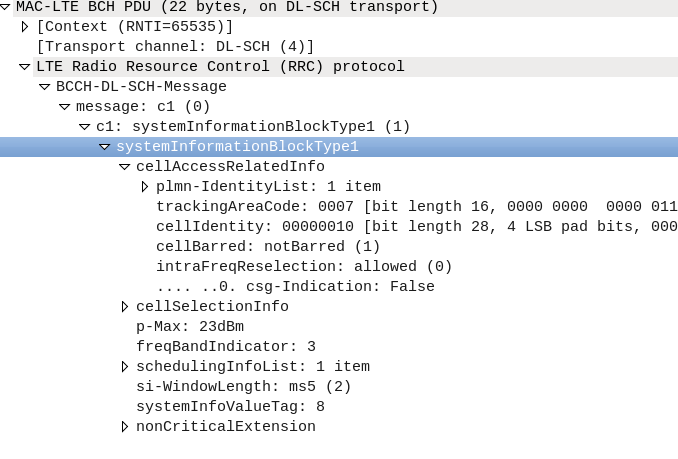
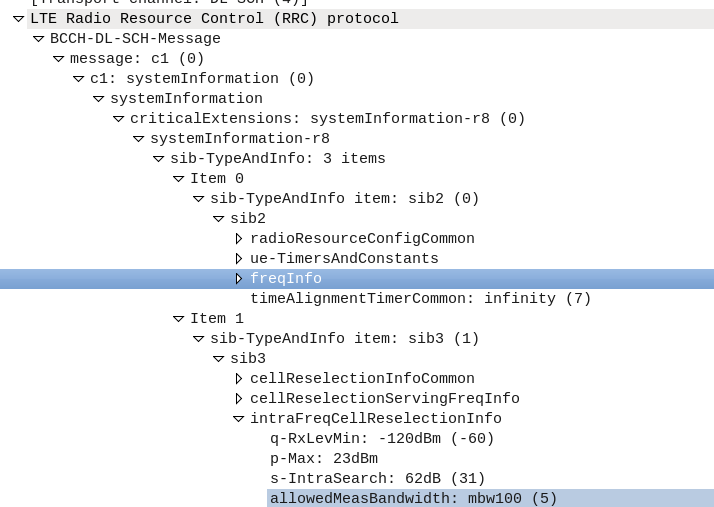
I’ve been experimenting with Inter-RAT & Inter-Frequency handovers recetly, and had an issue where what I thought was configured on the eNB I wasn’t seeing reflected on the UEs.
I understood the Neighbouring Cell reelection parameters are broadcast in the System Information Blocks, but how could I view them?
The answer – srsUE!
I can’t get over how cool the stuff coming out of Software Radio Systems is, but being able to simulate a UE and eNB on SDR hardware is pretty awesome, and also allows you to view low layer traces the vast majority of commercial UEs will never expose to a user.
After running srsUE with the PCAP option I let it scan for networks and find mine. I didn’t actually need to authenticate with the network, just lock to the cell.
So far we’ve focused on building a plain “2G” (voice and SMS only) network, which was all consumers expected twenty years ago.
As the number of users accessing the internet through DSL, Dial Up & ISDN grew, the idea of getting this data “on the go” became more appealing. TCP/IP was becoming the dominant standard for networking, the first 802.11 WiFi spec had recently been published and demand for mobile data was growing.
There’s a catch however – TCP/IP was never designed to be mobile.
An IP address exists in a single location.
(Disclaimer: While you can “move” a subnet by advertising itself out in a different location via BGP peering relationships with other operators, it’s cumbersome, can only be done per /24 or larger, and most importantly it’s painfully slow. IPv6 has MIPv6 which attempts to fix some of these points, but that’s outside of this scope.)
GPRS addressed the mobility issue by having a single fixed point the IP Address is assigned to (the Gateway GPRS Support Node), which encapsulates IP traffic to/from a mobile user into GTP Packet (GPRS Tunnelling Protocol), like GRE or any of the other common routing encapsulation protocols, allowing the traffic to be rerouted to different destinations as the users move from being served by one BTS to another BTS.
So now we’ve got a method of encapsulating our data we’ve got to work out how to get that data out over the air.
BTS Time Slots
Way back when we were first setting up our BSC and adding our BTS(s) you will have configured timeslots for each BTS configured on your BSC.
Chances are if you’ve been following along with this tutorial, that you configured the first time slot (timeslot 0) as a CCCH+SDCCH4, meaning Common Control Channel and 4 standalone dedicated control channels, and all the subsequent timeslots (timeslot 1 – 7) as Traffic Channels (full rate) – TCH/F.
This works well if we’re only carrying voice, but to carry data we need timeslots to put the data traffic on.
For this we’ll re assign a timeslot we were using on our BSC as a voice traffic channel (TCH/F) as a PDCH – a Packet Data Channel.
This means that on the BSC your timeslot config will look something like this:
In the above example I’ve assigned two timeslots for Packet Data Channels,
The more timeslots you allocate for data, the more bandwidth available, but the fewer voice resources available.
(Most GSM networks today have few data timeslots as more recent RATs like 3G/4G are taking the data traffic, and GSM is used primarily for voice and low bandwidth M2M communications)
GPRS and EDGE
GPRS comes in two flavors, GPRS and EDGE.
GPRS (General Packet Radio Services) was the first of the two, standardised in R97, and allowed users to reach a downlink speeds of up to 171Kbps using GMSK on the air interface to encode the data.
Users quickly expected more speed, so EDGE (Enhanced Data rates for Global Evolution) was standardised, from a core perspective it was the same, but from a BTS / Air interface perspective it relied on 8PSK instead of GMSK allowed users to reach a blistering 384Kbps on the downlink.
These speeds are the theoretical maximums.
As the difference between GPRS and EDGE is encoding on the air interface, from a core perspective it’s treated the same way, however as our BTS gets all it’s brains from the BSC, we’ll need to specify if the BTS should use EDGE or GPRS it in the BSC’s BTS config.
BSC Config
On the BSC for each BTS we want to enable for packet data, we’ll need to define the parameters.
There’s two other values we’ll introduce when setting this up,
The first is NSEI – the Network Service Entity Identifier, which is the identifier of the BTS’s Packet Control Unit, like the cell identity.
The second value we’ll touch on is the BVCI – the BSSGP Virtual Connections Identifier, which is used for addressing between the BTS PCU and the SGSN.
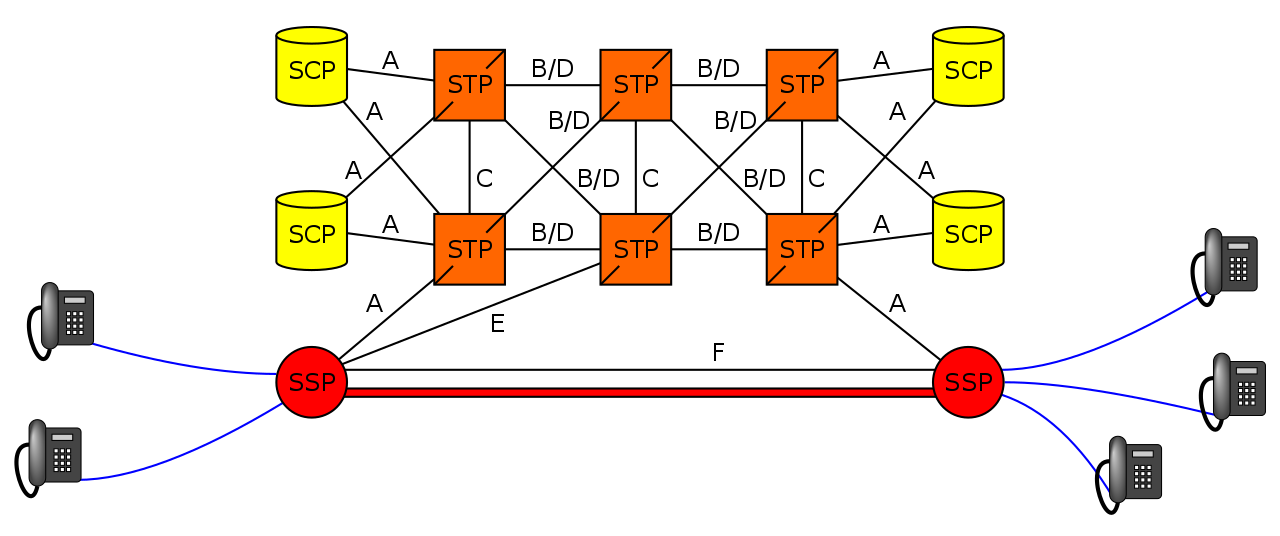
SS7 was first introduced in the 1970s and initially was designed for large scale setting up and tearing down of calls, but due to it’s layered architecture and prominence in the industry has been used for signalling between some CS network elements in Mobile Networks, including transporting messages between the MSC and any BSCs or RNCs it’s serving.
This is going to be fairly brief and Osmocom specific, keep in mind SS7 is a giant topic so there’s a huge amount we won’t cover.
Point Codes – SS7 Addressing & Routing
Historically SS7 networks were carried over TDM links of various types, and not over TCP/IP.
A point code is a unique address associated with each network element for addressing messages between network elements, it’s function is similar to that of an IP Address you’d use in IP networks.
When STP messaging is sent it includes a Source Point Code (SPC) and Destination Point Code (DPC).
The Signalling Transfer Point
Instead of a one-to-one connection between each SS7 device and every other SS7 device, a network element called a Signaling Transfer Point (STP) is used, which acts somewhat like a router.
The STP has an internal routing table made up of the Point Codes it has connections to and some logic to know how to get to each of them.
When it receives an SS7 message, the STP looks at the Destination point code, and finds if it has a path to that point code. If it does, it forwards the SS7 message on to the destination.
Like a router, an STP doesn’t really concern itself with the upper layer protocols and what they contain – As point codes are set in the MTP3 layer that’s the only layer the STP looks at and the upper layers aren’t really “any of its business”.
Sigtran & SS7 Over IP
As the world moved towards IP enabled everything, TDM based Sigtran Networks became increasingly expensive to maintain and operate, so a IETF taskforce called SIGTRAN was created to look at moving SS7 traffic to IP.
The first layer of SS7 were dropped it primarily concerned the physical side of the network, and in the Osmocom implementation the MTP3 layer and up were put into SCTP packets and carried on the network.
Notice I said SCTP and not TCP or UDP? I’ve touched upon SCTP on this blog before, it’s as if you took the best bits of TCP without the issues like head of line blocking and added multi-homing of connections.
To establish an SS7 connection over IP the MTP3 message an SCTP socket is established from the device to the STP, and then an ASP Maintenance message is sent, followed by a Registration Request containing it’s point code, and presto, we have a connection.
