing Carrier’s Network
Per Number
(Section 4.3.8)
It’s worth noting the main reason PNV is used so heavily in Cat C ports is if a batch of numbers / services are requested to be ported in a single Cat C porting request, if any one of those numbers gets rejected the whole port will need to be resubmitted, hence it being important that before submitting the numbers to be ported, the Gaining CSP verifies they can be ported via the PNV process.
The PNV does not guarantee a physical audit of the services, but rather an audit of available electronic data by the losing CSP. It’s also only valid for the day of issue, so services can change between a PNV coming back clear and the port request being rejected.
99% of PNV requests should be processed within 5 business days. (Section 4.3.9)
Step 1 – Complex Notification Advice (CNA)
To initiate the port the gaining CSP submits a Complex Notification Advice(CNA) to the losing CSP.
This contains all the data you’d expect, including customer’s details and the list of services/numbers to be ported, along with a batch number that’s unique to the Gaining CSP (Like a ticket / request number) and Gaining CSP’s Project Manager – The staff member as the Gaining CSP that will be responsible for the port.
Upon receipt, the Losing CSP sends back a CNA Receipt Advice to confirm they’ve received and begins validating the CNA in a process very similar to the PNV process. (Section 4.4.1)
Step 2 – CNA Confirmation Advice
If verification fails and the CNA request is deemed not valid the CNA is rejected by the Losing CSP, who sends back a CNA Reject Advice response. This response will contain a list of services and the reject code for each rejected service as per the PNV process.
If the CNA is deemed valid, the Losing CSP responds with a CNA Confirmation Advice message, containing the Losing CSP’s project manager for this port, along with the Gaining CSP’s batch number to the Gaining CSP.
This is sent in a batch file along with other CNA Confirmation Advice messages within 5 days. (Section 4.4.6)
Step 3 – Complex Cutover Advice (CCA)
Once the Gaining CSP has the CNA Confirmation Advice the project manager for the port at the Gaining CSP contacts the nominated project manager at the Losing CSP and the two have to agree on a cutover date and time for the port. (Section 4.4.8)
The agreed date and time of the port is sent by the Gaining CSP to the Losing CSP in the from of a Complex Cutover Advice (CCA) containing the Gaining CSP batch number and agreed date & time. (Section 4.4.27)
If the details of the CCA are valid from the Losing CSP’s perspective, the Losing CSP sends back CCA Confirmation Advice to confirm receipt.
Step 4 – The Porting
At the agreed upon date & time both CSPs are to execute the port from their organization’s perspective.
Typically the losing CSP provides Donor Transit Routing forwarding / redirecting calls to the ported out number to the new CSP.
There is no completion advice and no verification the port has been completed successfully required by the code. (Section 4.4.48)
Within a day of the port completing, the Losing CSP updates the Ported Local Number Registry (PLNR).
Other CSPs read this PLNR data and update their routing tables, meaning the calls will route directly to the new Gaining CSP, and the Donor Routing can be removed on the Losing CSPs switch.
In order to keep radio resources free, if a UE doesn’t send or receive data for a predefined threshold, it’ll detach from the network and call back to Idle mode.
If the UE has data to send to the network, the UE will re-attach to the network, whereas if the network has data to send to the UE, it’ll Page the UE in the tracking area it’s currently in, the UE is always listening for it’s identifier (s-TMSI) on the paging channel, and if it hears it’s identifier called, the UE will re-attach.
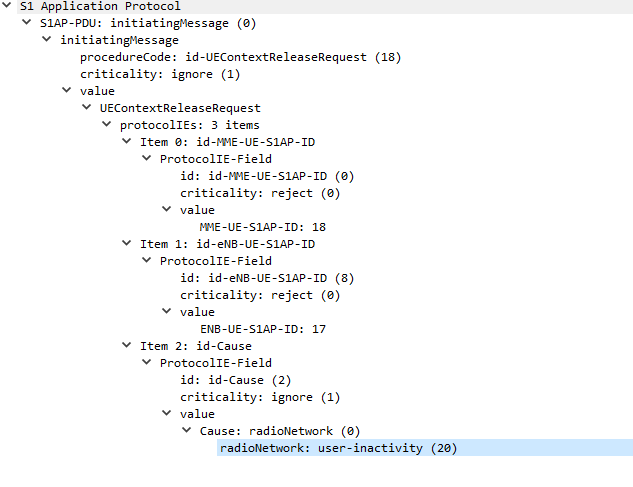
I’ve also attached a PCAP file of the packet flow between the eNB and the MME.
The next packet is sent from the MME back to the eNB confirming UE is releasing from the network.
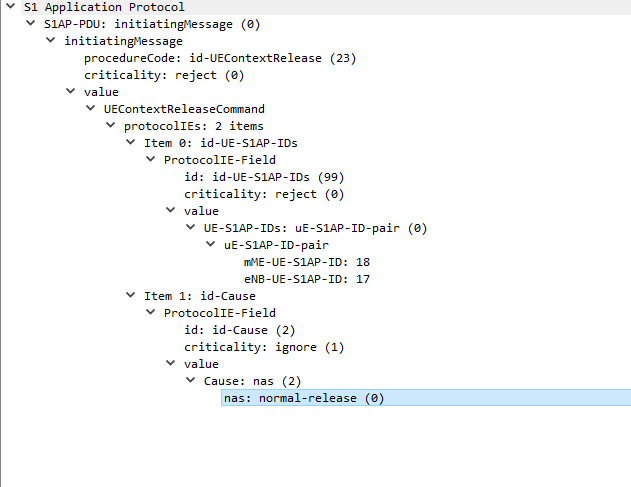
UEContextReleaseCommand
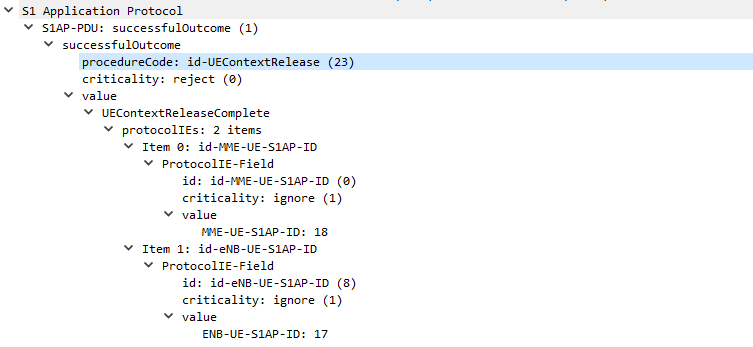
UEContextReleaseComplete
Finally after the UE has released it’s radio resources the eNB sends a UEContextReleaseComplete so the MME knows the UE is now in Idle state and will need to be paged.
Recently we saw Open5Gs’s Update Location Answer response putting the Subscribed-Periodic-RAU-TAU-Timer AVP in the top level and not in the AVP Code 1400 (APN Configuration) Diameter payload from the HSS to the MME.
But what exactly does the Subscribed-Periodic-RAU-TAU-Timer AVP in the Update Location Answer response do?
Folks familiar with EUTRAN might recognise TAU as Tracking Area Update, while RAU is Routing Area Update in GERAN/UTRAN (UMTS).
Periodic tracking area updating is used to periodically notify the availability of the UE to the network. The procedure is controlled in the UE by the periodic tracking area update timer (timer T3412). The value of timer T3412 is sent by the network to the UE in the ATTACH ACCEPT message and can be sent in the TRACKING AREA UPDATE ACCEPT message. The UE shall apply this value in all tracking areas of the list of tracking areas assigned to the UE, until a new value is received.
Section 5.3.5 of 24301-9b0 (3GPP TS 24.301 V9.11.0)
So the Periodic Tracking Area Update timer simply defines how often the UE should send a Tracking Area Update when stationary (not moving between cells / tracking area lists).
On a PCM (G.711) RTP packet the payload is typically 160 bytes per packet.
But the total size of the frame on the wire is typically ~214 bytes, to carry a 160 byte payload that means 25% of the data being carried is headers.
This is fine for VoIP services operating over fixed lines, but when we’re talking about VoLTE / IMS and the traffic is being transferred over Radio Access Networks with limited bandwidth / resources, it’s important to minimize this as much as possible.
IMS uses the AMR codec, where the RTP payload for each packet is around 90 bytes, meaning up to two thirds of the packet on the wire (Or in this case the air / Uu interface) is headers.
Using ROHC the size of the headers are cut down to only 4-5 bytes, this is because the IPv4 headers, UDP headers and RTP headers are typically the same in each packet – with only the RTP Sequence number, RTP timestamp IPv4 & UDP checksum and changing between frames.
I modified the Kamailio config allow Transcoding, as I talked about in the post on setting up Transcoding in RTPengine with Kamailio.
Now I had a working Kamailio instance with RTPengine that was transcoding.
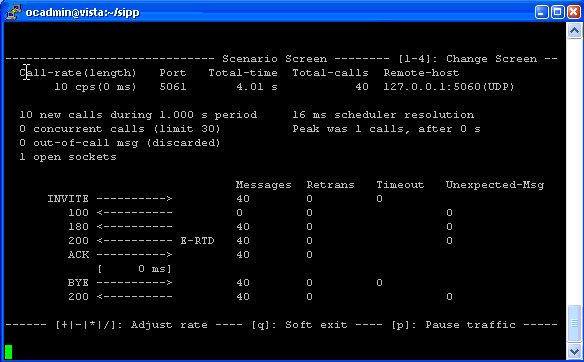
So the next step becomes testing the transcoding is working, for this I had two SIPp instances, one to make the calls and once to answer them.
Instance 1
Makes calls to the IP of the Kamailio / RTPengine instance, for this I modified the uac_pcap scenario to playback an RTP stream of a PCMA (G.711 a-law) call to the called party (stored in a pcap file), and made it call the Kamailio instance multiple times based on how many concurrent transcoding sessions I wanted:
Note: NextEPC the Open Source project rebranded as Open5Gs in 2019 due to a naming issue. The remaining software called NextEPC is a branch of an old version of Open5Gs. This post was written before the rebranding.
I’ve been working for some time on Private LTE networks, the packet core I’m using is NextEPC, it’s well written, flexible and well supported.
I joined the Open5Gs group and I’ve contributed a few bits and pieces to the project, including a Python wrapper for adding / managing subscribers in the built in Home Subscriber Server (HSS).
Basic Python library to interface with MongoDB subscriber DB in NextEPC HSS / PCRF. Requires Python 3+, mongo, pymongo and bson. (All available through PIP)
If you are planning to run this on a different machine other than localhost (the machine hosting the MongoDB service) you will need to enable remote access to MongoDB by binding it’s IP to 0.0.0.0:
This is done by editing /etc/mongodb.conf and changing the bind IP to: bind_ip = 0.0.0.0
Starting from today, Australia’s largest carrier will begin disconnecting ISDN services, and all will be shut off entirely by 2022.
When I started working in the industry the question wasn’t how many SIP Channels you wanted, but rather PRI or BRI when it came to trunk lines.
We’d use ISDN dial up to remotely administer systems, and had a bulky ISDN PRI test set for testing lines and BERT.
ISDN Crossovers, QSIG, gateways, ISUP, Bit Error Rate Testing, loopbacks, clock slips, cause code 16, enblock dialing – all things I’m not likely to need to know anymore.