The Osmo STP
The Osmocom STP acts in a very trusting manner by default,
When a device wants to connect to the STP it does so via a REG_REQ (Registration Request) containing it’s Point Code. The STP accepts the connection with a REG_RSP (Registration Response).
For as long as that connection stays up any SS7 messages destined to that point code of the device that just registered, the STP will now how to get it there.
Assuming you’ve already installed the OsmoSTP you can access it on 4239:
root@gsm-bts:/etc/osmocom# telnet localhost 4239
Trying 127.0.0.1…
Connected to localhost.
Welcome to the OsmoSTP VTY interface
OsmoSTP>
After running enable we can check the current routing table:
OsmoSTP# show cs7 instance 0 sccp users
SS7 instance 0 has no SCCP
OsmoSTP# show cs7 instance 0 ro
OsmoSTP# show cs7 instance 0 route
Routing table = system
C=Cong Q=QoS P=Prio
Destination C Q P Linkset Name Linkset Non-adj Route
0.23.1/14 0 as-rkm-1 ? ? ?
0.23.3/14 0 as-rkm-2 ? ? ?
OsmoSTP# show cs7 instance 0 as all
Routing Routing Key Cic Cic Traffic
AS Name State Context Dpc Si Opc Ssn Min Max Mode
as-rkm-1 AS_ACTIVE 1 0.23.1 override
as-rkm-2 AS_ACTIVE 2 0.23.3 override
OsmoSTP# show cs7 instance 0 asp
Effect Primary
ASP Name AS Name State Type Remote IP Addr:Rmt Port SCTP
------------ ------------ ------------- ---- ----------------------- ----------
asp-dyn-0 ? ASP_ACTIVE m3ua 127.0.0.1:52192
asp-dyn-1 ? ASP_ACTIVE m3ua 127.0.0.1:33570
Packet Capture
Below is a packet capture showing a connection from an MSC to the STP.
Recently I’ve been working on a few projects with FreeSWITCH, and looking at options for programmatically generating dialplans, instead of static XML files.
Why not Static XML?
So let’s say I define a static XML dialplan.
It works great, but if I want to change the way a call routes I need to do it from the dialplan,
That’s not ideal if you’re using a distributed cluster of FreeSWITCH instances, or if you want to update on the fly.
Static XML means we have to define our dialplan when setting up the server, and would have to reconfigure the server to change it.
So what about mod_xml_curl?
When I’ve done this in the past I’ve relied on the mod_xml_curl module.
mod_xml_curl gets the XML dialplan using Curl from a web server, and so you setup a web server using Flask/PHP/etc, and dynamically generate the dialplan when the call comes in.
This sounds good, except you can’t update it on the fly.
mod_xml_curl means call routing decisions are made at the start of the call, and can’t be changed midway through the call.
So what’s ESL?
ESL is the Event Socket Library, essentially a call comes in, an ESL request is made to an external server.
For each step in the dialplan, an ESL request will be sent to the external server which tells it to do,
ESL allows us to use all FreeSWITCH’s fantastic modules, without being limited as to having to perform the call routing logic in FreeSWITCH.
So how do I use ESL?
You’ll need two create an ESL server,
Luckily there’s premade examples for popular languages;
This is a really useful Feature that allows you to break up your S-GW (And by extension P-GW) selection based on geographical areas.
This can be used to enable Local Breakout to a S/P-GW located at the same site as the tower, but controlled by a central MME / HSS.
After updating to the latest version the configuration is pretty straightforard,
P-GW Selection based on eNB ID
# o SGW selection by eNodeB ID (either single enb_id or multiple enb_ids, decimal or hex representation)
#
selection_mode: enb_id
gtpc:
- addr: 127.0.2.3
enb_id: [9413, 0x98765]
The above config will send any traffic from eNBs with the eNB ID 9413 (encoded as an intiger) or 0x98765 (Encoded as hex int equivilent 624485) to an S-GW at 127.0.2.3.
P-GW Selection based on TAC
# SGW selection by eNodeB TAC (either single TAC or multiple TACs)
#
selection_mode: tac
gtpc:
- addr: 127.0.2.2
tac: [25000, 27000, 28000]
The above config will send any traffic from eNBs with TACs of 25000, 27000, 28000 to an S-GW at 127.0.2.2.
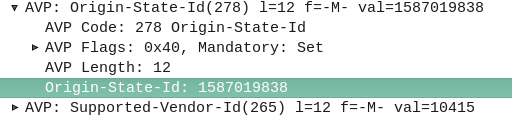
The Origin-State-Id AVP solves a kind of tricky problem – how do you know if a Diameter peer has restarted?
It seems like a simple problem until you think about it. One possible solution would be to add an AVP for “Recently Rebooted”, to be added on the first command queried of it from an endpoint, but what if there are multiple devices connecting to a Diameter endpoint?
The Origin-State AVP is a strikingly simple way to solve this problem. It’s a constantly incrementing counter that resets if the Diameter peer restarts.
If a client receives a Answer/Response where the Origin-State AVP is set to 10, and then the next request it’s set to 11, then the one after that is set to 12, 13, 14, etc, and then a request has the Origin-State AVP set to 5, the client can tell when it’s restarted by the fact 5 is lower than 14, the one before it.
It’s a constantly incrementing counter, that allows Diameter peers to detect if the endpoint has restarted.
Simple but effective.
You can find more about this in RFC3588 – the Diameter Base Protocol.
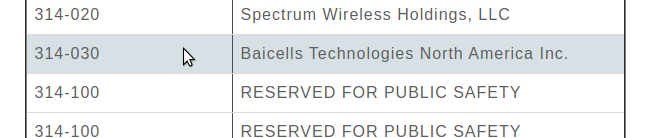
If you’re using BaiCells hardware you may have noticed the new eNBs and USIMs are shipping with the PLMN of MCC 314 / MNC 030.
First thing I do is change the PLMN, but I was curious as to why the change.
It seems 314 / 030 was never assigned to BaiCells to use and when someone picked this up they were forced to change it.
The MCC (Mobile Country Code) part is dictated by the country / geographic area the subscribers’ are in, as defined by ITU, whereas the MNC (Mobile Network Code) allocation is managed by the regional authority and ITU are informed as to what the allocations are and publish in their bulletins.
Well, SIM cards will have a different IMSI / PLMN, but the hardware supports Multi-Operator Core Network which allows one eNB to broadcast multiple PLMNs, so if you update your eNB it can broadcast both!
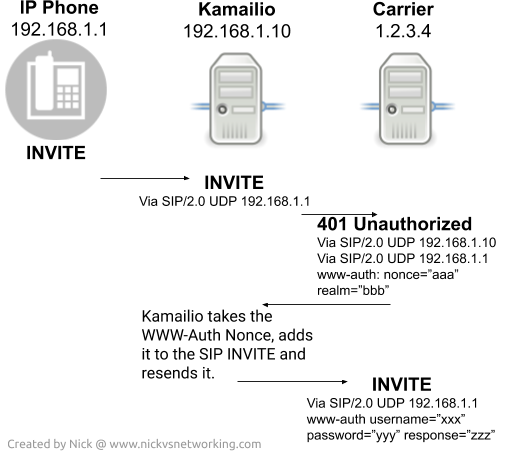
Sometimes you need Kamailio to serve as a User Agent Client, we covered using UAC to send SIP REGISTER messages and respond with the authentication info, but if you find you’re getting 401 or 407 responses back when sending an INVITE, you’ll need to use the UAC module, specifically the uac_auth() to authenticate the INVITE,
When Kamailio relays an INVITE to a destination, typically any replies / responses that are part of that dialog will go back to the originator using the Via headers.
This would be fine except if the originator doesn’t know the user name and password requested by the carrier, but Kamailio does,
Instead what we need Kamailio to do is if the response to the INVITE is a 401 Unauthorised Response, or a 407 Proxy Authentication required, intercept the request, generate the response to the authentication challenge, and send it to the carrier.
To do this we’ll need to use the UAC module in Kamailio and set some basic params:
Before we can call the t_relay() command, we need to specify a failure route, to be called if a negative response code comes back, we’ll use one called TRUNKAUTH and tell the transaction module that’s the one we’ll use by adding t_on_failure(“TRUNKAUTH”);
What we’ve done is specified to rewrite the destination URI to sip.nickvsnetworking.com, if the request type is an INVITE, it’ll load a failure route called TRUNKAUTH and proxy the request with the transaction module to sip.nickvsnetworking.com.
What we get is a 401 response back from our imaginary carrier, and included in it is a www-auth header for authentication.
To catch this we’ll create an on failure route named “TRUNKAUTH”
failure_route[TRUNKAUTH] {
xlog("trunk auth");
}
We’ll make sure the transaction hasn’t been cancelled, and if it has bail out (no point processing subsequent requests on a cancelled dialog).
failure_route[TRUNKAUTH] {
xlog("trunk auth");
if (t_is_canceled()) {
exit;
}
And determine if the response code is a 401 Unauthorised Response, or a 407 Proxy Authentication required (Authentication requests from our upstream carrier):
failure_route[TRUNKAUTH] {
xlog("trunk auth");
if (t_is_canceled()) {
exit;
}
xlog("Checking status code");
if(t_check_status("401|407")) {
xlog("status code is valid auth challenge");
}
}
Next we’ll define the username and password we want to call upon for this challenge, and generate an authentication response based on these values using the uac_auth() command,
failure_route[TRUNKAUTH] {
xlog("trunk auth");
if (t_is_canceled()) {
exit;
}
xlog("Checking status code");
if(t_check_status("401|407")) {
xlog("status code is valid auth challenge");
$avp(auser) = "test";
$avp(apass) = "test";
uac_auth();
}
}
Then finally we’ll relay that back to the carrier with our www-auth header populated with the challenge response;
When the YateBTS project launched 6 or 7 years ago I went out and purchased what was to be my first “real” SDR – The BladeRF x40.
At the time I wanted to play with GSM stuff, and so I grabbed two rubber duck antenna off an Alarm GSM Dialer I had in a junk box, thinking they’d do a better job than the stock “everything-band” antenna that came with the SDR hardware.
The offending antennas
These two became my “probably roughly aligned with the common commercial RAN bands” antennas,
I’ve used these antennas on pretty much all my RAN related projects on the BladeRF, HackRF and the LimeSDR,
GSM with YateBTS
GSM with Osmocom
LTE with srsLTE
I had some issues a recently I attributed to “probably rubbish antennas” so decided to get a pair of paddle antenna tuned for the frequencies I was working with.
While working out what to get I had a look and noted the connectors on all my SDR hardware is SMA-Female connector. Easy, so I need an SMA-Male connector on the antennas, purchase made.
Cut forward to today when the antennas arrive at my door, they’re exactly as described, however I notice some resistance when connecting them, the male pin is stiff to go into the LimeSDR, whereas there’s no resistance at all from my “trusty” rubber duck antennas.
That’s when I realised.
The two antennas I’ve been using for about 7 years at this point, have the wrong connectors (SMA and RP-SMA) and have not made contact on the signal centre pin that entire time…
They’re RP-SMA male and I need SMA male.
Wasn’t just reverse polarity – it was no polarity.
I’m a walking encyclopedia of connectors, acronyms and layer 1 stuff, but apparently this I missed.
I’m an idiot – a lucky one who didn’t burn out his SDR hardware.
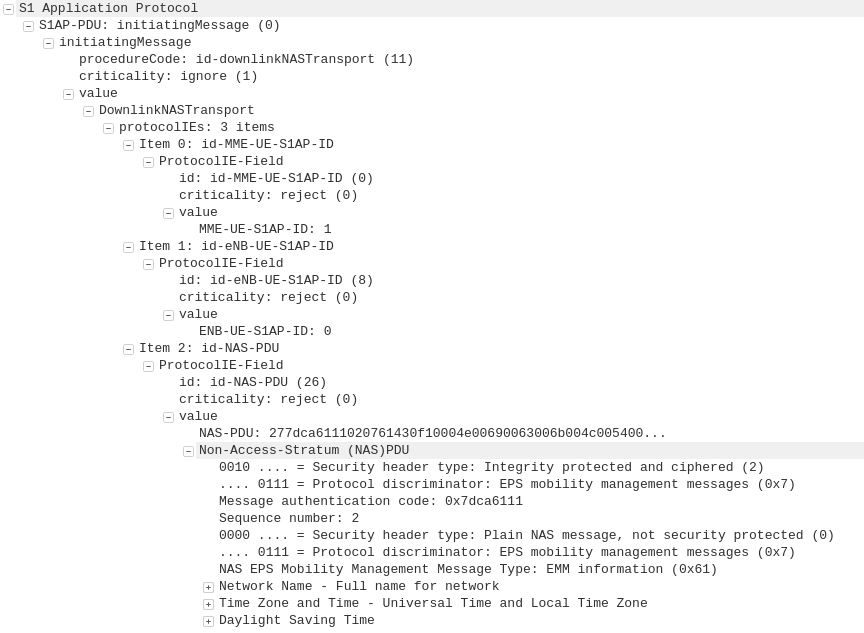
There’s a lot of layers of signalling in the LTE / EUTRAN attach procedure, but let’s take a look at the UE attach procedure from the Network Perspective.
We won’t touch on the air interface / Uu side of things, just the EPC side of the signaling.
To make life a bit easier I’ve put different signalling messages in different coloured headings:
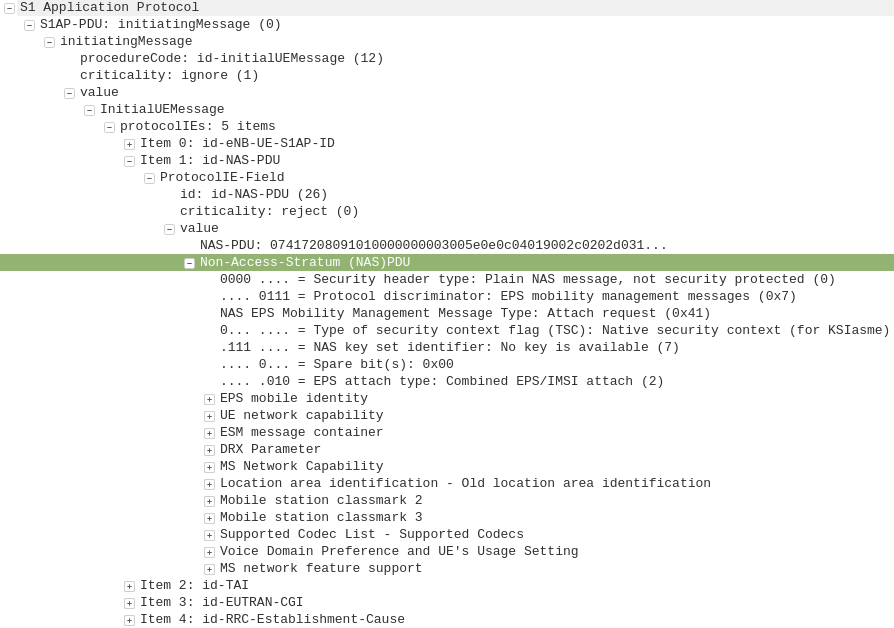
After a UE establishes a connection with a cell, the first step involved in the attach process is for the UE / subscriber to identify themselves and the network to authenticate them.
The TAI, EUTRAN-CGI and GUMME-ID sections all contain information about the serving network, such the tracking area code, cell global identifier and global MME ID to make up the GUTI.
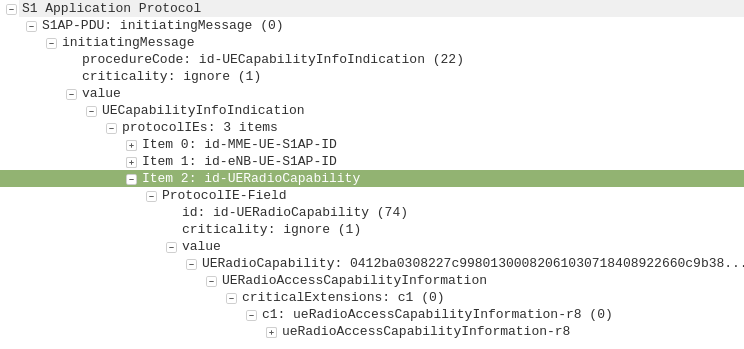
The NAS part of this request contains key information about our UE and it’s capabilities, most importantly it includes the IMSI or TMSI of the subscriber, but also includes important information such as SRVCC support, different bands and RAN technologies it supports, codecs, but most importantly, the identity of the subscriber.
If this is a new subscriber to the network, the IMSI is sent as the subscriber identity, however wherever possible sending the IMSI is avoided, so if the subscriber has connected to the network recently, the M-TMSI is used instead of the IMSI, and the MME has a record of which M-TMSI to IMSI mapping it’s allocated.
Diameter: Authentication Information Request
MME to HSS
The MME does not have a subscriber database or information on the Crypto side of things, instead this functionality is offloaded to the HSS.
I’ve gone on and on about LTE UE/Subscriber authentication, so I won’t go into the details as to how this mechanism works, but the MME will send a Authentication-Information Request via Diameter to the HSS with the Username set to the Subscriber’s IMSI.
Diameter: Authentication Information Response
HSS to MME
Assuming the subscriber exists in the HSS, a Authentication-Information Answer will be sent back from the HSS via Diameter to the MME, containing the authentication vectors to send to the UE / subscriber.
Now the MME has the Authentication vectors for that UE / Subscriber it sends back a DownlinkNASTransport, Authentication response, with the NAS section populated with the RAND and AUTN values generated by the HSS in the Authentication-Information Answer.
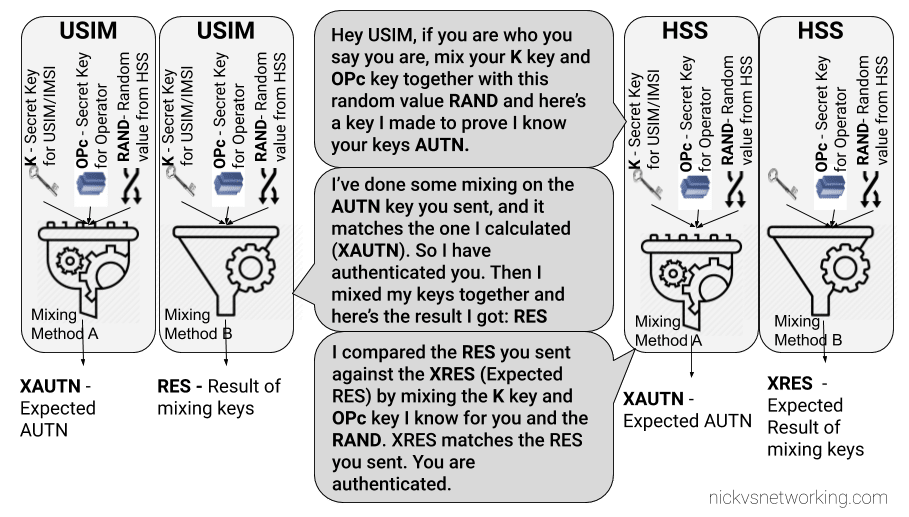
The Subscriber / UE’s USIM looks at the AUTN value and RAND to authenticate the network, and then calculates it’s response (RES) from the RAND value to provide a RES to send back to the network.
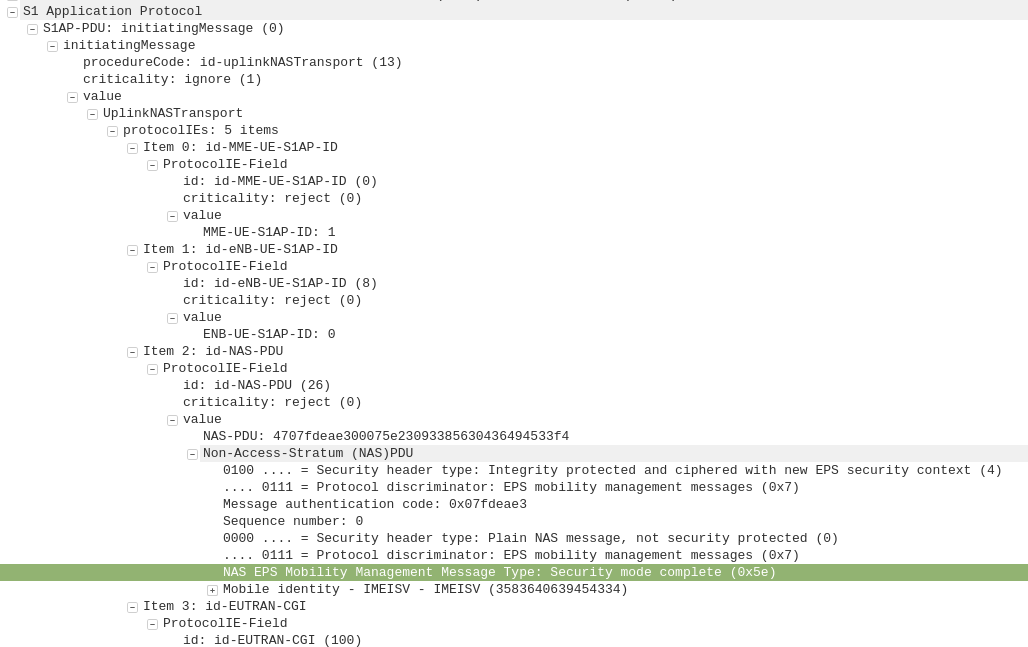
S1AP: UplinkNASTransport, Authentication response
eNB to MME
The subscriber authenticates the network based on the sent values, and if the USIM is happy that the network identity has been verified, it generates a RES (response) value which is sent in the UplinkNASTransport, Authentication response.