Since ISDN was first rolled out in Australia just over 3 decades ago, to it being switched off from today onward, ISDN has been crazily reliable, and as much as it pains me to admit it, it has availability stats any SIP provider would be envious of.
As the market evolved over the years the smaller telcos realized using ISDN-SIP gateways made by AudioCodes, Epigy, Sangoma & Quintum was a cheap way to provide a drop in replacement for those expensive Telstra/Optus ISDN services. This generally was a stop gap measure as companies then made the move to straight SIP and stopped paying for the gateway device each month.
And just like that, ISDN was no longer relevant.
So today SIP based VoIP is the clear standard, ISDN fades away, but strangely those POTS lines carry on. Sure they are just VoIP delivered over a carrier grade ATA, but that 48vDC loop of copper with AC ring current, standardized over 120 years ago somehow lives on…
Here’s an article from The Age dated 11 August 1989:
Number may be up for the Telephone
Alexander Graham Bell’s system of sending voices over wires with a varying electrical current started a revolution, then weathered it for 123 years.
In Australia, that unchallenged reign officially ended yesterday with the official beginning of another revolution called integrated services digital networking — ISDN. The telephone has married the computer and gone digital.
The revolution really began late last year when Telecom invited several big companies to try out the communications system that will soon extend its tendrils into our offices and eventually, our homes.
In Canberra’s new National Convention Centre yesterday, the Minister for Telecommunications and Aviation Support, Mrs Kelly, communicated simultaneously via voice, fax and photovideotex on a single telephone line with two senior officers of the Defence Department in an office on the other side of Canberra.
Mr Bell’s telephone could never do that — it does only one job at a time.
With ISDN, any device that speaks or responds to the simple on-off language of computer digital code, or anything that can be rendered in the same code, including the human voice, video images and computer images, can be sent simultaneously on a single ISDN connection.
Each type of information is coded and -addressed in such a way that, at the other end, fax messages go to faxes, voices come out of the telephone and computer images arrive onscreen or on a printer.
The system inaugurated by Mrs Kelly is called ISDN Macro-link. It allows large companies with high-volume communications needs to design their own communications networks by selecting from a range of services available through the network, and plugging in the devices they need to do their business.
Like Lego, ISDN can be configured in myriad ways. It permits permanent, high-volume links to be established between offices in widely separated locations so that big computers can talk to each other.
Charges for all ISDN use are based on the amount of information sent.
The blazingly fast G4 fax can transmit a full A4 page in a few seconds, and the image emerges perfect and with the tiniest detail still visible, as if fresh from a laser printer.
The same link allows an executive in Melbourne to call a colleague in Sydney as easily as dialing an extension in the same building.
One can sketch a diagram on his computer terminal, and it will appear at the other end as it is being drawn.
Photographs can be digitized on a scanner and sent to a computer or printer as they speak, and if they wish, the colleagues can even see each other’s faces on slow scan video.
ISDN’s availability will lead to a change in the design of items like telephones, personal computers, printers and faxes — already companies are making devices that integrate all four.
As Australian and overseas networks develop, and ISDN communication between continents increases, the global village will shrink even further.
Number may be up for the telephone – Grahame O’Neill, Science and Technology Reporter ‘The AGE’ Melbourne Australia – Friday 11 August 1989
Note: NextEPC the Open Source project rebranded as Open5Gs in 2019 due to a naming issue. The remaining software called NextEPC is a branch of an old version of Open5Gs. This post was written before the rebranding.
In a production network network elements would typically not all be on the same machine, as is the default example that ships with NextEPC.
NextEPC is designed to be standards compliant, so in theory you can connect any core network element (MME, PGW, SGW, PCRF, HSS) from NextEPC or any other vendor to form a functioning network, so long as they are 3GPP compliant.
To demonstrate this we will cover isolating each network element onto it’s on machine and connect each network element to the other. For some interfaces specifying multiple interfaces is supported to allow connection to multiple
In these examples we’ll be connecting NextEPC elements together, but it could just as easily be EPC elements from a different vendor in the place of any NextEPC network element.
Service
IP
Identity
P-GW
10.0.1.121
pgw.localdomain
S-GW
10.0.1.122
PCRF
10.0.1.123
pcrf.localdomain
MME
10.0.1.124
mme.localdomain
HSS
10.0.1.118
hss.localdomain
External P-GW
In it’s simplest from the P-GW has 3 interfaces:
S5 – Connection to home network S-GW (GTP-C)
Gx – Connection to PCRF (Diameter)
Sgi – Connection to external network (Generally the Internet via standard TCP/IP)
S5 Interface Configuration
Edit /etc/nextepc/pgw.confand change the address to IP of the server running the P-GW for the listener on GTP-C and GTP-U interfaces.
If you are using NextEPC’s HSS you may need to enable MongoDB access from the PCRF. This is done by editing ‘‘/etc/mongodb.conf’’ and changing the bind IP to: bind_ip = 0.0.0.0
Restart MongoDB for changes to take effect.
$ /etc/init.d/mongodb restart
External MME
In it’s simplest form the MME has 3 interfaces:
S1AP – Connections from eNodeBs
S6a – Connection to HSS (Diameter)
S11 – Connection to S-GW (GTP-C)
S11 Interface Configuration
Edit /etc/nextepc/mme.conf, filling the IP address of the S-GW and P-GW servers.
We’ve talked about using a few different modules, like a SIP Registrar and Htable, that rely on data stored in Kamailio’s memory, the same is true for all the Stateful proxy discussion last week.
But what if you want to share this data between multiple Kamailio instances? This allows distributing workload and every server having the same information and therefore any server is able to process any request.
This allows memory data to be shared between multiple Kamailio instances (aka “Nodes”), so for example if you are storing data in Htable on one Kamailio box, all the other boxes/nodes in the DMQ pool will have the same HTable data.