The MME compares the RES sent Subscriber / UE’s USIM against the one sent by the MME in the Authentication-Information Answer (the XRES – Expected RES).
If the two match then the subscriber is authenticated.
The DownlinkNASTransport, Security mode command is then sent by the MME to the UE to activate the ciphering and integrity protection required by the network, as set in the NAS Security Algorithms section;
The MME and the UE/Subscriber are able to derive the Ciphering Key (CK) and Integrity Key (IK) from the sent crypto variables earlier, and now both know them.
S1AP: UplinkNASTransport, Security mode complete
eNB to MME
After the UE / Subscriber has derived the Ciphering Key (CK) and Integrity Key (IK) from the sent crypto variables earlier, it can put them into place as required by the NAS Security algorithms sent in the Security mode command request.
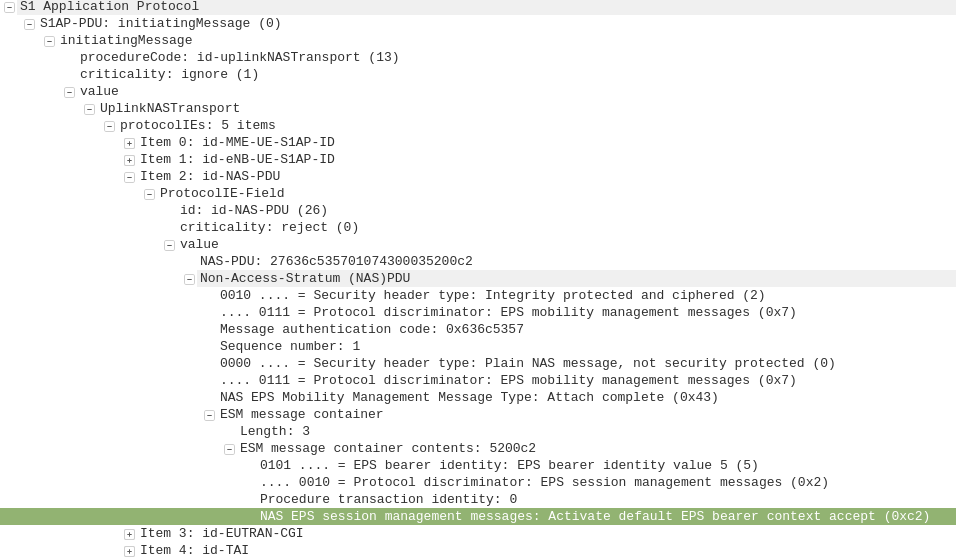
It indicates this is completed by sending the UplinkNASTransport, Security mode complete.
At this stage the authentication of the subscriber is done, and a default bearer must be established.
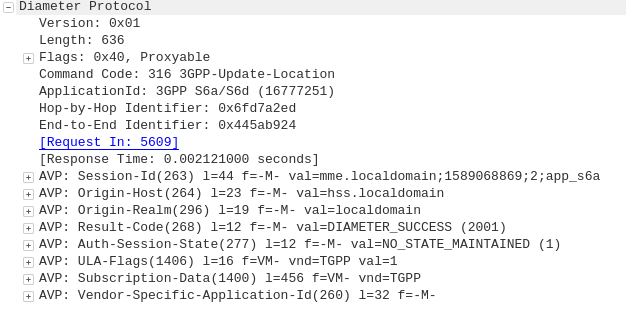
Diameter: Update Location Request
MME to HSS
Once the Security mode has been completed the MME signals to the HSS the Subscriber’s presence on the network and requests their Subscription-Data from the HSS.
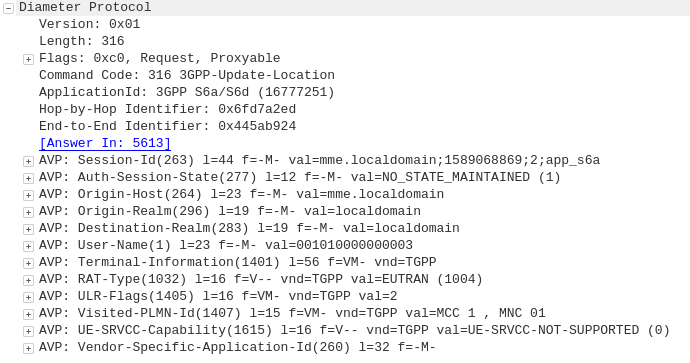
Diameter: Update Location Answer
HSS to MME
The ULA response contains the Subscription Data used to define the data service provided to the subscriber, including the AMBR (Aggregate Maximum Bit Rate), list of valid APNs and TAU Timer.
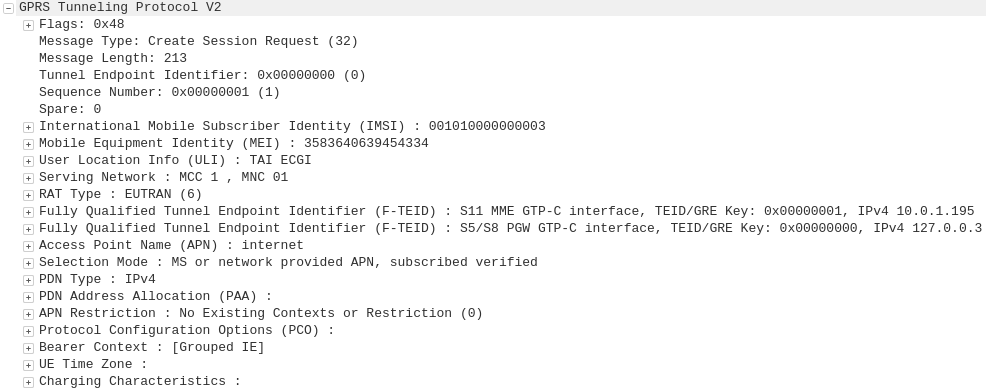
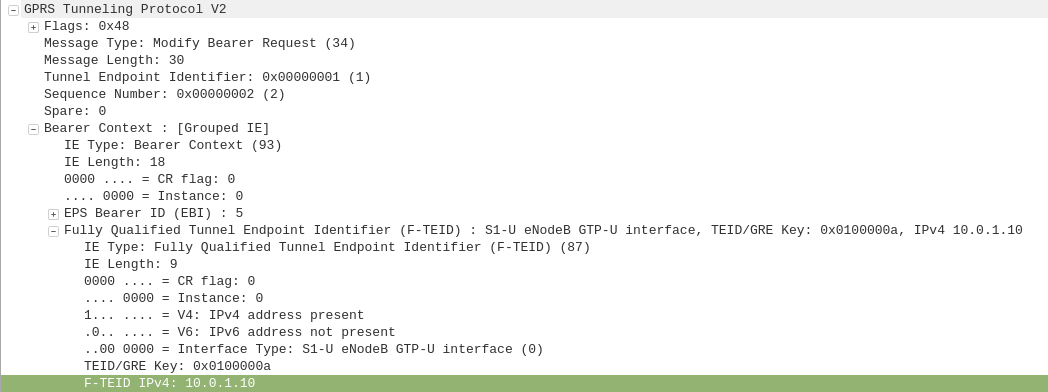
GTP-C: Create Session Request
MME to S-GW
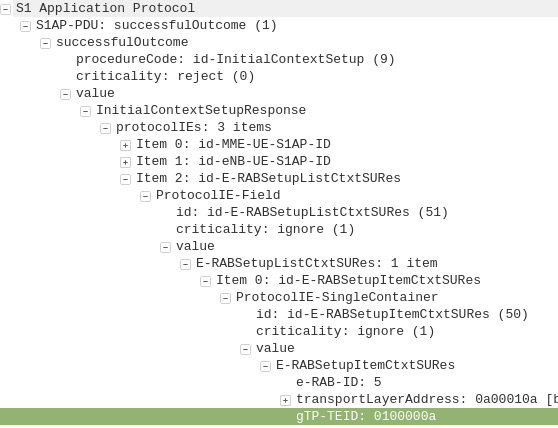
The MME transfers the responsibility of setting up the data bearers to the S-GW in the form of the Create Session Request.
This includes the Tunnel Endpoint Identifier (TEID) to be assigned for this UE’s PDN.
The S-GW looks at the request and forwards it onto a P-GW for IP address assignment and access to the outside world.
GTP-C: Create Session Request
S-GW to P-GW
The S-GW sends a Create Session Request to the P-GW to setup a path to the outside world.
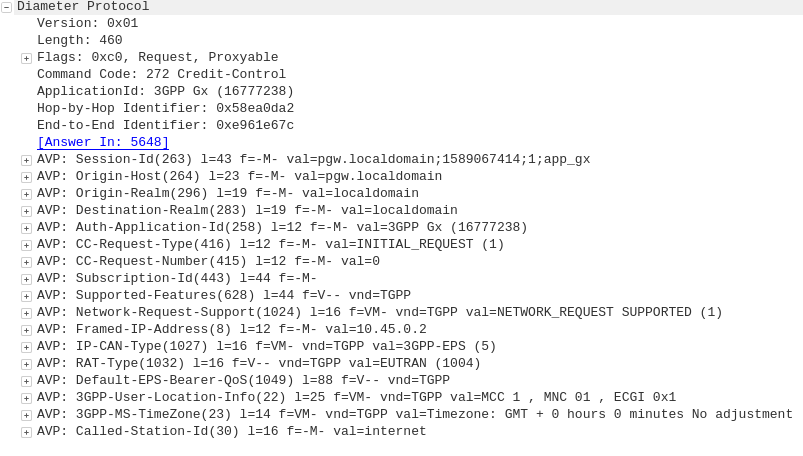
Diameter: Credit Control Request
P-GW to PCRF
To ensure the subscriber is in a state to establish a new PDN connection (not out of credit etc), a Credit Control Request is sent to the HSS.