Kamailio uses SIP to transfer DMQ messages between DMQ nodes, and DNS to discover DMQ nodes.
For this example we’ll share user location data (usrloc) between Kamailio instances, so we’ll create a very simple setup to store location data:
####### Routing Logic ########
/* Main SIP request routing logic
* - processing of any incoming SIP request starts with this route
* - note: this is the same as route { ... } */
request_route {
#Enable record_routing so we see the BYE / Re-INVITE etc
if(is_method("REGISTER")){
save("location");
}else{
sl_reply("500", "Nope");
}
}
Now if we register a SIP endpoint we should be able to view it using Kamcmd’s ul.dump call, as we talked about in the Kamailio SIP Registrar tutorial.
Next we’ll setup DMQ to allow this data to be shared to other nodes, so they also have the same userloc data available,
First we’ll begin by binding to an extra port for the DMQ messages to go to, to make it a bit clearer what is normal SIP and what’s DMQ,
So for this we’ll add a new line in the config to listen on port 5090:
/* uncomment and configure the following line if you want Kamailio to
* bind on a specific interface/port/proto (default bind on all available) */
listen=udp:0.0.0.0:5060
listen=tcp:0.0.0.0:5060
listen=udp:0.0.0.0:5090
The server_address means we’re listening on any IP on port 5090. In production you may have an IP set here of a private NIC or something non public facing.
The notification address resolves to 2x A records, one is the IP of this Kamailio instance / node, the other is the IP of the other Kamailio instance / node, I’ve just done this in /etc/hosts
Finally we’ll add some routing logic to handle the DMQ messages coming in on port 5090:
####### Routing Logic ########
/* Main SIP request routing logic
* - processing of any incoming SIP request starts with this route
* - note: this is the same as route { ... } */
request_route {
if (is_method("KDMQ") && $Rp == 5090)
{
dmq_handle_message();
}
#Enable record_routing so we see the BYE / Re-INVITE etc
if(is_method("REGISTER")){
save("location");
}else{
sl_reply("500", "Nope");
}
}
We’ll put the same config on the other Kamailio instance and restart Kamailio on both.
We can now check the DMQ node status to confirm they’re talking to each other.
We talked a little about the Transaction module and using it for Transaction Stateful SIP Proxy, but it’s worth knowing a bit more about the Transaction Module and the powerful functions it offers.
So today I’ll cover some cool functionality TM offers!
Different Reply Routes
By calling the t_on_reply(); we can specify the reply route to be used for replies in this transaction.
route[RELAY]{
#Use reply route "OurReplyRoute" for responses for this transaction
t_on_reply("OurReplyRoute");
#Relay (aka Forward) the request
t_relay_to_udp("192.168.3.118", "5060");
}
onreply_route[OurReplyRoute] {
#On replies from route[RELAY]
#Check our AVP we set in the initial request
xlog("for $rs response the value of AVP \"state_test_var\" is $avp(state_test_var) ");
#Append a header so we can see this was proxied in the SIP capture
append_hf("X-Proxied: For the reply\r\n");
}
Any responses from the route[RELAY] routing block will go to onreply_route[OurReplyRoute], the beauty of this is it allows you to have multiple reply routes each with their own logic. For example for a call leg to a carrier you may want to preserve CLI, but for a call leg to a customer you may wish to restrict it if that’s the option the user has selected, and you can make these changes / modifications in the reply messages.
Failure Routes
Failure routes allow the transaction module to know to try again if a call fails, for example if no response is received from the destination, send it to a different destination, like a backup.
route[RELAY]{
#Use reply route "OurReplyRoute" for responses for this transaction
t_on_reply("OurReplyRoute");
t_on_failure("OurFailureRoute");
#Relay (aka Forward) the request
t_relay_to_udp("192.168.1.118", "5060");
}
failure_route[OurFailureRoute]{
xlog("At failure route");
t_reply("500", "Remote end never got back to us");
exit;
}
We can build upon this, and try a different destination if the first one fails:
request_route {
#Enable record_routing so we see the BYE / Re-INVITE etc
record_route();
#Handle Registrations in a dumb way so they don't messy our tests
if(is_method("REGISTER")){
sl_reply("200", "ok");
exit;
}
#Append a header so we can see this was proxied in the SIP capture
append_hf("X-Proxied: You betcha\r\n");
if(is_method("INVITE")){
#Createa new AVP called "state_test_var" and set the value to "I remember"
$avp(state_test_var) = "I remember";
}
#Let syslog know we've set the value and check it
xlog("for $rm the value of AVP \"state_test_var\" is $avp(state_test_var) ");
#Send to route[RELAY] routing block
rewritehostport("nonexistentdomain.com");
route(RELAY);
}
route[RELAY]{
#Use reply route "OurReplyRoute" for responses for this transaction
t_on_reply("OurReplyRoute");
t_on_failure("OurFailureRoute");
#Relay (aka Forward) the request
t_relay();
}
failure_route[OurFailureRoute]{
xlog("At failure route");
#t_reply("500", "Remote end never got back to us");
rewritehostport("192.168.3.118");
append_branch();
t_relay();
}
onreply_route[OurReplyRoute] {
#On replies from route[RELAY]
#Check our AVP we set in the initial request
xlog("for $rs response the value of AVP \"state_test_var\" is $avp(state_test_var) ");
#Append a header so we can see this was proxied in the SIP capture
append_hf("X-Proxied: For the reply\r\n");
}
One thing to keep in mind is that there’s lots of definitions of failure, for example if you are sending a call to a carrier and get a 404 response back, you probably want to relay that through to the end user, because that destination isn’t there.
But if you get back a 5xx series response you may consider that to be a failure and select the next carrier for example.
Different conditions / requirements have different definitions of “failures” and so there’s a lot to think about when implementing this, along with timeouts for no replies, TCP session management, etc.