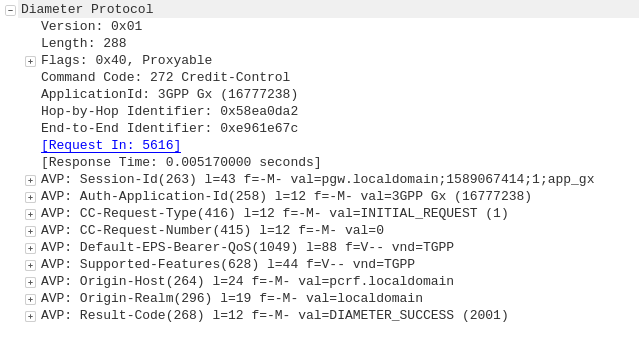
Diameter: Credit Control Answer
PCRF to P-GW
Assuming the Subscriber has adequate credit for this, a Credit Control Answer is sent and the P-GW and continue the PDN setup for the subscriber.
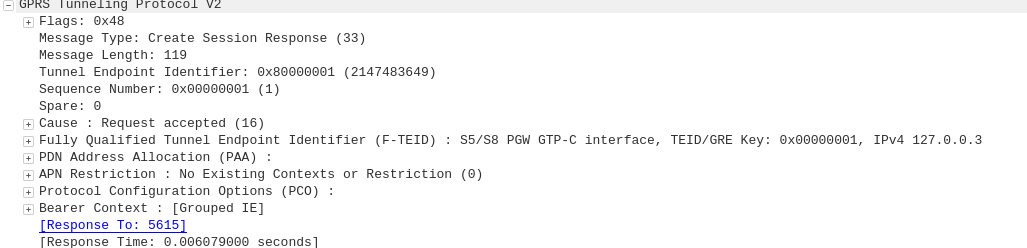
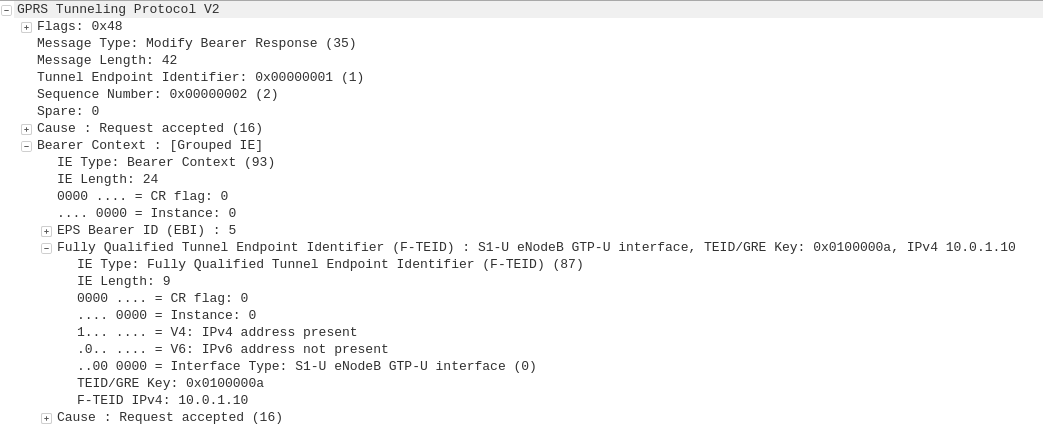
GTP-C: Create Session Response
P-GW to S-GW
The P-GW sends back a Create Session Response, containing the IP address allocated to this PDN (Framed-IP-Address).
GTP-C: Create Session Response
S-GW to MME
The S-GW slightly changes and then relays the Create Session Response back to the MME,
This message is sent to inform the eNB of the details of the PDN connection to be setup, ie AMBR, tracking area list, APN and Protocol Configuration Options,
This contains the Tunnel Endpoint Identifier (TEID) for this PDN to identify the GTP packets.
I’m a bit of a radio nerd & I’ve worked Satellites before, so the Skymuster / LTSS program had me curious. So here’s some nitty-gritty details on NBNCo’s Skymuster Satellite service.
The Payload
NBNco called the LTSS (Long Term Satellite service) but before launch they re-branded as “Skymuster”.
NBNco provided an Interim service called ISS (Interim Satellite Service). before the launch. IPSTAR satellite (Formerly ABG) and Optus services delivered this. Both of these had limited bandwidth and has since been largely replaced by the Skymuster / LTSS.
NBNCo contracted Space Systems / Loral, a US based satellite manufacturer to design and build the payloads. It’s based on the SSL 1300 platform.
When deployed, the payload itself measures 26 metres long, 9 metres tall and 12 metres wide, and weighs in at 6400Kg. Before deployment, in the satellite’s compressed form it fits within a 5-meter launch-vehicle fairing.
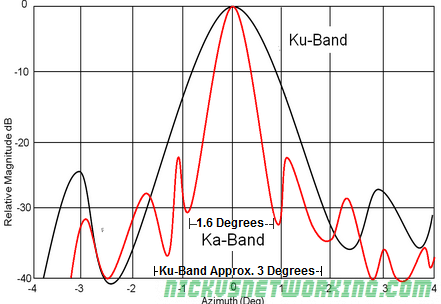
Communication to earth is via Ka-band frequencies which allows for greater density of spot beams and frequency reuse. However, capacity improvement through higher frequencies does come with some tradeoffs. Ka-band frequencies, are more susceptible to weather related conditions compared to Ku-band frequencies. Directional accuracy becomes way more important when aligning the customer dishes in Ka band also.
SSL provided image of SL-1300
Direction
Min Freq
Max Freq
Earth to Satellite
27Ghz
31Ghz
Satellite to Earth
17.7Ghz
22Ghz
These emissions are within the range of the higher end software defined radio receivers. I’m curious to see what’s being transmitted, but that’s a topic for another day.
The downlink uses RH and LH circular polarisation.
The Journey
SSL assembled the satelite in California.
SSL staff packed it into a crate and loaded into the belly of an Antinov An-124 which is flown to the launch site.
There are two Skymuster Satellites, NBN-Co 1A & 1B. 1B provides infill / capacity layer for 1A but both are identical. If the 1A satellite was lost during launch / deployment, 1B could be sent up in it’s place. This is still a real risk when launching anything.
NBN-Co 1A was the first launched, riding on a Ariane-5ECA from Guiana Space Centre in French Guiana, South America. 1A launched on 30.09.2015 and 1B launched 05.10.2016 in the same configuration.
After launch to a transit orbit, the satellites had to navigate up into a geostationary orbit at ~36,000Km. This was done using it’s 4 × SPT-100 plasma thrusters, which are exactly as cool as they sound. The final navigation process took up 40% of the fuel in the satellite. Fuel is the determining factor for the expected ~15 year lifetime of the two satellites.
SPT-100 – Source: NASA
Once in final position SSL performed 2 months worth of tests referred to as “In Orbit Testing”. SSL then handed over operational Telemetry, Tracking and Command (TT&C) to Optus Satellite (Singtel). Optus are tasked with keeping it in it’s current position.
Customer Hardware
Ericsson manage the installation, and subcontract to Hills and Skybridge for the actual work.
Out Door Unit (ODU)
There are currently 3 Satellite Antenna options that are available for installation, 80cm, 1.2m & 1.8m.
NBNco’s Test Setup
Narrower Ka-Band signals drops off more rapidly than Ku-Band signals. This means that aligning the Ka-Band antenna within the degrees of usable Azimuth within the Line of Sight maximises the antenna gain.
Required accuracy for each of the antennas:
80 cm: 1.4 degrees,
120 cm: 1.0 degrees
180 cm: 0.7 degrees
The below graph shows being off by 1 degree from the required accuracy, leads to -30dB drop. This translates to a power ratio of 1000, or 1/1000 of the power if correctly aligned.
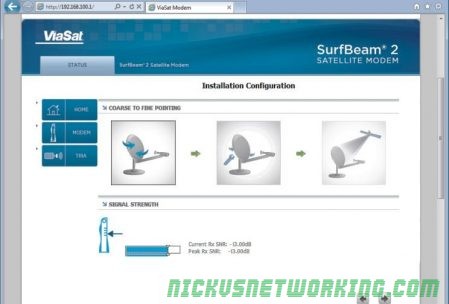
The alignment process is done by the installer pointing the dish in the correct azimuth / elevation. This is based on compass / inclinometer readings, or smart phone apps. Once a rough alignment has been set, a tone-generator on the TIRA is used to align the dish.
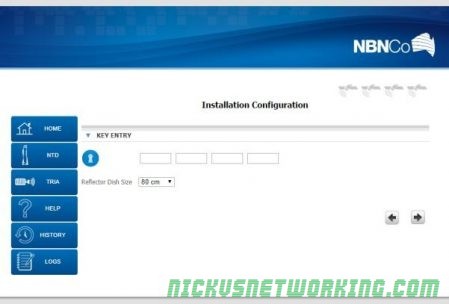
This process requires a 16 digit installation key.
The key containing the frequency used in the installation, beam Assignment & TRIA Polarisation (The 6w version has automatic (Polarisation).
That’s entered into the installation setup page at:
The TRIA is the equivalent of a feed horn, an all in one Tx/Rx assembly. They are available in 3w and 6w variants, based on the estimated signal levels of the installation location. That’s determined by factors like high rain areas or if the subscriber is on the edge of a beam.
3W Version
The 6W version has an extra F-Connector for the required DC power injection. The 6w version also has a two F-Connector gang-plate / wallplate when installed for the second RG6 run to power it.
Interestingly there’s a minimum length of cable run (8m) specified for these installations. Anything less than 8m leads to lower resistance and possible overheating.
There is a minimum length of 8m for the cable run this is very important as it provides the right amount of cable resistance so the modem does not get hot and over heat. Max cable run is 50m.
Configuration
Transparent Performance Enhancing Proxy (TPEP)
TPEP aka Web Acceleration, is a service offered by NBNco to spoof TCP replies, to make the handshake more efficient. It can, unsurprisingly, lead to headaches accessing services, particularly those that employ TLS.
The installer key sets the beam, and his can be remotely changed by NBNco MAC / NOC team.
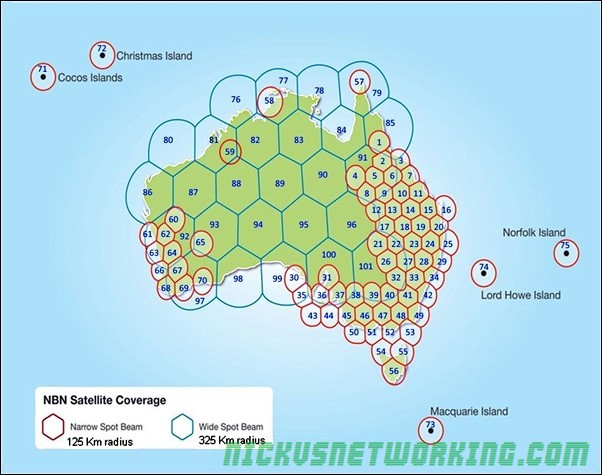
BIRRAUS have a good article explaining the spot beams available.
Educational Port
Like the other NBNco NTDs, there are multiple UNI-D ports available on the Skymuster modem allowing segregation of services.
One option that seems to be gaining traction is a dedicated port on the modem for educational use, on one of the UNI-D ports on the modem.
Educational Ports are configured to allow access for remote / distance education students.
The local state government sets pricing, speeds and data usages.
Ground Stations
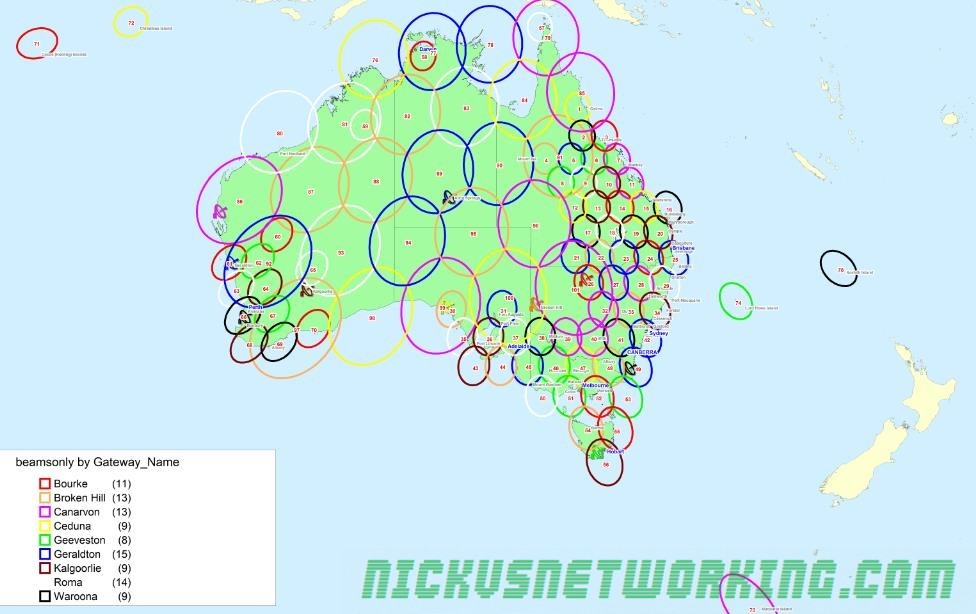
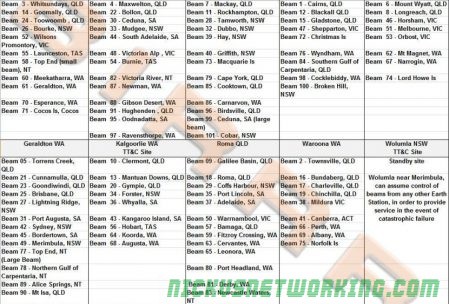
There are 9 active and one standby ground stations, geographically spread across Australia, with a standby in Wolumna, NSW. The standby is capable of assuming control for any of the other ground stations.
ViaSat built the equipment and services different spot beams.
Again, BIRRAUS have this covered in their article, but here’s an extract they’ve made listing the ground stations and beams serviced.
Wolumla ground station
Future
Solar Transit
Solar transits happen twice yearly when the satellite is aligned directly between the sun and Australia.
The immense solar radiation from the sun overloads the transceivers on the ground, as they’re positioned at the satelite, with the sun behind it overloading the signals.
This lasts for about 6 minutes twice yearly, and affects different ground stations and each of the satellites at different times.
Copper Cutoff
Currently the copper decommissioning does not apply to Skymuster services. This means customers with a copper POTS line, can keep it indefinitely.
This has lead to headaches with incumbent providers who had intended to decommission / sell off remote exchanges, but will be required under Universal Service Obligation to keep them active.
3rd Satellite
Due to unexpectedly large uptake of Skymuster services, NBNco had floated the possibility of launching a 3rd Satelite in 2020:
Scenario 3: Third satellite – This scenario assumes that NBN Co constructs and launches a third satellite at the end of CY20. This mitigates the need to build some fixed wireless base stations and FTTN distribution areas. The capacity of this satellite will only be partially required to meet NBN Co’s needs
Scenario 4: Third satellite in partnership – This scenario mirrors Scenario 3, but assumes that NBN Co enters into a partnership with an external party to access only the required capacity on a third satellite rather than building and owning it outright.
The NBNco launched a fleet of “Road Muster” 4WDs for promotion of the services. They drive from town to town, spruiking the benefits of Skymuster.
On the roof of the 4WD is a Satellite ODU, which seems to be self / remote positioning.
Online sleuthing reveals it’s a EXPLORER 8120 manufactured by Cobham. It featuring auto-acquire, drive-away antenna system using Dynamic Pointing Correction technology. At $32k USD, it’s rather pricey, and outside the range of most grey-nomads and campers.
If a user wanted to manually position the dish, they could using a service like DishPointer.com or Wolfram Alpha. This would give a rough alignment and then the tone generator “Point and Peak” for the fine adjustment.
Layer 3 Services
Skymuster services are setup as L2 services.
NBNCo has highlighted from day 1, the option of using Layer 3 for deliver to enable deep packet inspection.
These posts focus on the use of Diameter and SIP in an IMS / VoLTE context, however these practices can be equally applied to other networks.
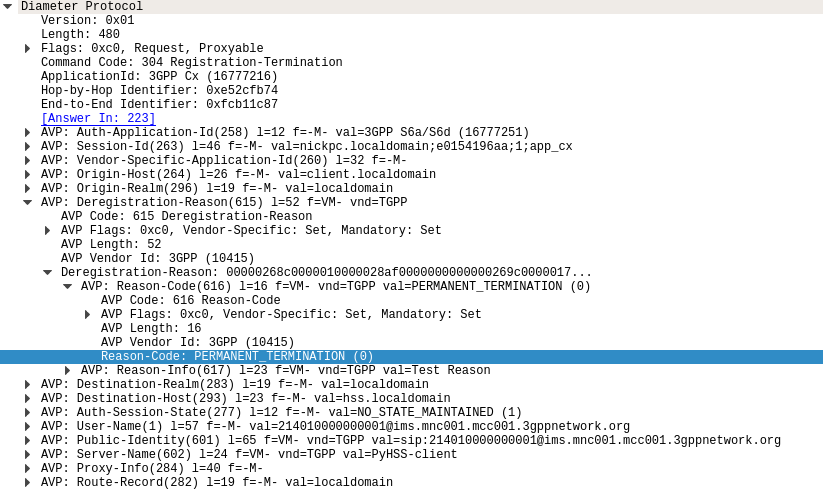
The Registration-Termination Request / Answer allow a Diameter Client (S-CSCF) to indicate to the HSS (Diameter Server) that it is no longer serving that user and the registration has been terminated.
Basics:
The RFC’s definition is actually pretty succinct as to the function of the Server-Assignment Request/Answer:
The Registration-Termination-Request is sent by a Diameter Multimedia server to a Diameter Multimedia client in order to request the de-registration of a user.
Reference: TS 29.229
The Registration-Termination-Request commands are sent by a S-CSCF to indicate to the Diameter server that it is no longer serving a specific subscriber, and therefore this subscriber is now unregistered.
There are a variety of reasons for this, such as PERMANENT_TERMINATION, NEW_SIP_SERVER_ASSIGNED and SIP_SERVER_CHANGE.
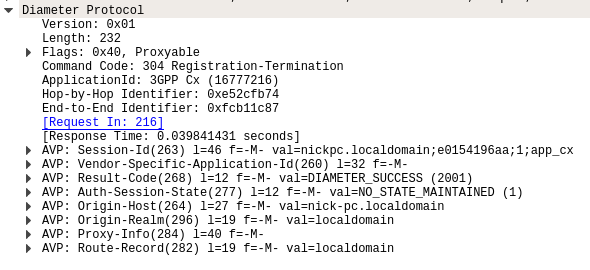
The Diameter Server (HSS) will typically send the Diameter Client (S-CSCF) a Registration-Termination-Answer in response to indicate it has updated it’s internal database and will no longer consider the user to be registered at that S-CSCF.
Packet Capture
I’ve included a packet capture of these Diameter Commands from my lab network which you can find below.
These posts focus on the use of Diameter and SIP in an IMS / VoLTE context, however these practices can be equally applied to other networks.
The Diameter User-Authorization-Request and User-Authorization-Answer commands are used as the first line of authorization of a user and to determine which Serving-CSCF to forward a request to.
Basics
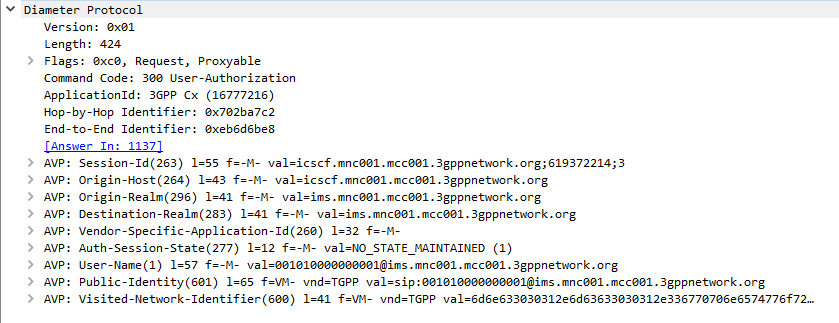
When a SIP Proxy (I-CSCF) receives an incoming SIP REGISTER request, it sends a User-Authorization-Request to a Diameter server to confirm if the user exists on the network, and which S-CSCF to forward the request to.
When the Diameter server receives the User-Authorization-Request it looks at the User-Name (1) AVP to determine if the Domain / Realm is served by the Diameter server and the User specified exists.
Assuming the user & domain are valid, the Diameter server sends back a User-Authorization-Answer, containing a Server-Capabilities (603) AVP with the Server-Name of the S-CSCF the user will be served by.
I always find looking at the packets puts everything in context, so here’s a packet capture of both the User-Authorization-Request and the User-Authorization-Answer.
Wireshark display of User-Authorization-Request packet
Wireshark display of User-Authorization-Answer packet
First Registration
If this is the first time this Username / Domain combination (Referred to in the RFC as an AOR – Address of Record) is seen by the Diameter server in the User-Authorization-Request it will allocate a S-CSCF address for the subscriber to use from it’s pool / internal logic.
The Diameter server will store the S-CSCF it allocated to that Username / Domain combination (AoR) for subsequent requests to ensure they’re routed to the same S-CSCF.
The Diameter server indicates this is the first time it’s seen it by adding the DIAMETER_FIRST_REGISTRATION (2001) AVP to the User-Authorization-Answer.