Parallel Forking the Call to Multiple Destinations
Parallel Forking is a fancy way of saying ring multiple destinations at the same time.
/* Main SIP request routing logic
* - processing of any incoming SIP request starts with this route
* - note: this is the same as route { ... } */
request_route {
#Enable record_routing so we see the BYE / Re-INVITE etc
record_route();
#Handle Registrations in a dumb way so they don't messy our tests
if(is_method("REGISTER")){
sl_reply("200", "ok");
exit;
}
#Append a header so we can see this was proxied in the SIP capture
append_hf("X-Proxied: You betcha\r\n");
if(is_method("INVITE")){
#Createa new AVP called "state_test_var" and set the value to "I remember"
$avp(state_test_var) = "I remember";
}
#Let syslog know we've set the value and check it
xlog("for $rm the value of AVP \"state_test_var\" is $avp(state_test_var) ");
#Send to route[RELAY] routing block
route(RELAY);
}
route[RELAY]{
#Use reply route "OurReplyRoute" for responses for this transaction
t_on_reply("OurReplyRoute");
#Append branches for each destination we want to forward to
append_branch("sip:[email protected]");
append_branch("sip:[email protected]");
append_branch("sip:[email protected]");
t_on_failure("OurFailureRoute");
#Relay (aka Forward) the request
t_relay();
}
failure_route[OurFailureRoute]{
xlog("At failure route");
t_reply("500", "All those destinations failed us");
}
onreply_route[OurReplyRoute] {
#On replies from route[RELAY]
#Check our AVP we set in the initial request
xlog("for $rs response the value of AVP \"state_test_var\" is $avp(state_test_var) ");
#Append a header so we can see this was proxied in the SIP capture
append_hf("X-Proxied: For the reply\r\n");
}
Bit of a mess but here we see the initial INVITE being branched to the 3 destinations at the same time (Parallel forking)
Serial Forking / Sequential Forking the calls to Multiple Destinations one after the Other
This could be used to try a series of weighted destinations and only try the next if the preceding one fails:
/* Main SIP request routing logic
* - processing of any incoming SIP request starts with this route
* - note: this is the same as route { ... } */
request_route {
#Enable record_routing so we see the BYE / Re-INVITE etc
record_route();
#Send to route[RELAY] routing block
route(RELAY);
}
route[RELAY]{
#Use reply route "OurReplyRoute" for responses for this transaction
t_on_reply("OurReplyRoute");
append_branch("sip:[email protected]", "0.3");
append_branch("sip:[email protected]", "0.2");
append_branch("sip:[email protected]", "0.1");
t_load_contacts();
t_next_contacts();
t_on_failure("OurFailureRoute");
#Relay (aka Forward) the request
t_relay();
break;
}
failure_route[OurFailureRoute]{
xlog("At failure route - Trying next destination");
t_on_failure("OurFailureRoute");
t_relay();
}
onreply_route[OurReplyRoute] {
#On replies from route[RELAY]
#Append a header so we can see this was proxied in the SIP capture
append_hf("X-Proxied: For the reply\r\n");
}
Again this will try each destination, but one after the other based on the weight we added to each destination in the append_branch()
Here we see each destination being tried sequentially
The 3 different proxies all do the same thing, they all relay SIP messages, so we need a way to determine what state has been saved.
To do this we’ll create a variable (actually an AVP) in the initial request (in our example it’ll be an INVITE), and we’ll reference it when handling a response to make sure we’ve got transactional state.
We’ll also try and reference it in the BYE message, which will fail, as we’re only creating a Transaction Stateful proxy, and the BYE isn’t part of the transaction, but in order to see the BYE we’ll need to enable Record Routing.
Stateless Proof
Before we add any state, let’s create a working stateless proxy, and add see how it doesn’t remember:
####### Routing Logic ########
/* Main SIP request routing logic
* - processing of any incoming SIP request starts with this route
* - note: this is the same as route { ... } */
request_route {
#Enable record_routing so we see the BYE / Re-INVITE etc
record_route();
#Handle Registrations in a dumb way so they don't messy our tests
if(is_method("REGISTER")){
sl_reply("200", "ok");
exit;
}
#Append a header so we can see this was proxied in the SIP capture
append_hf("X-Proxied: You betcha\r\n");
if(is_method("INVITE")){
#Createa new AVP called "state_test_var" and set the value to "I remember"
$avp(state_test_var) = "I remember";
}
#Let syslog know we've set the value and check it
xlog("for $rm the value of AVP \"state_test_var\" is $avp(state_test_var) ");
#Forard to new IP
forward("192.168.3.118");
}
onreply_route{
#Check our AVP we set in the initial request
xlog("for $rs response the value of AVP \"state_test_var\" is $avp(state_test_var) ");
#Append a header so we can see this was proxied in the SIP capture
append_hf("X-Proxied: For the reply\r\n");
}
Now when we run this and call from any phone other than 192.168.3.118, the SIP INVITE will hit the Proxy, and be forwarded to 192.168.3.118.
Syslog will show the INVITE and us setting the var, but for the replies, the value of AVP $avp(state_test_var) won’t be set, as it’s stateless.
Let’s take a look:
kamailio[2577]: {1 1 INVITE [email protected]} ERROR: : for INVITE the value of AVP "state_test_var" is I remember
kamailio[2575]: {2 1 INVITE [email protected]} ERROR: <script>: for 100 response the value of AVP "state_test_var" is <null>
kamailio[2576]: {2 1 INVITE [email protected]} ERROR: <script>: for 180 response the value of AVP "state_test_var" is <null>
kamailio[2579]: {2 1 INVITE [email protected]} ERROR: <script>: for 200 response the value of AVP "state_test_var" is <null>
kamailio[2580]: {1 1 ACK [email protected]} ERROR: <script>: for ACK the value of AVP "state_test_var" is <null>
kamailio[2581]: {1 2 BYE [email protected]} ERROR: <script>: for BYE the value of AVP "state_test_var" is <null>
We can see after the initial INVITE none of the subsequent replies knew the value of our $avp(state_test_var), so we know the proxy is at this stage – Stateless.
Doing the heavy lifting of our state management is the Transaction Module (aka TM). The Transaction Module deserves a post of it’s own (and it’ll get one).
We’ll load the TM module (loadmodule “tm.so”) and use thet_relay() function instead of the forward() function.
But we’ll need to do a bit of setup around this, we’ll need to create a new route block to call t_relay() from (It’s finicky as to where it can be called from), and we’ll need to create a new reply_route{} to manage the response for this particular dialog.
Let’s take a look at the code:
####### Routing Logic ########
/* Main SIP request routing logic
* - processing of any incoming SIP request starts with this route
* - note: this is the same as route { ... } */
request_route {
#Enable record_routing so we see the BYE / Re-INVITE etc
record_route();
#Handle Registrations in a dumb way so they don't messy our tests
if(is_method("REGISTER")){
sl_reply("200", "ok");
exit;
}
#Append a header so we can see this was proxied in the SIP capture
append_hf("X-Proxied: You betcha\r\n");
if(is_method("INVITE")){
#Createa new AVP called "state_test_var" and set the value to "I remember"
$avp(state_test_var) = "I remember";
}
#Let syslog know we've set the value and check it
xlog("for $rm the value of AVP \"state_test_var\" is $avp(state_test_var) ");
#Send to route[RELAY] routing block
route(RELAY);
}
route[RELAY]{
#Use reply route "OurReplyRoute" for responses for this transaction
t_on_reply("OurReplyRoute");
#Relay (aka Forward) the request
t_relay_to_udp("192.168.3.118", "5060");
}
onreply_route[OurReplyRoute] {
#On replies from route[RELAY]
#Check our AVP we set in the initial request
xlog("for $rs response the value of AVP \"state_test_var\" is $avp(state_test_var) ");
#Append a header so we can see this was proxied in the SIP capture
append_hf("X-Proxied: For the reply\r\n");
}
So unlike before where we just called forward(); to forward the traffic we’re now calling in a routing block called RELAY.
Inside route[RELAY] we set the routing block that will be used to manage replies for this particular transaction, and then call t_relay_to_udp() to relay the request.
We renamed our onreply_route to onreply_route[OurReplyRoute], as specified in the route[RELAY].
So now let’s make a call (INVITE) and see how it looks in the log:
kamailio[5008]: {1 1 INVITE [email protected]} ERROR: : for INVITE the value of AVP "state_test_var" is I remember
kamailio[5005]: {2 1 INVITE [email protected]} ERROR: <script>: for 100 response the value of AVP "state_test_var" is I remember
kamailio[5009]: {2 1 INVITE [email protected]} ERROR: <script>: for 180 response the value of AVP "state_test_var" is I remember
kamailio[5011]: {2 1 INVITE [email protected]} ERROR: <script>: for 200 response the value of AVP "state_test_var" is I remember
kamailio[5010]: {1 1 ACK [email protected]} ERROR: <script>: for ACK the value of AVP "state_test_var" is <null>
kamailio[5004]: {1 2 BYE [email protected]} ERROR: <script>: for BYE the value of AVP "state_test_var" is <null>
kamailio[5007]: {2 2 BYE [email protected]} ERROR: <script>: for 200 response the value of AVP "state_test_var" is <null>
Here we can see for the INVITE, the 100 TRYING, 180 RINGING and 200 OK responses, state was maintained as the variable we set in the INVITE we were able to reference again.
(The subsequent BYE didn’t get state maintained because it’s not part of the transaction.)
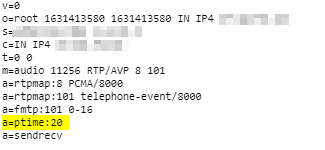
ptime is the packetization timer in VoIP, it’s set in the SDP message and defines the length of each RTP packet that’s sent;
This gives the length of time in milliseconds represented by the media in a packet. This is probably only meaningful for audio data, but may be used with other media types if it makes sense. It should not be necessary to know ptime to decode RTP or vat audio, and it is intended as a recommendation for the encoding/packetisation of audio. It is a media-level attribute, and it is not dependent on charset.
A lower ptime value leads to more packet per second, while longer ptime leads to fewer packets per second.
In a Toll Quality (TDM) network 8000 samples per second are taken, this is reflected in PCM (Pulse Code Modulation) encoding of the data, see in PCMA / G.711 a-law for example.
But if each of these 8,000 samples per second were sent on an individual packet, we’d be seeing a huge number of tiny RTP packets where the header is a lot larger than the payload.
Instead endpoints generally wait until they’ve got a certain number of theses samples and then send them at once, every X milliseconds as defined by the ptime value.
A ptime of 1000ms would mean 1 packet per second.
A ptime of 20ms would mean 50 packets per second.
A ptime of 50ms would mean 20 packets per second.
ptime headaches
Some VoIP endpoints have issues with varied ptime (*cough Cisco SPA series cough*), and if you’re interconnecting with other carrier networks you have no real control as to what ptime endpoints use (except if you have a B2Bua that can resample / restuff the packets, or you use maxptime which really just limits more than fixes) so it’s worth understanding well.
International carrier trunks often have higher ptime values as they're often dealing with lower quality links, so they want to cut down the packets per second and often have jitter buffers in place to compensate for poor quality links.
RFC4566 (the second version of SDP) introduced the maxptime value.
This optional header in the SDP body allows an endpoint to specify the maximum ptime value it supports.