Subsequent Registration
If the Diameter server receives another User-Authorization-Request for the same Username / Domain (AoR) it has served before, the Diameter server returns the same S-CSCF address as it did in the first User-Authorization-Answer.
It indicates this is a subsequent registration in much the same way the first registration is indicated, by adding an DIAMETER_SUBSEQUENT_REGISTRATION (2002) AVP to the User-Authorization-Answer.
User-Authorization-Type (623) AVP
An optional User-Authorization-Type (623) AVP is available to indicate the reason for the User-Authorization-Request. The possible values / reasons are:
Creating / Updating / Renewing a SIP Registration (REGISTRATION (0))
Establishing Server Capabilities & Registering (CAPABILITIES (2))
Terminating a SIP Registration (DEREGISTRATION (1))
If the User-Authorization-Type is set to DEREGISTRATION (1) then the Diameter server returns the S-CSCF address in the User-Authorization-Answer and then removes the S-SCSF address it had associated with the AoR from it’s own records.
These posts focus on the use of Diameter and SIP in an IMS / VoLTE context, however these practices can be equally applied to other networks.
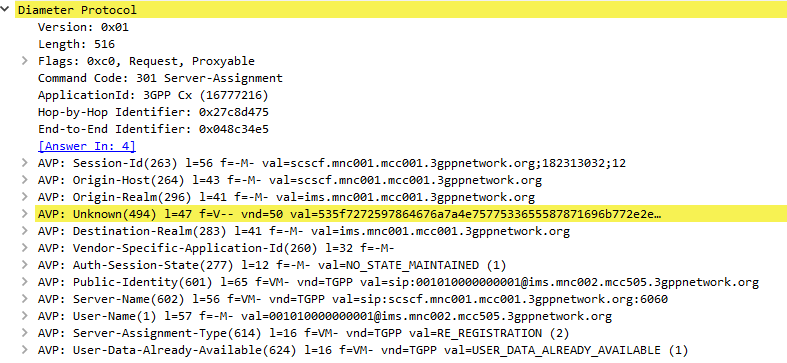
The Server-Assignment-Request/Answer commands are used so a SIP Server can indicate to a Diameter server that it is serving a subscriber and pull the profile information of the subscriber.
Basics:
The RFC’s definition is actually pretty succinct as to the function of the Server-Assignment Request/Answer:
The main functions of the Diameter SAR command are to inform the Diameter server of the URI of the SIP server allocated to the user, and to store or clear it from the Diameter server.
Additionally, the Diameter client can request to download the user profile or part of it.
The Server-Assignment-Request/Answer commands are sent by a S-CSCF to indicate to the Diameter server that it is now serving a specific subscriber, (This information can then be queried using the Location-Info-Request commands) and get the subscriber’s profile, which contains the details and identities of the subscriber.
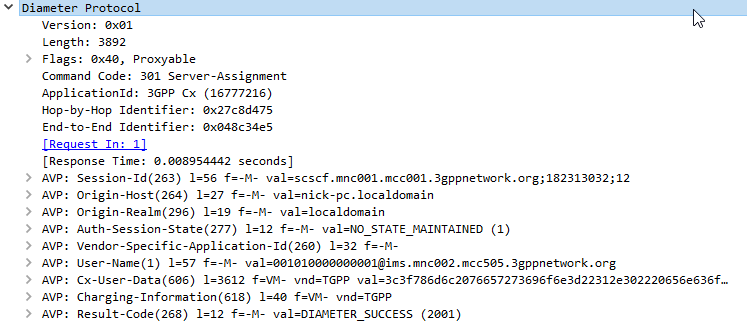
Typically upon completion of a successful SIP REGISTER dialog (Multimedia-Authentication Request), the SIP Server (S-CSCF) sends the Diameter server a Server-Assignment-Request containing the SIP Username / Domain (referred to as an Address on Record (SIP-AOR) in the RFC) and the SIP Server (S-CSCF)’s SIP-Server-URI.
The Diameter server looks at the SIP-AOR and ensures there are not currently any active SIP-Server-URIs associated with that AoR. If there are not any currently active it then stores the SIP-AOR and the SIP-Server-URI of the SIP Server (S-CSCF) serving that user & sends back a Server-Assignment-Answer.
For most request the Subscriber’s profile is also transfered to the S-SCSF in the Server-Assignment-Answer command.
SIP-Server-Assignment-Type AVP
The same Server-Assignment-Request command can be used to register, re-register, remove registration bindings and pull the user profile, through the information in the SIP-Server-Assignment-Type AVP (375),
Common values are:
NO_ASSIGNMENT (0) – Used to pull just the user profile
The Cx-User-Data profile contains the subscriber’s profile from the Diameter server in an XML formatted dataset, that is contained as part of the Server-Assignment-Answer in the Cx-User-Data AVP (606).
The profile his tells the S-CSCF what services are offered to the subscriber, such as the allowed SIP Methods (ie INVITE, MESSAGE, etc), and how to handle calls to the user when the user is not registered (ie send calls to voicemail if the user is not there).
There’s a lot to cover on the user profile which we’ll touch on in a later post.
These posts focus on the use of Diameter and SIP in an IMS / VoLTE context, however these practices can be equally applied to other networks.
The Location-Information-Request/Answer commands are used so a SIP Server query a Diameter to find which P-CSCF a Subscriber is being served by
Basics:
The RFC’s definition is actually pretty succinct as to the function of the Server-Assignment Request/Answer:
The Location-Info-Request is sent by a Diameter Multimedia client to a Diameter Multimedia server in order to request name of the server that is currently serving the user.Reference: 29.229-
The Location-Info-Request is sent by a Diameter Multimedia client to a Diameter Multimedia server in order to request name of the server that is currently serving the user.
Reference: TS 29.229
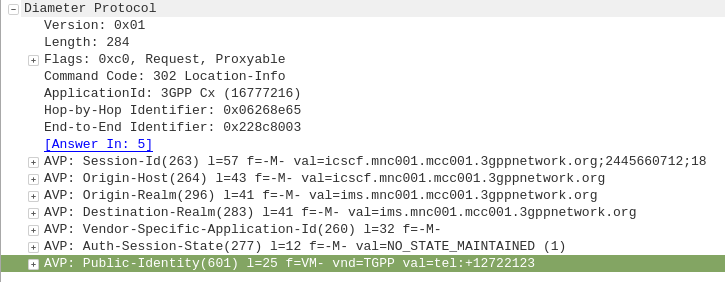
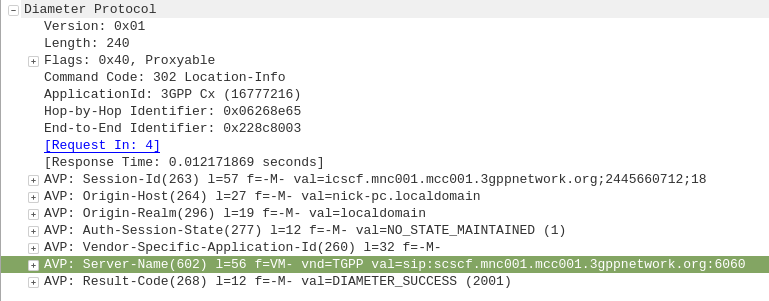
The Location-Info-Request commands is sent by an I-CSCF to the HSS to find out from the Diameter server the FQDN of the S-CSCF serving that user.
The Public-Identity AVP (601) contains the Public Identity of the user being sought.
Here you can see the I-CSCF querying the HSS via Diameter to find the S-CSCF for public identity 12722123
The Diameter server sends back the Location-Info-Response containing the Server-Name AVP (602) with the FQDN of the S-CSCF.
Packet Capture
I’ve included a packet capture of these Diameter Commands from my lab network which you can find below.
These posts focus on the use of Diameter and SIP in an IMS / VoLTE context, however these practices can be equally applied to other networks.
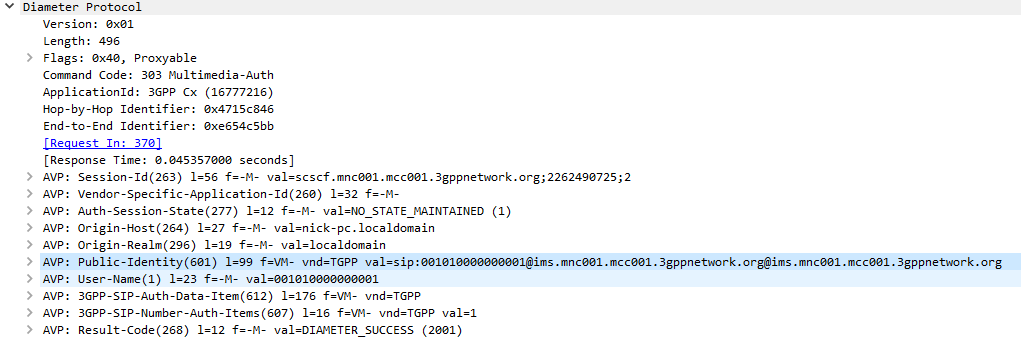
The Multimedia-Authentication-Request/Answer commands are used to Authenticate subscribers / UAs using a variety of mechanisms such as straight MD5 and AKAv1-MD5.
Basics:
When a SIP Server (S-CSCF) receives a SIP INVITE, SIP REGISTER or any other SIP request, it needs a way to Authenticate the Subscriber / UA who sent the request.
We’ve already looked at the Diameter User-Authorization-Request/Answer commands used to Authorize a user for access, but the Multimedia-Authentication-Request / Multimedia-Authentication-Answer it used to authenticate the user.
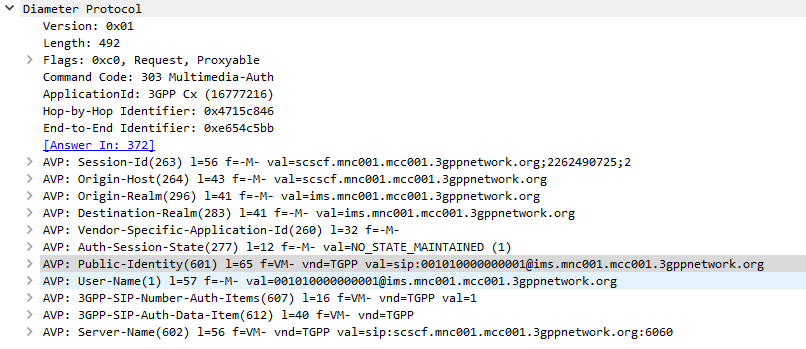
The SIP Server (S-CSCF) sends a Multimedia-Authentication-Request to the Diameter server, containing the Username of the user attempting to authenticate and their Public Identity.