Older endpoints often don’t have much memory or processing power, so have very small buffers to store the received audio in before playing it to the user, and store the audio to be transmitted before sending it down the wire.
Mismatched ptime or a ptime that’s out of bounds for one endpoint can lead to some strange issues. Often an endpoint will ring, answer the call and even get a 200 OK, but immediately followed by a BYE from the incompatible end instead of an ACK.
In the initial INVITE ptime is not mandatory, meaning you may not know the caller has limits to the ptime values they can support, and the endpoint hangs up the calls straight after the 200 OK.
Identifying these issues may take some time, but here’s some good places to look:
SDP ptime value on INVITE and 200 OK
Time between RTP packets
Timestamp difference between RTP packets
Although it seems pretty self evident, if your endpoint only supports up to 20ms ptime, set the maxptime header to 20ms. You’d be surprised how often this isn’t the case.
One of the most searched keywords that leads to this site is Kamailio vs Asterisk, so I thought I’d expand upon this a bit more as I’m a big fan of both, and it’s somewhat confusing.
(Almost everything in this post I talk about on Asterisk is roughly true for FreeSWITCH as well, although FS is generally more stable and scalable than Asterisk. )
Asterisk
Asterisk is a collection of PBX / softswitch components that you can configure and put together to create a large number of different products with the use of config files and modules.
Asterisk can read and write the RTP media stream, allowing it to offer services like Voicemail, B2B-UA, Conferencing, Playing back audio, call recording, etc.
It’s easy to learn and clear to understand how it handles “calls”.
Kamailio
Kamailio is a SIP proxy, from which you can modify SIP headers and then forward them on or process them and generate a response.
Kamailio is unable to do manipulate the RTP media stream. It can’t listen to, modify or add to the call audio, it only cares about SIP and not the media stream. This means it can’t playback an audio file, record a call or serve voicemail.
Kamailio has a bit of a steep learning curve, which I’ve tried to cover in my Kamailio 101 series, but even so, Kamailio doesn’t understand the concept of a “call”, it deals in Sessions, as in SIP, and everything you want to do, you have to write into Kamailio’s logic. Awesome power but a lot to take in.
Note – RTPengine is growing in capabilities and integrates beautifully into Kamailio, so for some applications you may be able to use RTPengine for media handling.
Scale
Speed
Stability
Media Functions
Ease
Asterisk
X
X
Kamailio
X
X
X
Working Together
Asterisk has always had issues at scale. This is for a variety of reasons, but the most simplistic explanation is that Asterisk is fairly hefty software, and that each subscriber you add to the system consumes resources at a rate where once your system reaches a few hundred users you start to see issues with stability.
Kamailio works amazingly at scale, it’s architecture was designed with running at scale in mind, and it’s super lightweight footprint means the load on the box between handling 1,000 sessions and handling 100,000 sessions isn’t that much.
Because Asterisk has the feature set, and Kamailio has the scalability, so the the two can be used together really effectively. Let’s look at some examples of Asterisk and Kamailio working together:
Asterisk Clustering
You have a cluster of Asterisk based Voicemail servers, serving your softswitch environment. You can use a Kamailio instance to sit in front of them and route INVITEs evenly throughout the cluster of Asterisk instances.
You’d be using Asterisk’s VM functions (because Asterisk can do media functions) and Kamailio’s SIP routing functions.
You have a Kamailio based Softswitch that routes SIP traffic from customers to carriers, customers want a hosted Conference Bridge. You offer this by routing any SIP INVITES to the address of the conference bridge to an Asterisk server that serves as the conference bridge.
You’d be using Kamialio to route the SIP traffic and using Asterisk’s ability to be aware of the media stream and join several sources to offer the conference bridge.
Which should I use?
It all depends on what you need to do.
If you need to do anything with the audio stream you probably need to use something like Asterisk, FreeSwitch, YaTE, etc, as Kamailio can’t do anything with the audio stream.*
If it’s just signalling, both would generally be able to work, Asterisk would be easier to setup but Kamailio would be more scaleable / stable.
Asterisk is amazingly quick and versatile when it comes to solving problems, I can whip something together with Asterisk that’ll fix an immediate need in a faction of the time I can do the same thing in Kamailio.
On the other hand I can fix a problem with Kamailio that’ll scale to hundreds of thousands of users without an issue, and be lightning fast and rock solid.
Summary
Kamailio only deals with SIP signalling. It’s very fast, very solid, but if you need to do anything with the media stream like mixing, muxing or transcoding (RTP / audio) itself, Kamailio can’t help you.*
Asterisk is able to deal with the media stream, and offer a variety of services through it’s rich module ecosystem, but the trade-off is less stability and more resource intensive.
If you do require Asterisk functionality it’s worth looking into FreeSWITCH, although slightly harder to learn it’s generally regarded as superior in a lot of ways to Asterisk.
I don’t write much about Asterisk these days – the rest of the internet has that pretty well covered, but I regularly post about Kamailio and other facets of SIP.
I’m not a fan of Transcoding. It costs resources, often leads to reduced quality and adds latency.
Through some fancy SDP manipulating footwork we can often rejig the SDP order or limit the codecs we don’t support to cut down, or even remove entirely, the need for transcoding in the network.
There are no module parameters for SDP ops, we’ve just got to load the module with loadmodule “sdpops.so”
Use in Routing Logic
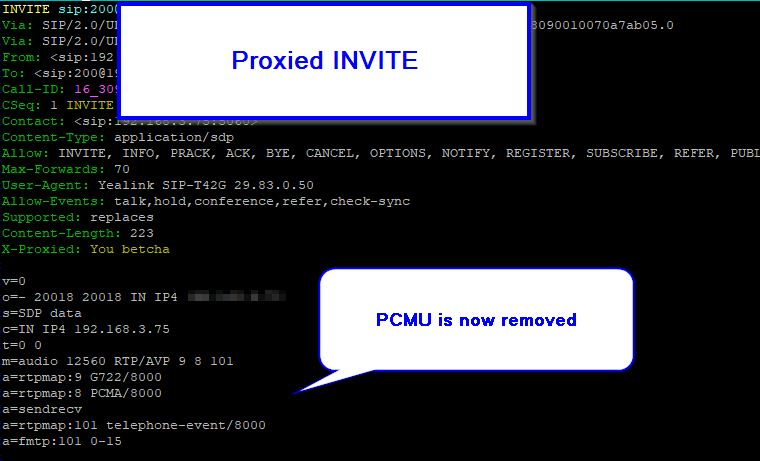
We’ll pickup where we left off on the Basic Stateless SIP Proxy use case (You can grab the basic code from that post), but this time we’ll remove PCMU (Aka G.711 μ-law) from the SDP body:
loadmodule "sdpops.so"
####### Routing Logic ########
/* Main SIP request routing logic
* - processing of any incoming SIP request starts with this route
* - note: this is the same as route { ... } */
request_route {
if(is_method("REGISTER")){
sl_reply("200", "Ok");
}
xlog("Received $rm to $ru - Forwarding");
append_hf("X-Proxied: You betcha\r\n");
#Remove PCMU (G.711 u-law) by it's SDP Payload ID
sdp_remove_codecs_by_id("0");
#Remove PCMU by name
sdp_remove_codecs_by_name("PCMU");
#Forard to new IP
forward("192.168.3.110");
}
onreply_route{
xlog("Got a reply $rs");
append_hf("X-Proxied: For the reply\r\n");
}
We can remove the codec either by it’s name (PCMU) or by it’s payload ID.
Before traversing the ProxyAfter traversing the proxy
For removing it by name we just specify the name:
#Remove PCMU by name
sdp_remove_codecs_by_name("PCMU");
And by payload ID:
#Remove PCMU (G.711 u-law) by it's SDP Payload ID
sdp_remove_codecs_by_id("0");
We may want to remove all but one codec, again super simple:
That’s obviously a bit of a problem, as we build out our network we might have a series of load balancers that send traffic to a pool of Registrars, but according to RFC3261 this can’t be done, the SIP REGISTER request would need to go direct to one of these Registrars.
To get around this the SIP Path extensions, officially called “Session Initiation Protocol (SIP) Extension Header Field for Registering Non-Adjacent Contacts” (catchy title) was defined under RFC 3327.
An additional header is introduced called “Path:” for each proxy between the UA and the Registrar,
As the SIP REGISTER request passes through each proxy, each proxy appends the Path header with the value of it’s own SIP URI.
Let’s take a look at an example call flow from [email protected] who sends his REGISTER to atlanta.com, which is proxied by atlanta.com to registrar1.atlanta.com:
Bob to atlanta.com:
[email protected] > atlanta.com
REGISTER sip:atlanta.com SIP/2.0
Via: SIP/2.0/UDP 192.0.2.4:5060;branch=z9hG4bKnashds7
To: Bob <sip:[email protected]>
From: Bob <sip:[email protected]>;tag=456248
Call-ID: 843817637684230@998sdasdh09
CSeq: 1826 REGISTER
Contact: <Bob <sip:[email protected]>>
Supported: path
The REGISTER request is received by atlanta.com, which forwards it to registrar1.atlanta.com after adding it’s own URI as a Path header.
A seemingly simple question is how many concurrent calls can a system handle.
Sadly the answer to that question is seldom simple and easy to say, even more so when we talk about transcoding.
Transcoding is the process of taking a media stream encoded in one codec (format) and transferring it to a different codec (hence trans-coding).
This can be a very resource intensive process, so there’s a large number of hardware based solutions (PCI cards / network devices) that use FGPAs and clever processor arrangements to handle the transcoding. These products are made by a multitude of different vendors but are generally called hardware transcoders.
Today we’ll talk a bit about software based transcoding, and how many concurrent calls you can transcode on common VM configurations.
These stats will translate fairly well to their dedicated hardware counterparts, but a VM provides us with a consistent hardware environment so makes it a bit easier.
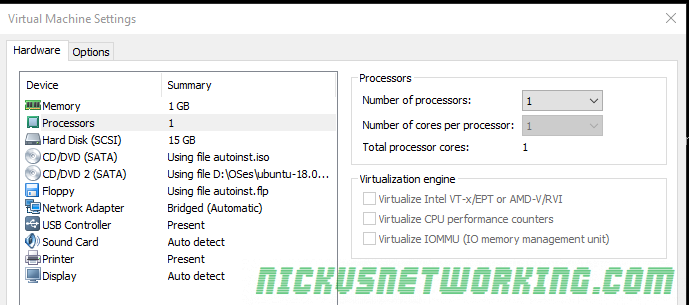
For these tests I created the baseline VM to run in VMWare Workstation with the below settings:
We’ll be transcoding using RTPengine, which recently added transcoding capabilities, so I set that up as per my post on setting up RTPengine for Transcoding.
Next I setup some SIPp scenarios to simulate call loads, from G.711 a-law to G.711 u-law (the simplest of transcoding (well re-compounding)) and used glances to get the max CPU usage and logged the results.
PCMA to PCMU (Re-companding)
PCMA to PCMU
RTPengine fared significantly better than I expected, I stopped at 150 concurrent transcoding sessions as that’s when call quality was really starting to degrade, but I was still achieving MOS of 4.3+ up to 130 concurrent sessions.
For what I needed to do, running this in a virtualised environment allowed 150 transcoding sessions before the MOS started to drop and call quality was adversely affected. Either way I was pretty amazed at how efficiently RTPengine managed to handle this.
Transcoding from one codec to a different codec was a different matter, and I’ll post the results from that another day.