The Diameter server generates “Authentication Vectors” – these are Precomputed cryptographic challenges to challenge the user, and the correct (“expected”) responses to the challenges. The Diameter puts these Authentication Vectors in the 3GPP-SIP-Auth-Data (612) AVP, and sends them back to the SIP server in the Multimedia-Authentication-Answer command.
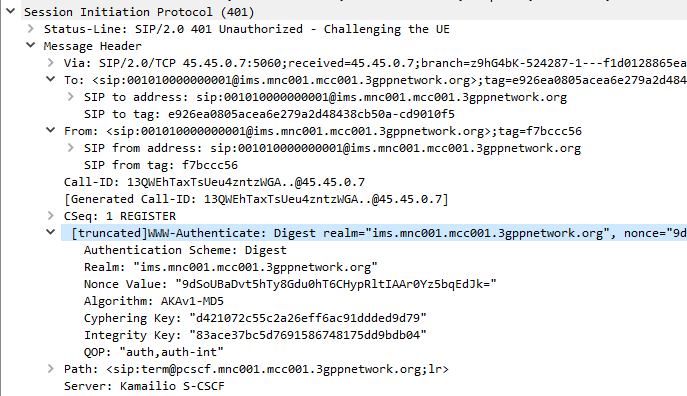
The SIP server sends the Subscriber / UA a SIP 401 Unauthorized response to the initial request, containing a WWW-Authenticate header containing the challenges.
SIP 401 Response with WWW-Authenticate header populated with values from Multimedia-Auth-Answer
The Subscriber / UA sends back the initial request with the WWW-Authenticate header populated to include a response to the challenges. If the response to the challenge matches the correct (“expected”) response, then the user is authenticated.
Multimedia-Authentication-Request
Multimedia-Authentication-Answer
I always find it much easier to understand what’s going on through a packet capture, so here’s a packet capture showing the two Diameter commands,
Note: There is a variant of this process allows for stateless proxies to handle this by not storing the expected authentication values sent by the Diameter server on the SIP Proxy, but instead sending the received authentication values sent by the Subscriber/UA to the Diameter server to compare against the expected / correct values.
The Cryptography
The Cryptography for IMS Authentication relies on AKAv1-MD5 which I’ve written about before,
Essentially it’s mutual network authentication, meaning the network authenticates the subscriber, but the subscriber also authenticates the network.
You may want to connect Open5GS’ MME to a different Home Subscriber Server (HSS),
To do it we need a few bits of information:
The Domain Name of the HSS
The Realm of the HSS
The IP of the HSS
The Transport Used (TCP/SCTP)
If TLS is used
With these bits of information we can go about modifying the Open5GS MME config to talk to our different HSS.
Edit FreeDiameter Config
The config for the Open5GS MME’s Diameter peers is handled by the FreeDimaeter library,
You can find it’s config files in:
/etc/freediameter/mme.conf
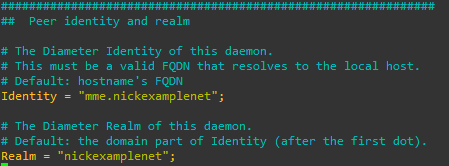
We’ll start by changing the realm to match the realm of the HSS and the identity to match the identity configured as the MME peer on the HSS.
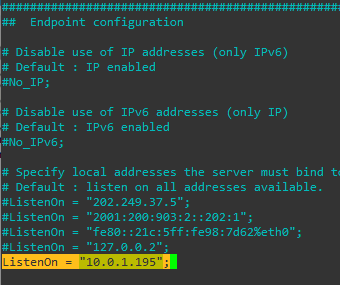
We’ll next set the ListenOn address to be a reachable IP address isntead of just a loopback address,
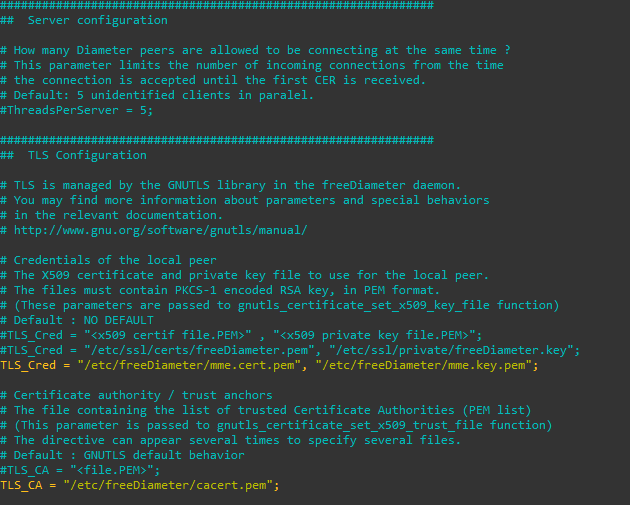
If you’re using TLS you’ll need to put your certificates and private key files into the TLS config,
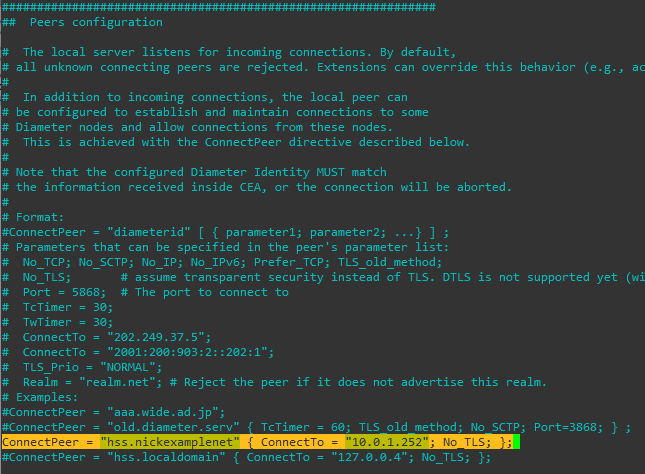
Finally we’ll put our HSS details in the Peer Configuration;
Once all this is done we’ll need to restart our MME and you should see the Diameter Capabilities Exchange / Answer commands between the HSS and the MME if all was successful,
And that’s it! We’re connected to an external HSS.
Through the freeDiameter config file you can specify multiple ConnectPeer() entries to connect to multiple HSS (like a pool of them), and requests will be distributed evenly between them.
So SDR is all well and good, but a late night eBay purchase landed me two ipaccess NanoBTS units second hand from the US.
The hefty metal units are designed as GSM access points / picocells for indoor use, with a stable Uu / radio interface and speaking Abis over IP, it integrates nicely with Osmocom’s stack and was used by the Osmocom team as a bit of a development platform in the past.
Finding the Current IP
Because these units are second hand, first step was finding the current IP.
I ran a packet capture on the interface the units were plugged into until I saw some traffic showing their current IP.
Once you’re in the correct subnet you can use the abisip-find tool to find any units:
abisip-find
Mine showed up on a 10.97.99.15 IP, so I put my machine on the 10.97.99.x/24 subnet so I could reach them.
Changing IP Details
Once I had the current IP details it was time to change the IP details, Unit ID and OML / AbisIP IP address.
My unit came on 10.97.99.15, but I wanted it on 10.0.1.204/24 and pointed to my BSC at 10.0.1.201, so I set that using the command,
Note: I’m running version 19.12.0 which I installed from the repos due to issues with 20.4.0 (latest when I wrote this) and stability on LimeSDR.
I wrote the other day about installing SRS LTE stack,
But installing it is one thing, meeting all the requirements to use it with your SDR hardware turns out to be another whole thing all together.
srsENB is a software defined eNodeB, allowing you to use a Software Defined Radio to serve as an eNodeB, UE and a few other utilities.
SRS’ implementation of the eNB is supposed to be 3GPP R10 compliant and supports eMBMS to boot.
Meeting Dependencies
Installing prerequisites
I’m using a LimeSDR, but these instructions also for for the BladeRF. I found the frequency stability of my BladeRF X40 wasn’t great, meaning when running SRS’s eNodeB the cell wasn’t visible to my UE.
sudo apt install tree vim git g++ make cmake pkg-config python-numpy swig libi2c-dev libusb-1.0-0-dev libfftw3-dev libmbedtls-dev libboost-program-options-dev libconfig++-dev libsctp-dev gnuradio
Install SoapySDR from Source
git clone https://github.com/pothosware/SoapySDR.git pushd SoapySDR git checkout tags/soapy-sdr-0.7.2 -b soapy-sdr-0.7.2 mkdir build cd build cmake .. make sudo make install sudo ldconfig popd
Install LimeSuite
You can skip this if you’re using a BladeRF
git clone https://github.com/myriadrf/LimeSuite.git
pushd LimeSuite
#git checkout tags/v19.04.0 -b v19.04.0
mkdir builddir
cd builddir
cmake ..
make
sudo make install
sudo ldconfig
cd ../udev-rules
sudo sh ./install.sh
popd
Install BladeRF
You can skip this if using a LimeSDR
git clone https://github.com/Nuand/bladeRF.git
pushd bladeRF/host/
mkdir build
cd build/
cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/usr/local -DINSTALL_UDEV_RULES=ON -DBLADERF_GROUP=plugdev ..
make
sudo make install
sudo ldconfig
sudo mkdir -p /etc/Nuand/bladeRF/
sudo wget https://www.nuand.com/fpga/hostedx40-latest.rbf --output-document /etc/Nuand/bladeRF/hostedx40.rbf
popd
git clone https://github.com/pothosware/SoapyBladeRF.git
pushd SoapyBladeRF
mkdir build
cd build
cmake ..
make
sudo make install
popd
Install SRS GUI
(Optional but makes life easier and has to be done prior to installing SRSLTE)
sudo apt-get install libboost-system-dev libboost-test-dev libboost-thread-dev libqwt-qt5-dev qtbase5-dev
git clone https://github.com/srsLTE/srsGUI.git
pushd srsGUI
mkdir build
cd build
cmake ..
make
sudo make install
popd
Install SRSLTE (SRSenb & SRSue)
pushd srsLTEmkdir build cd build cmake ../ make make test sudo make install sudo ldconfig sudo ./srslte_install_configs.sh service popd
One nifty feature of this interface is that you can send SMS using the MSC to switch the SMS traffic and the LTE/EUTRAN to transfer the messaging.
This means you don’t need Circuit Switched Fallback to send or receive SMS on LTE.
I assume this functionality was added to avoid the signalling load of constantly changing RAN technologies each time a subscriber sent or received an SMS, but I couldn’t find much about it’s history.
In order to get this to work you’ll essentially need the exact same setup I outlined in my CSFB example (Osmo-MSC, Osmo-STP, Osmo-HLR populated with the IMSI and MSISDN values you want to use for SMS), although you won’t actually need a GERAN / GSM radio network.
Once that’s in place you can just send SMS between subscribers,
Plus from the VTY terminal of OsmoMSC you can send SMS too: