MOCN is one of those great concepts I’d not really come across,
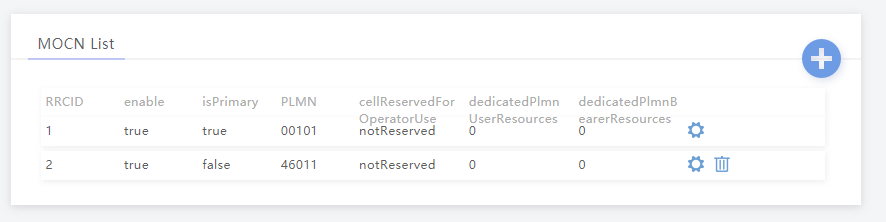
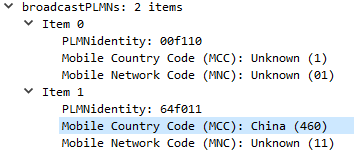
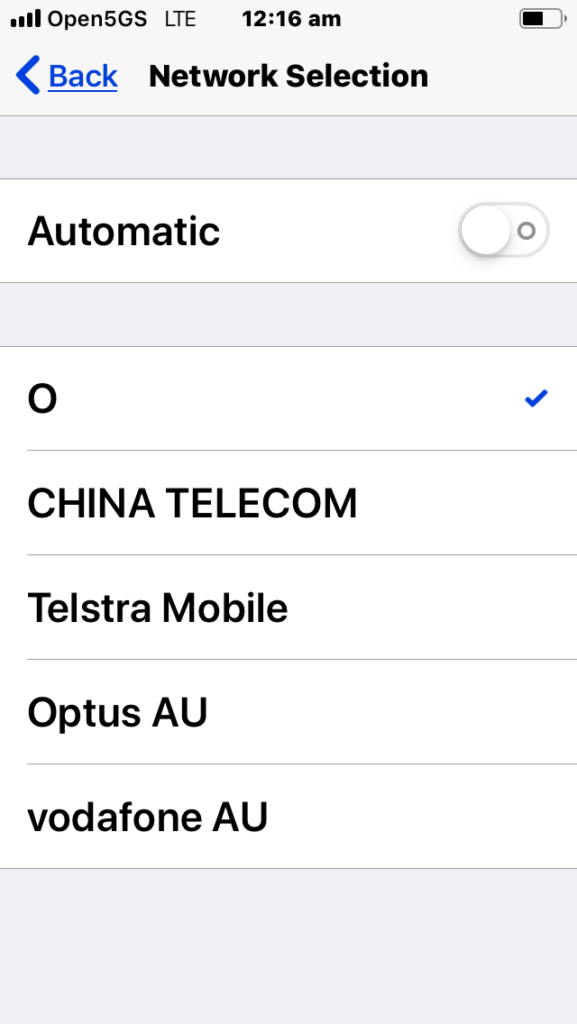
Multi-tenancy on the RAN side of the network, allowing an eNB to broadcast multiple PLMN IDs (MCC/MNC) in the System Information Block (SIB).
It allows site sharing not just on the tower itself, but site sharing on the RAN side, allowing customers of MNO A to see themselves connected to MNO A, and customers from MNO B see themselves as connected to MNO B, but they’re both connected to the same RAN hardware.
Setup in my lab was a breeze; your RAN hardware will probably be different.
In terms of signaling it’s a standard S1AP Setup Request except with multiple broadcast PLMN keys:
A lot of people think there’s a one-to-one relationship between a registration Address on Record, and a username.
That doesn’t have to be the case, there are some platforms that only allow a single registration for a single username, but the RFC itself allows multiple registrations for a single username.
REGISTER requests add, remove, and query bindings.
A REGISTER request can add a new binding between an address-of-record and one or more contact addresses.
Registration on behalf of a particular address-of-record can be performed by a suitably authorized third party.
A client can also remove previous bindings or query to determine which bindings are currently in place for an address-of-record.
Let’s say you’ve got a SIP phone on your desk at the office and at home.
What we could do is create a different username and password for home & work, and then setup some time based forward rules to ring the office from 9-5 and home outside of that.
You could register both with the same username and password, and then unplug the one at home before you leave to work, get to work, plug in your office phone, unplug it before you leave to go home, and when you get home plug back in your home phone, or if multi-device registration is supported, register both and have incoming calls ring on both.
Admittedly, platforms that support this are the exception, not the rule, but the RFC does allow it.
The other little known feature in SIP Registration is that you can query the SIP Registrar to get the list of Addresses on Record.
So there you go, factoids about SIP REGISTER method!
This series of post covers RF Planning using Forsk Atoll. We cover the basics of RF Planning in the process of learning how to use the software.
Forsk Atoll is software for RF Planning and Optimization of mobile networks.
We’ll start by creating a new document from template:
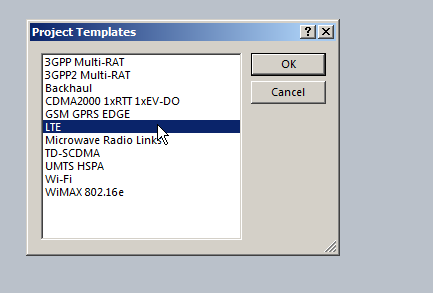
In our example we’re working with LTE, so, we’ll pick the LTE template.
(The templates setup the basic information on what we’re looking at, prediction models and defaults.)
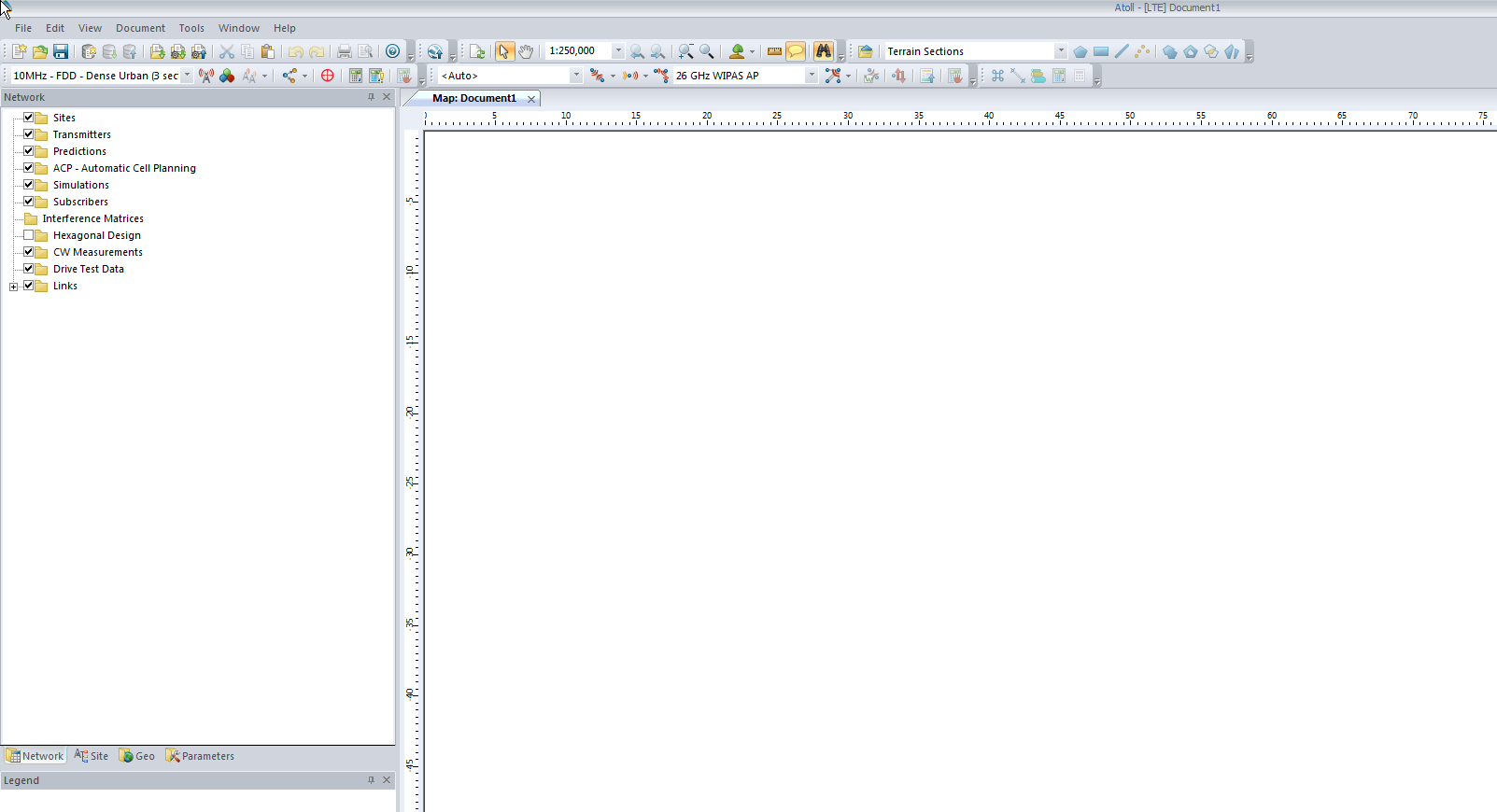
So now we’ll be looking at a blank white document, showing our map, with no data on it, Atoll doesn’t know if the area is hilly, heavily populated, densely treed, what we’re dealing with is a flat void with no features – “flatland” a perfect place to start.
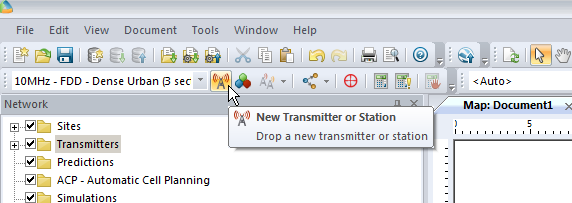
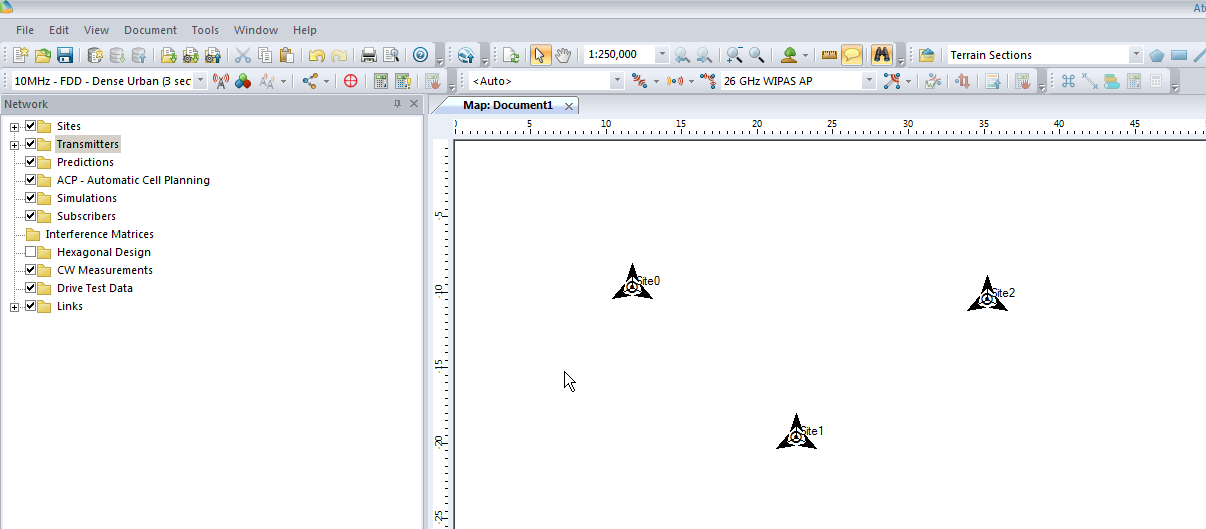
We’ll add an eNodeB (Transmitter Station and Site) from the top menu bar, clicking the transmitter icon to add a new Transmitter or Station.
Now we’ll click in the white of our map to place the transmitter site, and repeat this a few times.
Now we’ve added a few transmitter sites, let’s take a bit of a look at one.
If we take a closer look we’ll see it’s actually created us a 3 sector site, and each of the arrows coming from the site is a cell sector.
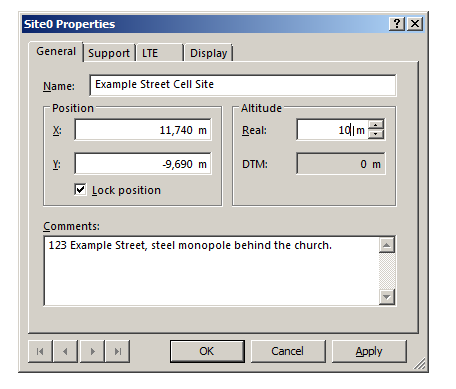
Double clicking on the transmitter will allow us to change the basic info about the site, such as it’s location, as well as display parameters, etc.
In the General tab I’ve renamed Site0 to “Example Street Cell Site”, given it an altitude (for the base of the site) and some comments,
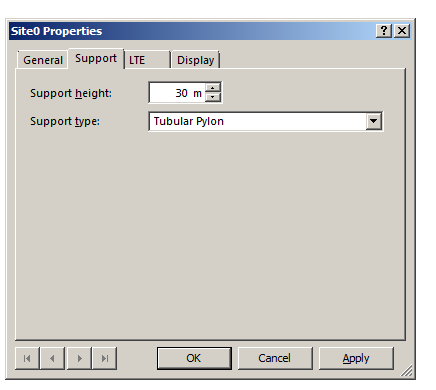
In the Support tab I’ve put some information about the support structure the antennas are one, in our case it’s on a 30m pylon / monopole.
In the LTE tab we can specify S1 throughput (backhaul) and in the Display tab we can set the color / icon used to display this site, but we’ll keep it simple for now and confirm these changes by pressing OK.
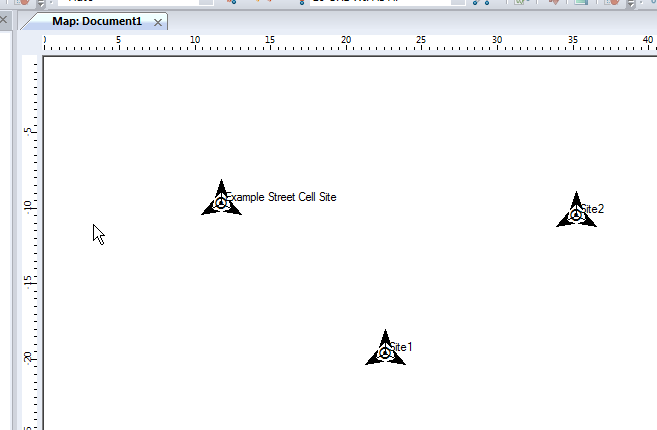
We can give each of our other Transmitters a bit of basic info, again, same process, double click on them and add some info:
So in my example I’ve got 3 transmitter sites, labeled and each given a bit of basic info. The main thing we need to have correct for each site is the location (In our case we’re placing them anywhere so it doesn’t matter), the height of the site (Altitude -Real) and the height of the structure (Support Height) the antennas are on.
Now we’ve got our 3 cell sites in our imaginary town devoid of any features, let’s get some coverage predictions for the inhabitants of desolate featureless town!
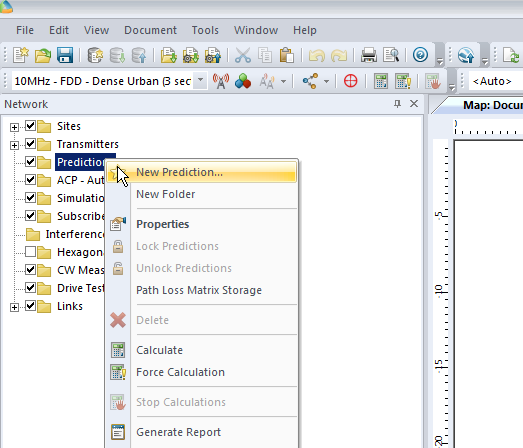
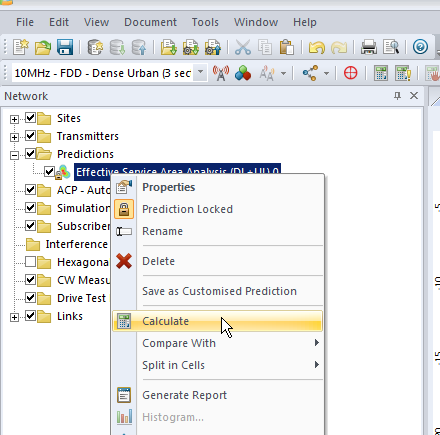
We’ll right click on Predictions and select “New Prediction”,
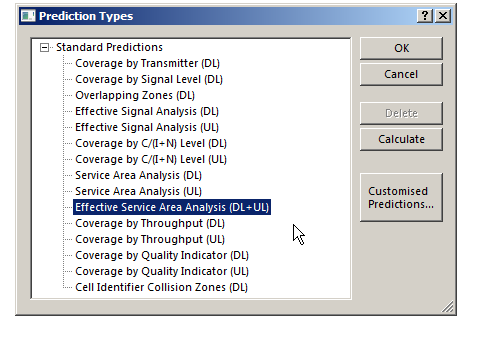
There’s a lot of different prediction types, but let’s look at the Effective Service Area Analysis for Uplink and Downlink from our eNodeBs.
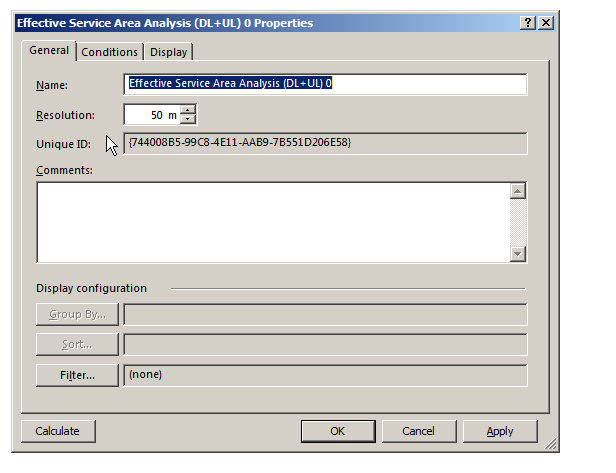
We’ll be asked to give this coverage prediction a name, and also specify a Resolution – The higher the resolution the more processing time but the higher the accuracy calculated.
At 50m it means Atoll will split the map into 50m squares and calculate the coverage in each square. This would be suitable for planning in really rural areas where you want a rough idea of footprint, but for In Building Coverage you’d want far more resolution, so you might want select 5m resolution say.
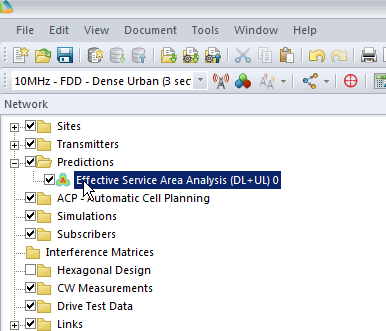
We’ll click Ok and now if we expand “Predictions” we’ll see our catchily named “Effective Service Area Analysis” there.
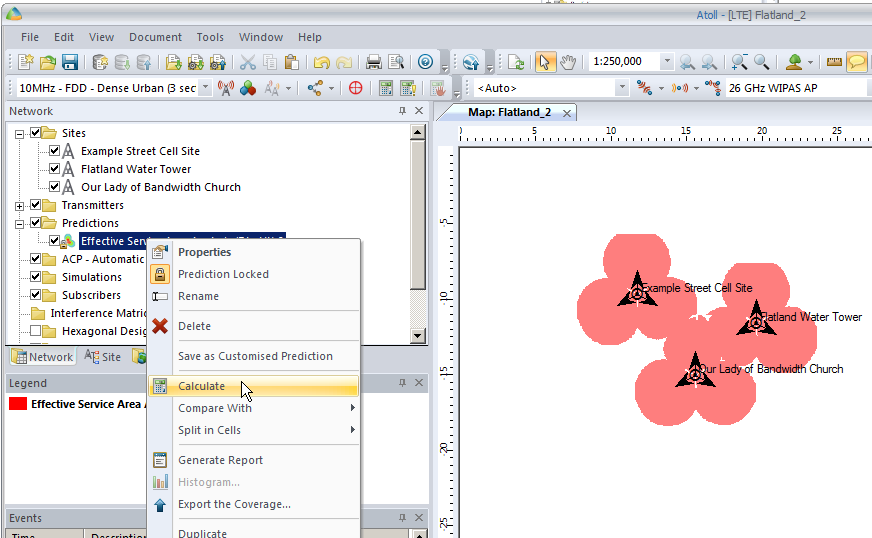
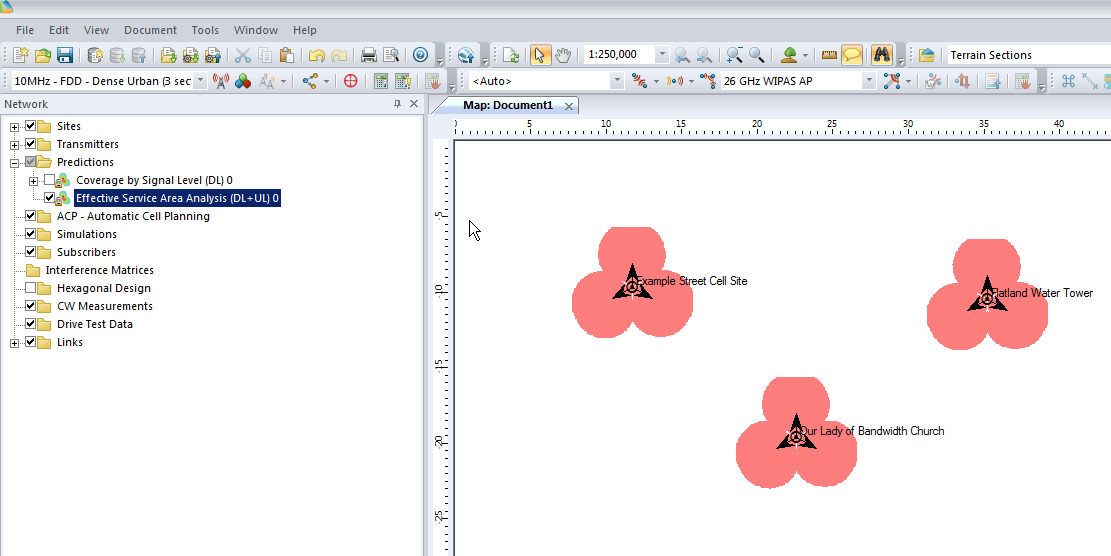
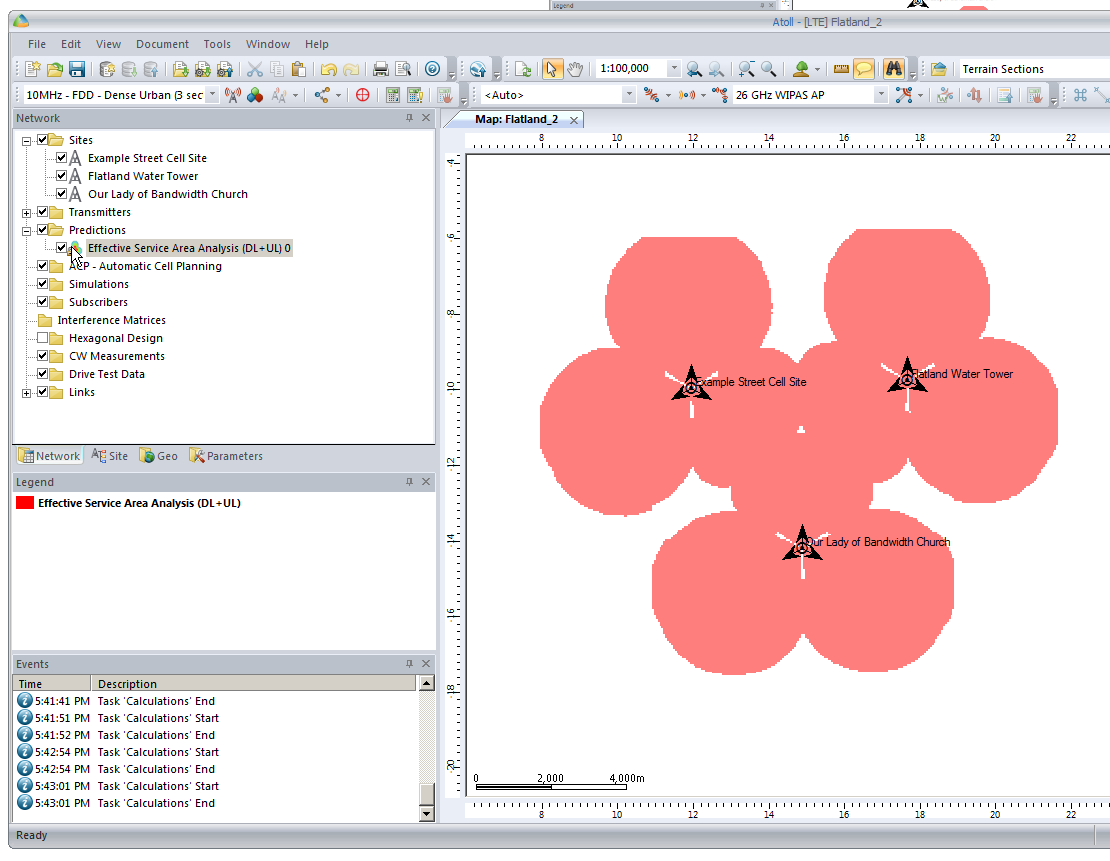
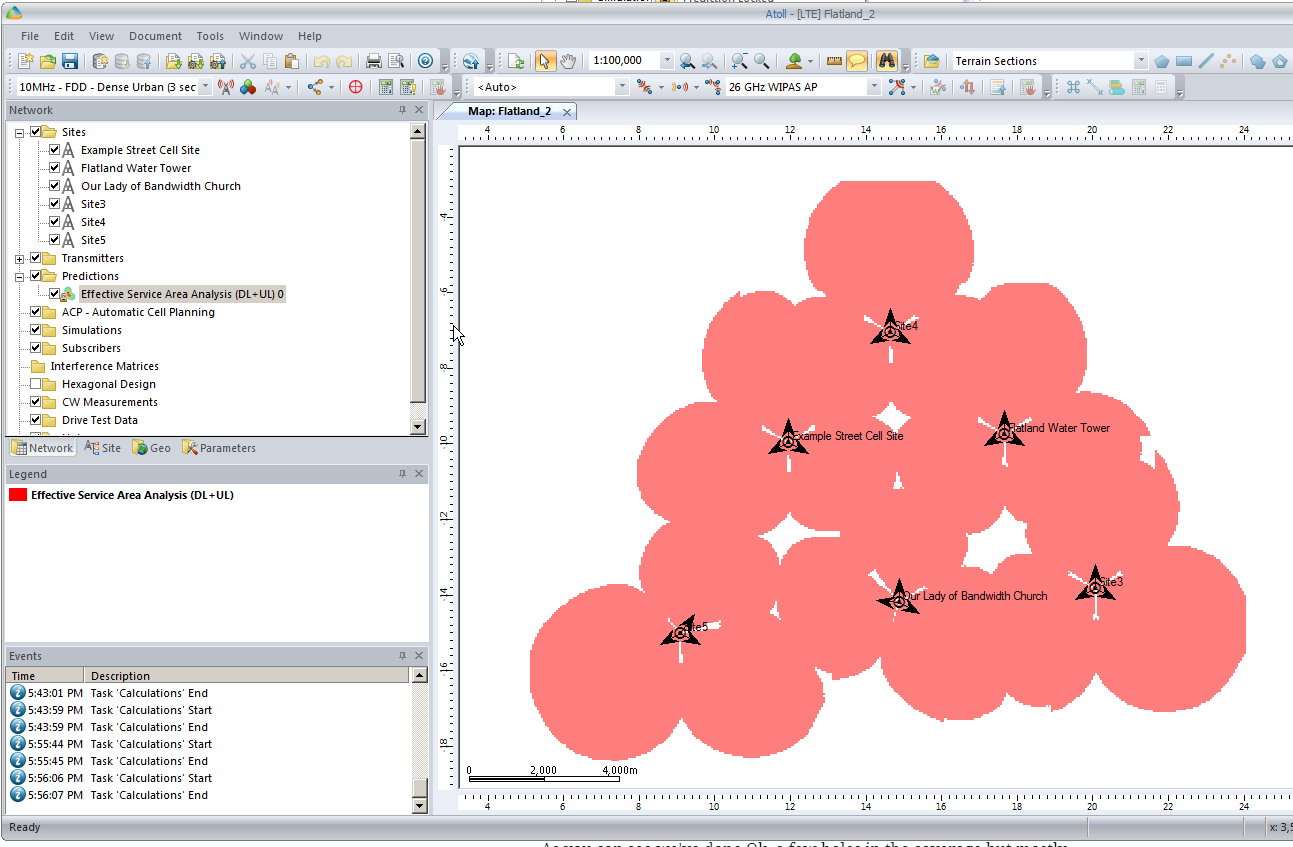
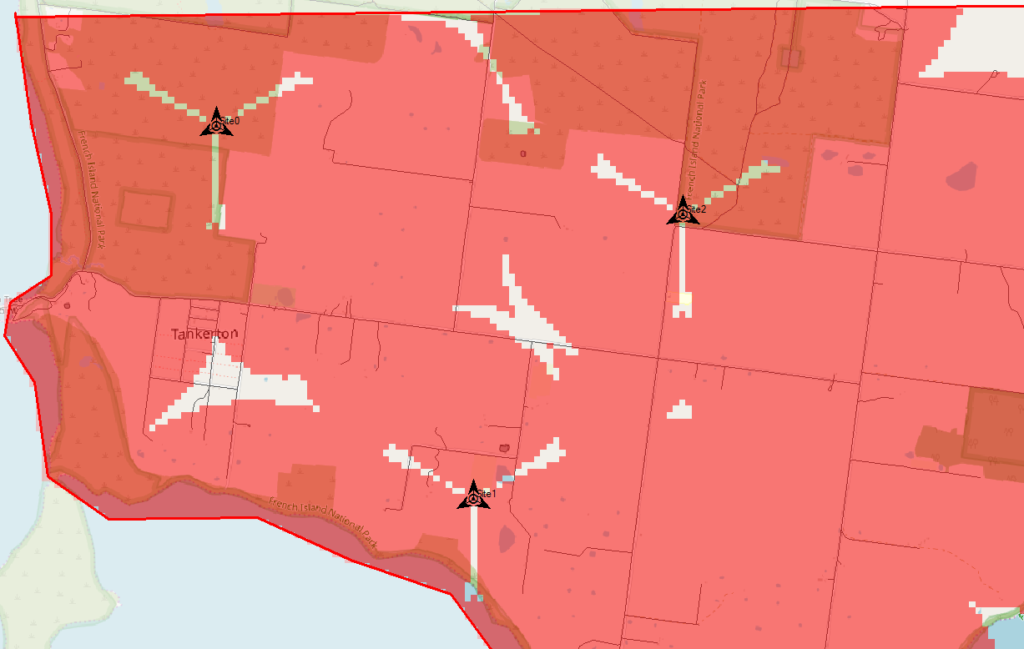
By right clicking on our prediction we can select “Calculate” and presto, we’ll have a prediction of service area from each of our cells,
Each of those pink cherry blobs represents the effective usable area of coverage provided by our network.
We may have some unhappy customers looking at this, our users will only be able to use their devices around Fake Street, Flatland Water Tower and the Our Lady of Bandwidth church.
But if we have a look at the scale in the bottom left of the screen that’s understandable, our sites are ~10km apart…
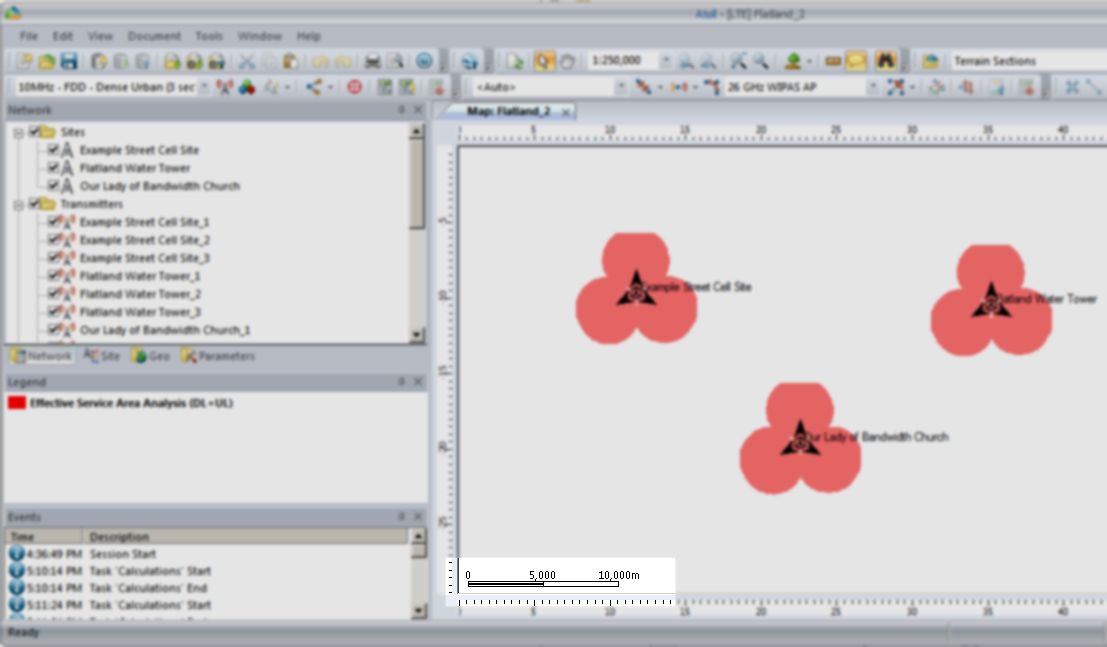
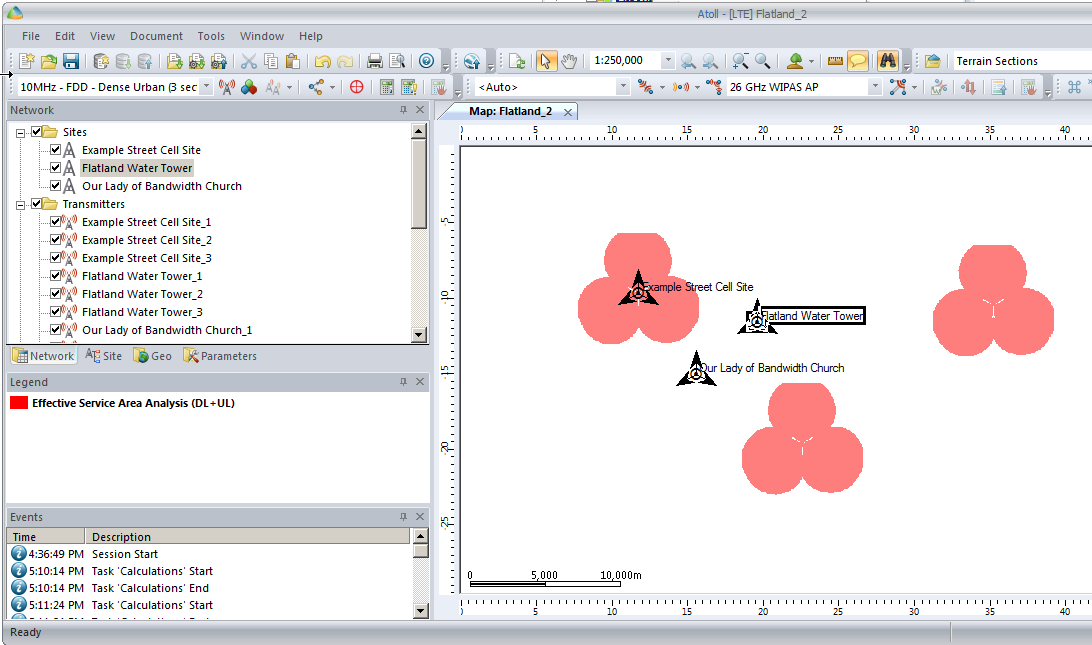
So let’s cheat a little by clicking and dragging on each cell site to bring them closer together, in real life we can’t move sites quite so easily…
You’ll notice our prediction hasn’t changed, so let’s recalculate that by right clicking on our Prediction and selecting Calculate again,
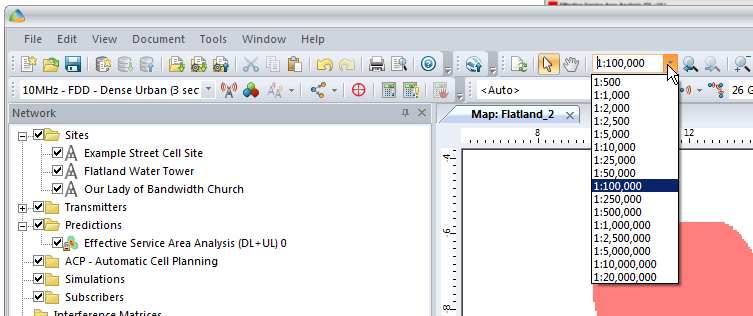
We’ll also set our zoom level from 1:250,000 to something a bit more reasonable like 1:100,000
So now our 3 sites have got one area fairly well covered, let’s throw in a few more sites to expand our footprint a bit.
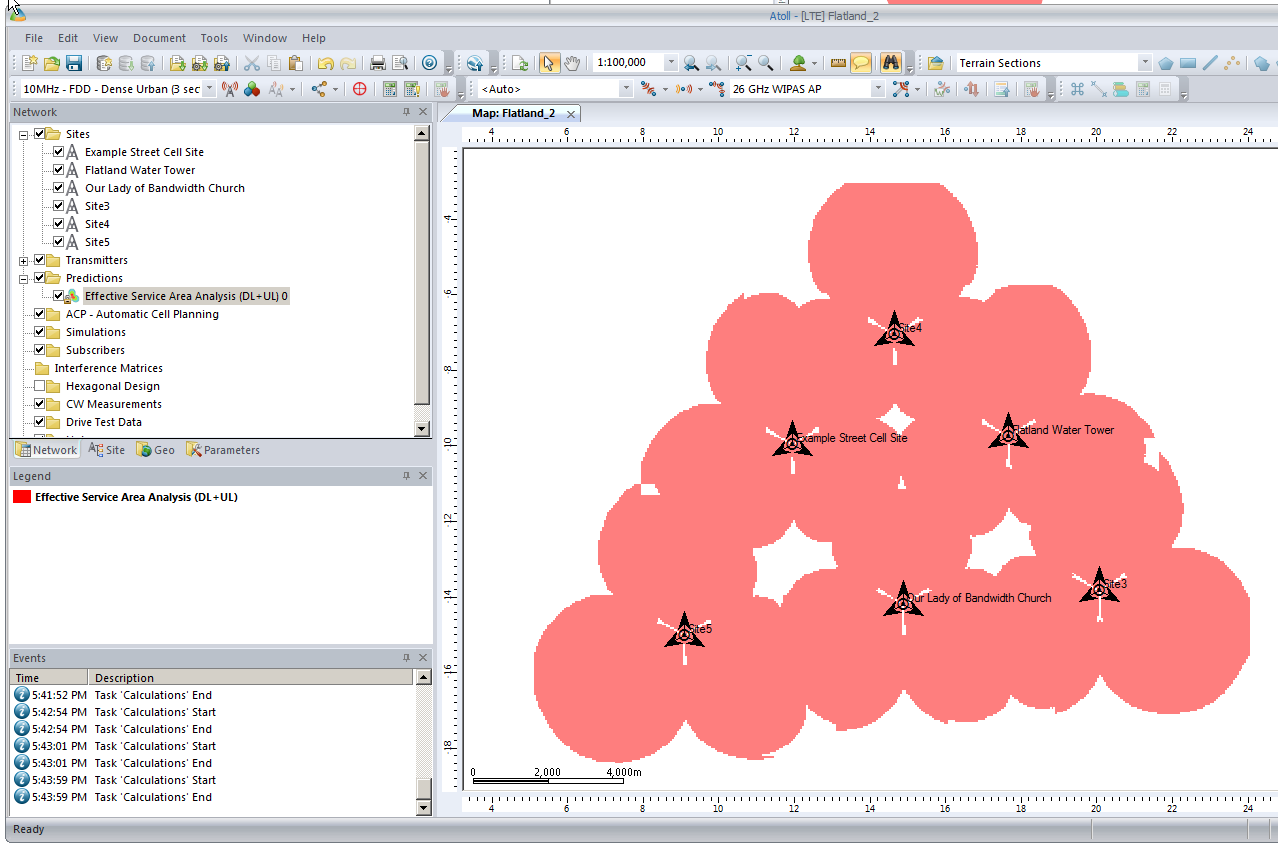
We’ll add extra sites as we did at the start, and fill in those coverage gaps.
After we’ve added some extra sites we’ll recalculate our Coverage Predictions and have a look at how we’ve done.
As you can see we’ve done Ok, a few holes in the coverage but mostly covered.
So next let’s do some tweaking to try and increase our predicted coverage,
By clicking on a site’s sector we can reorient the antenna to a different angle, by recalculating the coverage prediction we can see how this effects the predicted coverage.
By now you’ve probably got an idea of the basics of what we’re doing in Atoll, how changing the location, orientation and height of cells / sites affects the coverage, and how you can predict coverage.
In the upcoming posts we’ll cover adding real world data to Atoll so we can accurately model and predict how our RAN will perform.
We’ll look at how we can use Automatic Cell Planning to get the most optimal setup in terms of power settings, antenna orientations and tilts, etc for our existing sites.
We’ll be able to simulate subscribers, traffic flow, backhaul, and model our network all before a single truck rolls.
So stick around, the next post will be coming soon and will cover adding environment data.
In our last post we talked about getting our geospatial data right, and in our first post we covered the basics of adding sites and transmitters.
There’s a bit of a chicken-and-egg problem with site placement, antenna orientation, type and down-tilt.
If all our sites were populated and in place, we could look at optimizing coverage by changing azimuths / orientations, plug in our data and run some predictions / modeling and coming up with some solutions. Likewise if we’ve already done that we might want to calculate ideal down-tilt angles to get the most out of network.
But we’ve got no sites, no transmitters and no coverage predictions yet, so we’re probably going to need to ask ourselves a more basic, but harder question: Where will we put the cell sites?
To keep this easy we’ll focus on providing the South Western corner of the Island, a town called Tankerton, with only 3 cell sites.
Manual Site Selection
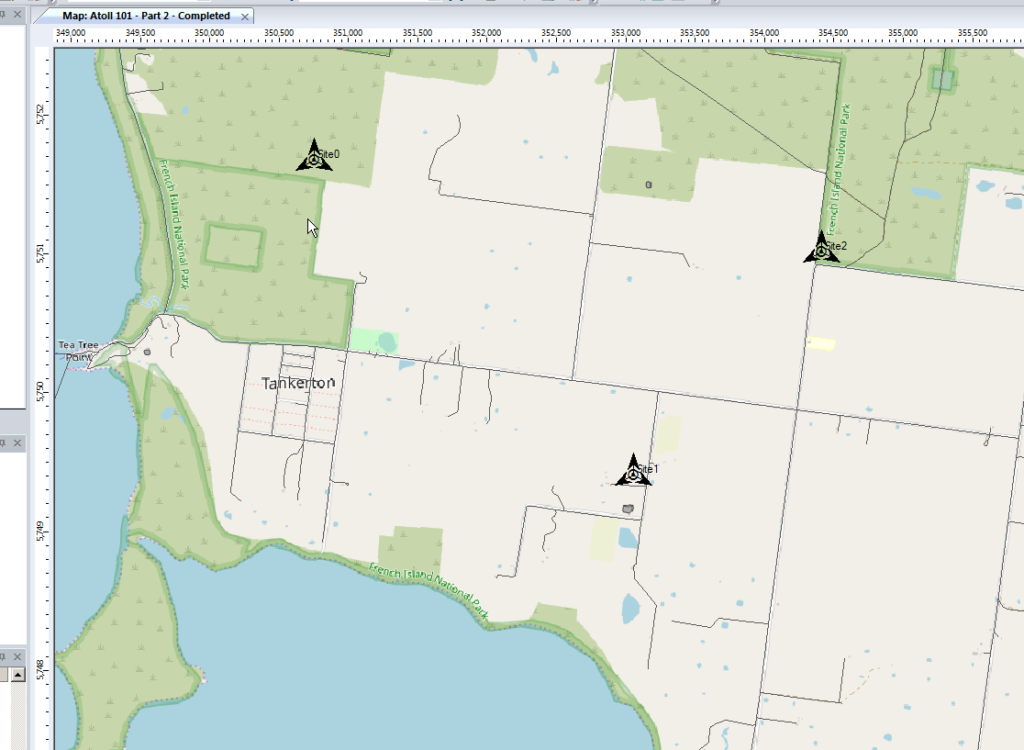
In the very first post we put up a few sites, we’ll do the same, let’s place 3 sites in the bottom right of the island and attempt to provide contiguous coverage for the town with them;
We’ll pick our Station Template and set it to FDD Rural as this is pretty remote.
Next we’ll add some sites and transmitters:
Click to place it on the map and add our cell sites;
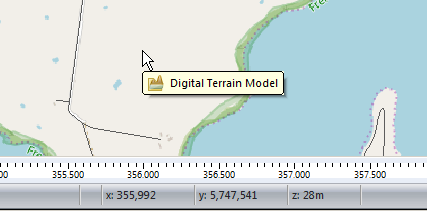
When we’re looking at where to place it, it’s good to remember that height (elevation) is good (To an extent), so when looking at where to place sites, keep an eye on the Z (Height) value in the bottom right, and try and pick sites with a good elevation.
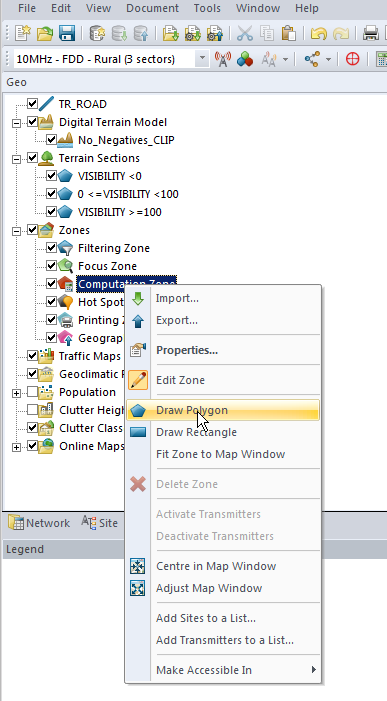
Setting Computation Zone
As we’re only focusing on a small part of the island we’ll set a Computation Zone to limit the calculations / computations Atoll has to do to a set region.
I’ve chosen to draw a Polygon around the area, but you could also just get away with drawing a Rectangle, around the area we’re interested in.
This just constrains everything so we’re only crunching numbers inside that area.
Predictions
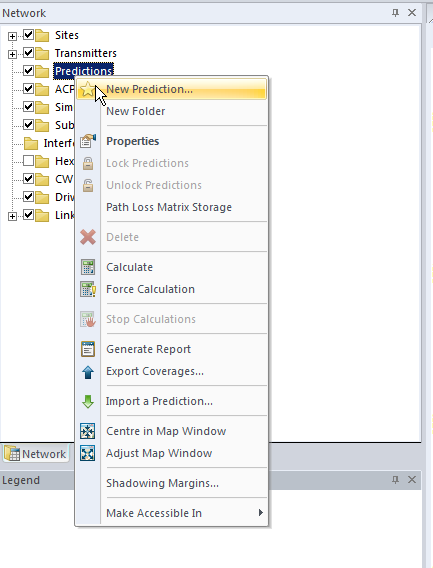
So now we’ve put our 3 sites out & constrained to the Tankerton area, let’s see how much of the area we’ve covered, we’ll jump to the Network tab, right click on Predictions and select New Prediction
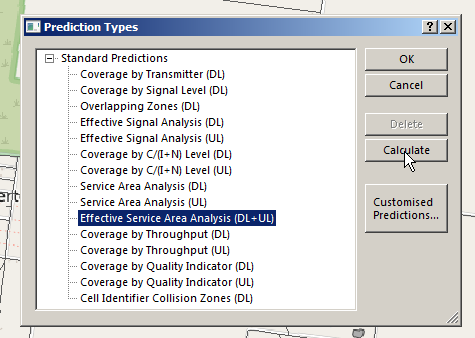
There’s a lot of predictions we can run, but we’ll go simple and select Effective Service Area Analysis (UL + DL) & click Calculate
Atoll will crunch the numbers and give us a simple overlay, showing the areas with and without coverage.
The areas in red are predicted to have coverage, and the areas with no shading will be our blackspots / “notspots”.
We’ve covered most of the area, but we can improve.
Manually Tweaking Attributes
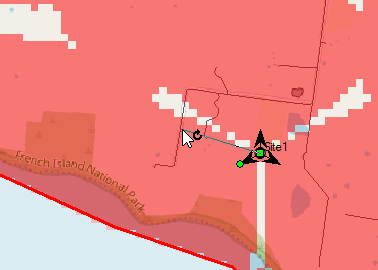
So there’s still some holes in our coverage, so let’s adjust the azimuth of some of the antennas and see if we can fill them.
Click on each of the arrows on the site, each of these represents an antenna / cell and we can change the angles.
So after a bit of fiddling I think I’ve got a better antenna azimuth for each of the sectors on each of my 3 sites.
Let’s compare that to what we had before to see if we’ve made it better or worse,
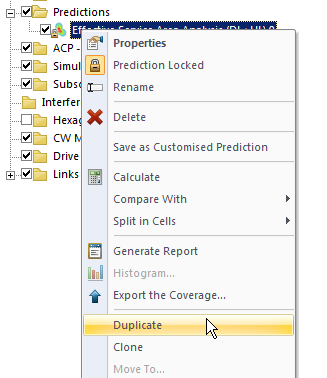
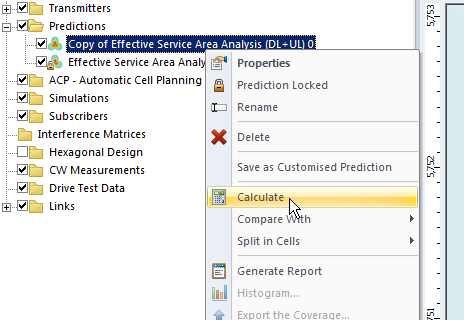
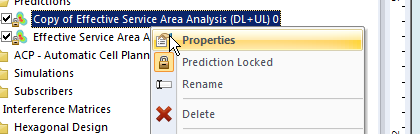
We’ll Duplicate the Effective Service Area Analysis prediction we created before & calculate it.
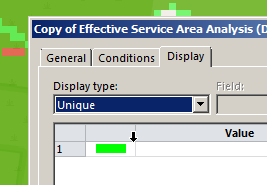
To make viewing a bit easier we’ll edit the properties of the copy and set it to a different colour:
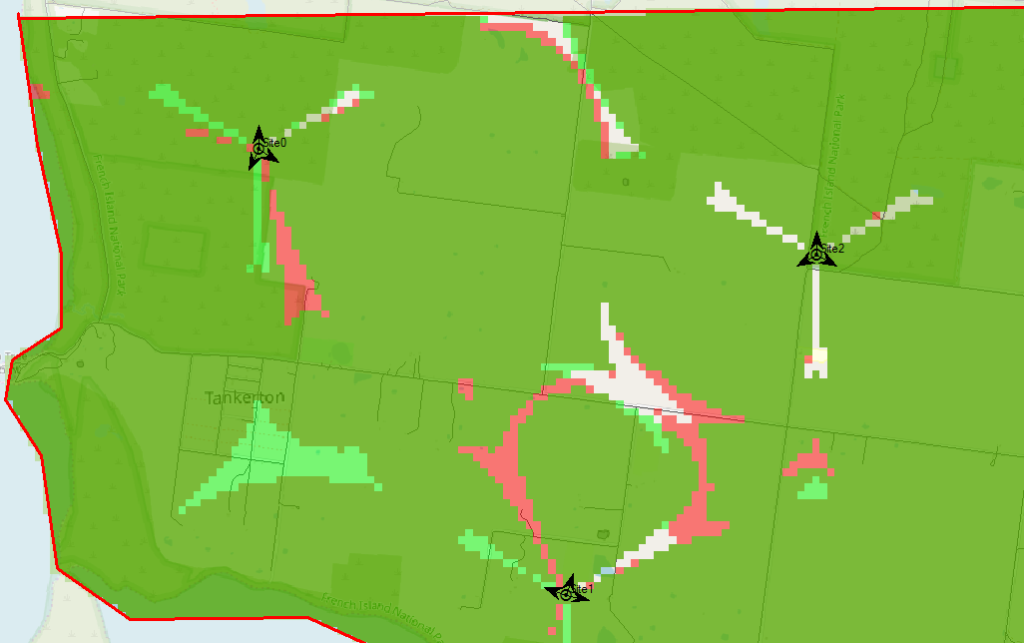
Now I can see at a glance how much better we’re looking;
The obvious problem here is I could tweak and tweak and improve some things, make others worse, and we’d be here forever.
Luckily Atoll can do a better job of fiddling with each parameter for us and selecting the configuration that leads to the best performance in our RAN.
Automatic Cell Planning
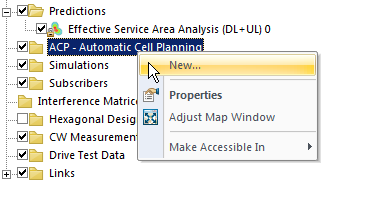
Enter Automatic Cell Planning, to adjust the parameters we set to find the most optimal setup,
We’ll right click on ACP – Automatic Cell Planning and create a new one.
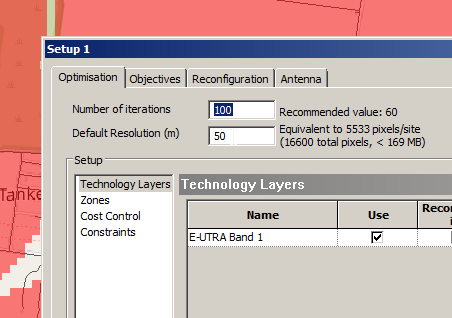
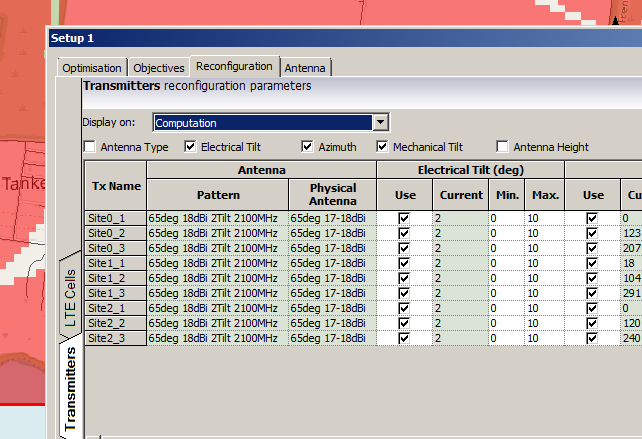
From here we set how many iterations we want to try out (more leads to better results but takes longer to compute), the parameters we want to change (ie Azimuth, Tilt, Antenna type, etc).
Setting number of iterations – Higher leads to better results but takes longer to calculate and has diminishing returnsWe’ll allow the Tilt (Electrical & Mechanical) to be adjusted as well as the Azimuth of each antenna.
When you’ve set the parameters you want, click Run and Atoll will start running through possible parameter combinations and measuring how they perform.
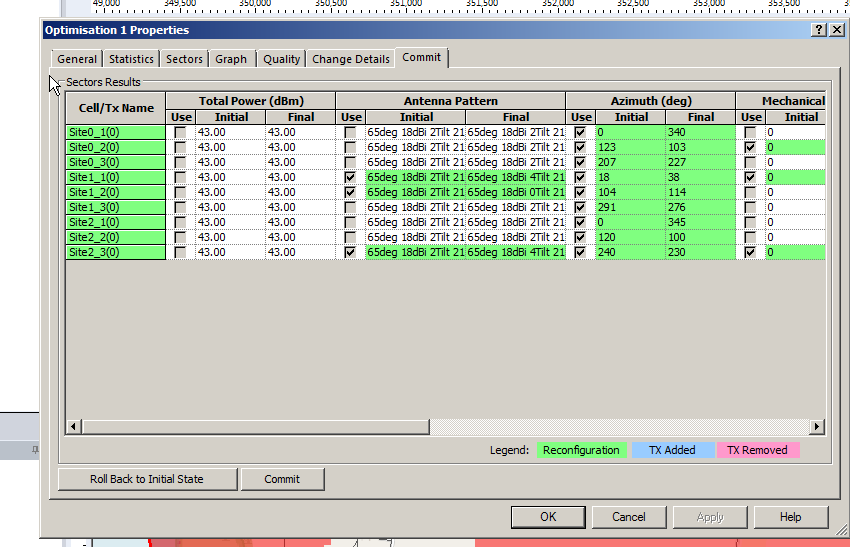
Once it’s run you’ll be able to view the Optomization
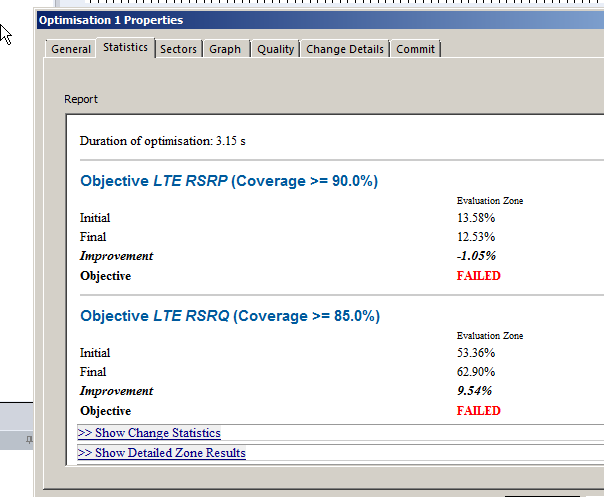
The report shows you the results, improvements in RSSI and RSSQ;
Here we can see we boosted the RSRQ (The quality of the signal) by 9.5%, but had to sacrifice RSRP (Signal power) by 1%.
Sacrificies have to be made, and if you’re happy with this you can view the details of the changes, and commit the adjustments.
Committing the changes adjusts all the Transmitters in the area to the listed values, after which we can run our Predictions again to compare like we did earlier.
So that’s what we’ve got when we randomly place sites, we can use Atoll to optomize what we’ve already got, but what if we left the picking of cell sites up to Atoll to look for better options?
In our next post we’ll look at Site Selection using ACP, and constraining it. This means we can tell Atoll to just find the best sites, or load in a list of possible sites and let Atoll determine which are the best candidates.
You’ve done the flatland model we did Part 1 and now you’re pumped up and ready to start plotting your cell sites, optimizing your coverage and boosting the services you’re offering.
But one thing stands in your way – The predicted & modeled data we get out of Atoll is only going to be as good as the data we’ve given it, the old garbage in garbage out adage.
So let’s get started, we’ll create a new document from Template again and select LTE.
Setting our Projection
Now before we go throwing out cell sites we’re going to have to tell Atoll where we are, this can get a little tricky if you’re setting this up for a different real world location, but stick with me and I’ll give you the data you need for this example.
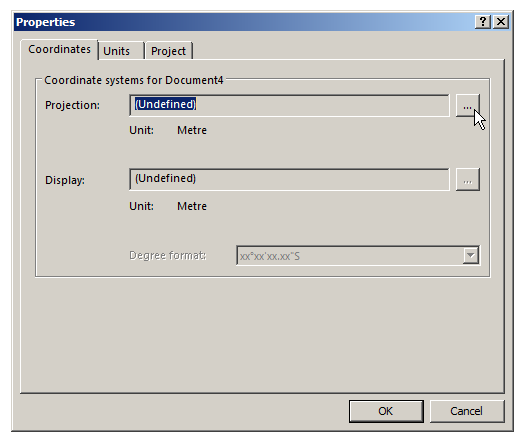
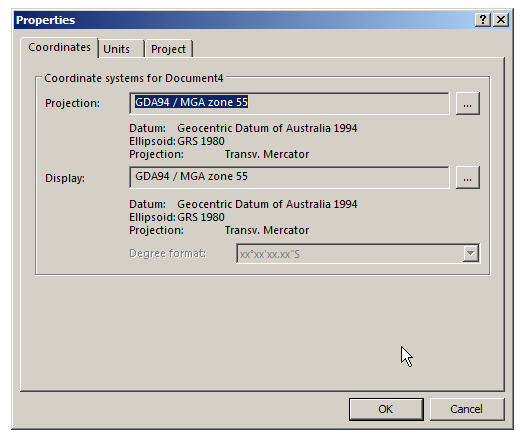
We’ll select Document -> Properties and we’ve got to define a projection,
A projection is essentially a coordinate system, like Latitude and Longitude, that constrains our project to somewhere on this planet.
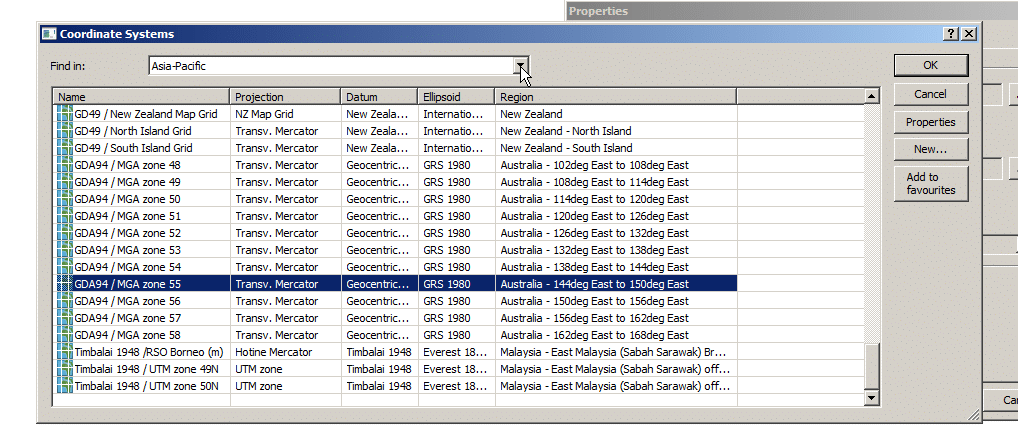
In this example we’re in Australia, so we’ll select Asia Pacific from the “Find In” section and scroll until we find MGA Zone 55. We’ll select it and click OK.
All this Zone information makes sense to GIS folks, there’s lots of information online about UTM datums, projections and GIS, which can help you select the right Coordinate system and projection for your particular area – But for us we’ll select MGA Zone 55 and that’s the last we’ll hear about it.
So now we’ve got that information setup we’ll hit Ok again and be on our way. Atoll now knows where in the world we are and we can start filling in the specifics.
So now we’ve still got an empty map with nothing to show, so let’s add some data.
Adding Population and Roads
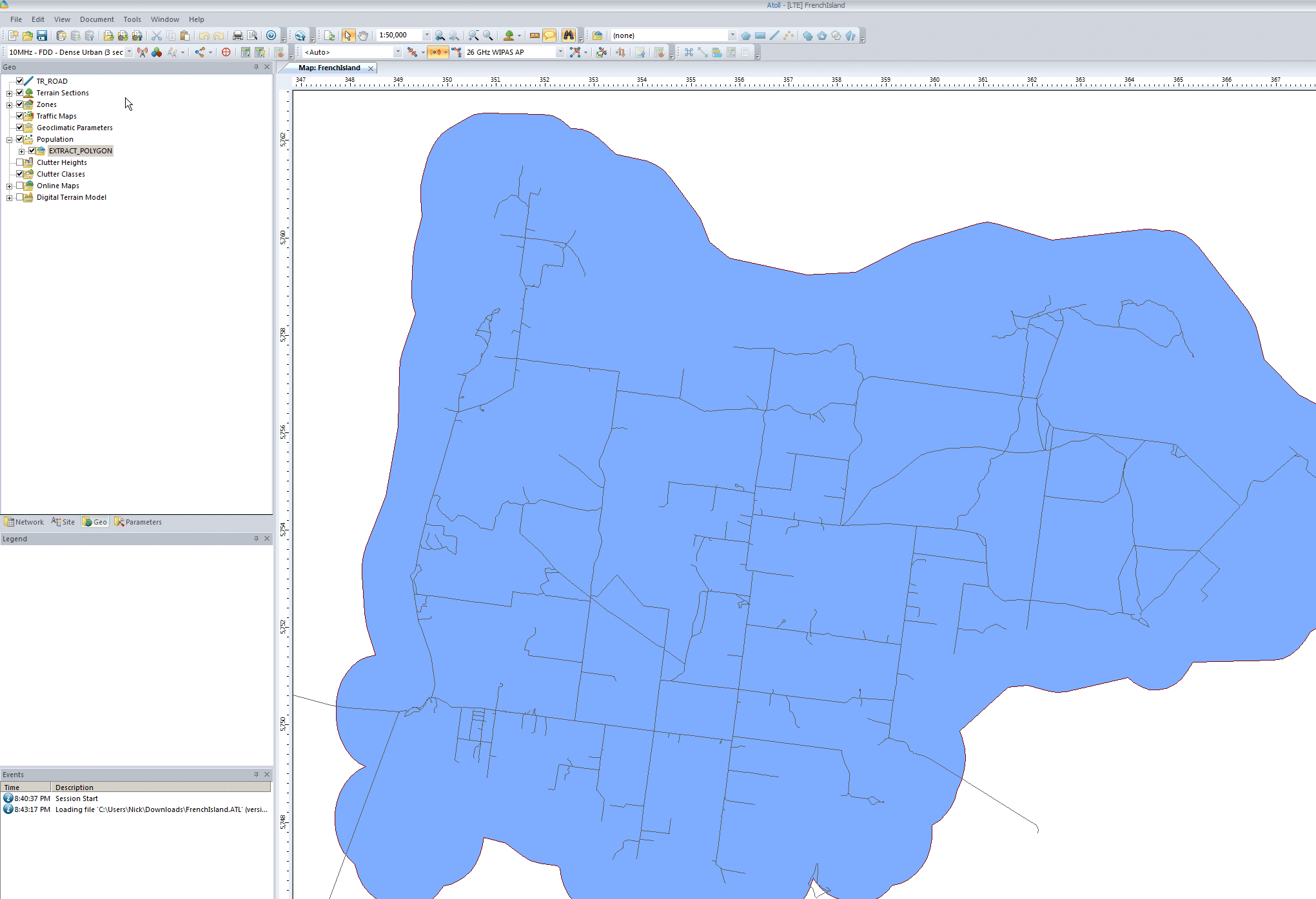
We’ll start by adding some base data, we’ll import a footprint of the Island and a map of all the roads.
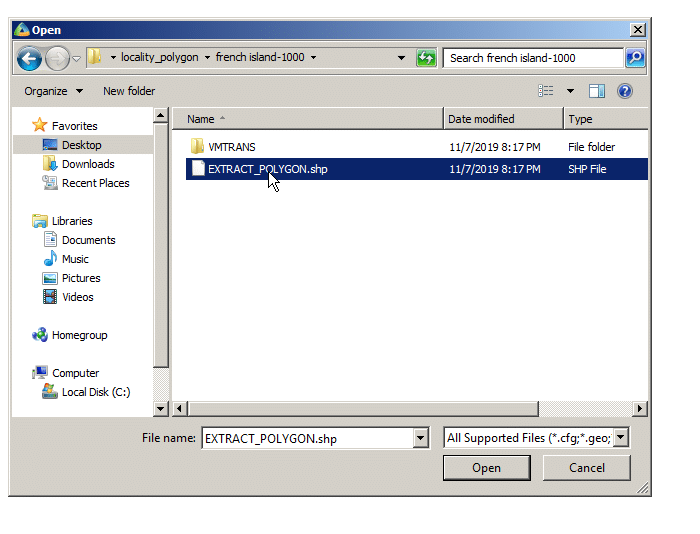
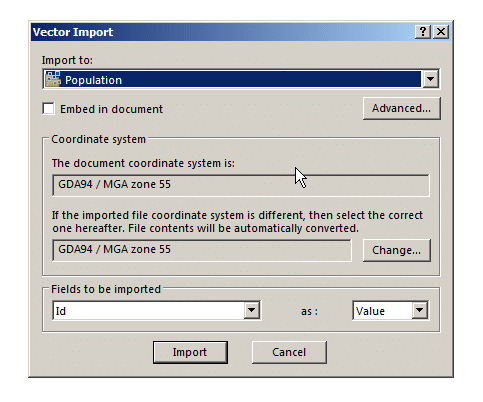
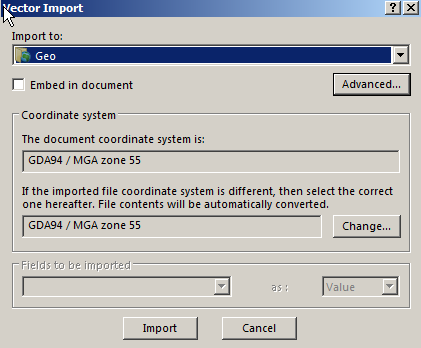
First we’ll import the populated area outline it into Atoll from File -> Import and select the file called EXTRACT_POLYGON.shp
We’ll put it into the population folder, this will be useful later when we try and ensure this area is covered by our network.
Although the population data is kind of rough ( <100 for the entire area) it’s still very useful for limiting our coverage area and saying “We’ve got everyone covered” when it comes to coverage.
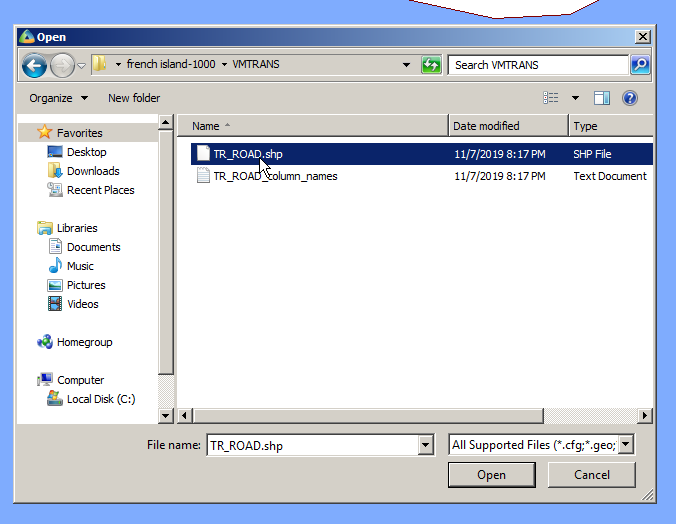
Next up we’ll import the roads file, same thing, File -> Import, TR_ROAD.shp
We’ll import it to the Geo folder – This is just data that Atoll doesn’t process but is useful to us as humans.
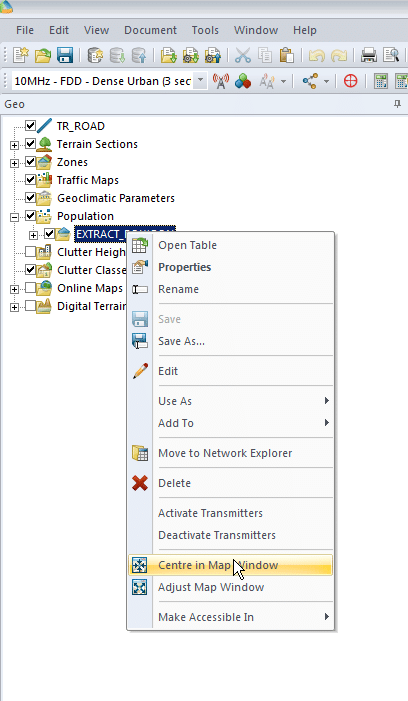
Finally we’ll enable the layers we’ve just imported and center the map on our imported data to get us in the right region. We’ll do this by expanding “Population”, right clicking on the file we just imported and selecting “Center in Map Window”
You may have to tick the layer to enable itPopulation footprint with roads
Adding Elevation Data
Again, like our Datum elevation data is a standard GIS concept, but if you’re from an RF background you’ve probably not come across it, essentially it’s an image where the shade of each pixel translates to a height above sea level.
We import it into Atoll and it’s used in propagation modeling – after all we need to know if there’s a hill / mountain / valley in the way, and even slight rises / dips in the geography can have an impact on your coverage.
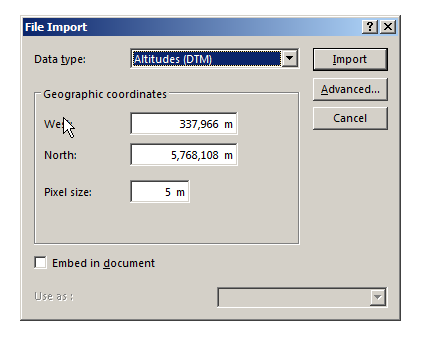
We’ll start by downloading the file above, and then importing it into Atoll
Next we’ll need to tell Atoll the type of data we’re importing (Altitudes) and it’s offset from the 0 point of our coordinate system, I’ve put the information we need for this into a handy table below:
West
337,966
North
5,768,108
Pixel Size
5m
Now when we move our cursor around we’ll see the elevation change in the bottom right ( z is height).
This is because the elevation data is kind of invisible (We’re looking top down) but it’s there.
Adding a Map Overlay
Ok, you’ve made it this far, let’s finally get out of our white blank map and give it some things that make it look like a map!
In order to add Google Maps / Bing Maps etc as an overlay for the first time, we’ve got to restart Atoll, be sure to save your work first.
Done that? Good, let’s add some map tiles.
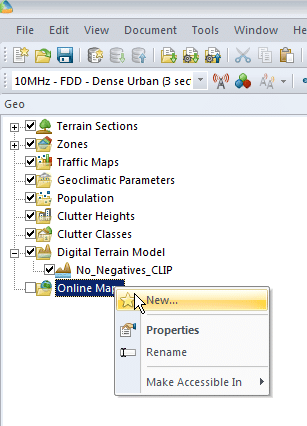
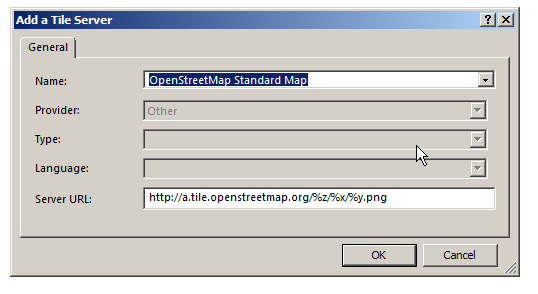
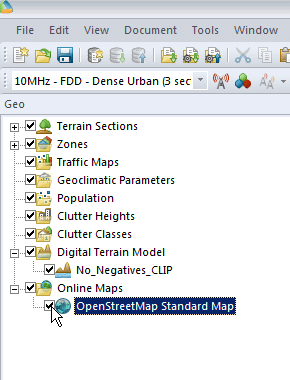
We’ll right click on Online Maps -> New and select a map source from the drop down menu,
Next we’ll select a tile server, I’m using Open Street Map Standard Map, which I selected from the drop down menu,
Finally we’ll enable the layer by ticking it on the Geo panel on the right hand side. You may need to drag the layer to the top if you’ve added other layers.
All going well you’ll be looking at a map of the area, and by hovering over an area of land you should see the elevation data too.
We can even add other map layers and toggle between them or set the order by dragging them up and down.
Summary
So now we’ve got Atoll configured for our part of the world, imported height data, population data and roads, and added some map layers so we can see what we’re up to.
An important point to keep in mind is the more accurate the data you feed into Atoll, the more real-world the results you’ll get out of it will be.
Although filling in map layers and adding information seems tedious – and it is – the data-in data-out approach applies here, so the more quality data we put in the better.
If you’re doing this yourself in the real world contact your Government, they often publish large amounts of geospatial data like elevation, population, roads, land boundaries, and it’s often free.
I’ve attached my working file for you to play with in case you had any issues.
Today I thought I’d cover a simple use case – running an HTTP get from Kamailio and doing something with the output.
The http_client does what it sounds – Acts as an HTTP client to send HTTP GET and POST requests.
The use cases for this become clear quite quickly, you could use http_client to request credit from an accounting server via it’s API, get the latest rate to a destination from a supplier, pull weather data, etc, etc.
Let’s take a very simple example, we’ll load http_client by adding a loadmodule line:
...
loadmodule "http_client.so"
...
Next I’ve put together a very simple request_route block that requests a HTTP file from a web server and sends the response to a SIP client:
####### Routing Logic ########
/* Main SIP request routing logic
* - processing of any incoming SIP request starts with this route
* - note: this is the same as route { ... } */
request_route {
xlog("Got request");
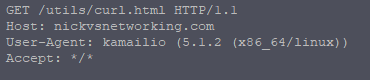
http_client_query("https://nickvsnetworking.com/utils/curl.html", "", "$var(result)");
xlog("Result is $var(result)");
sl_reply("200", "Result from HTTP server was $var(result)");
}
Using the http_client_query() function we’re able to query a HTTP server,
We’ll query the URL https://nickvsnetworking.com/utils/curl.html and store the output to a variable called result.
If you visit the URL you’ll just get a message that says “Hello there“, that’s what Kamailio will get when it runs the http_client function.
Next we print the result using an xlog() function so we can see the result in syslog,
Finally we send a stateless reply with the result code 200 and the body set to the result we got back from the server.
We can make this a bit more advanced, using HTTP Post we can send user variables and get back responses.
The http_client module is based on the ubiquitous cURL tool, that many users will already be familiar with.
There’s always lots of talk of Network Function Virtualization (NFV) in the Telco space, but replacing custom hardware with computing resources is only going to get you so far, if every machine has to be configured manually.
Ansible is a topic I’ve written a little bit about in terms of network automation / orchestration.
I wanted to test limits of Open5gs EPC, which led me to creating a lot of Packet Gateways, so I thought I’d share a little Ansible Playbook I wrote for deploying P-GWs.
It dynamically sets the binding address and DHCP servers, and points to each PCRF in the defined pool.
You can obviously build upon this too, creating another playbook to deploy PCRFs, MMEs and S-GWs will allow you to reference the hosts in each group to populate the references.
logger:
file: /var/log/open5gs/pgw.log
parameter:
pgw:
freeDiameter: /etc/freeDiameter/pgw.conf
gtpc:
- addr: {{hostvars[inventory_hostname]['ansible_default_ipv4']['address']}}
gtpu:
- addr: {{hostvars[inventory_hostname]['ansible_default_ipv4']['address']}}
ue_pool:
- addr: 45.45.0.1/16
- addr: cafe::1/64
dns:
{% for dns in dns_servers %}
- {{ dns }}
{% endfor %}
Diameter Config (pgw.conf.j2)
# This is a sample configuration file for freeDiameter daemon.
# Most of the options can be omitted, as they default to reasonable values.
# Only TLS-related options must be configured properly in usual setups.
# It is possible to use "include" keyword to import additional files
# e.g.: include "/etc/freeDiameter.d/*.conf"
# This is exactly equivalent as copy & paste the content of the included file(s)
# where the "include" keyword is found.
##############################################################
## Peer identity and realm
# The Diameter Identity of this daemon.
# This must be a valid FQDN that resolves to the local host.
# Default: hostname's FQDN
#Identity = "aaa.koganei.freediameter.net";
Identity = "{{ inventory_hostname }}.{{ diameter_realm }}";
# The Diameter Realm of this daemon.
# Default: the domain part of Identity (after the first dot).
#Realm = "koganei.freediameter.net";
Realm = "{{ diameter_realm }}";
##############################################################
## Transport protocol configuration
# The port this peer is listening on for incoming connections (TCP and SCTP).
# Default: 3868. Use 0 to disable.
#Port = 3868;
# The port this peer is listening on for incoming TLS-protected connections (TCP and SCTP).
# See TLS_old_method for more information about TLS flavours.
# Note: we use TLS/SCTP instead of DTLS/SCTP at the moment. This will change in future version of freeDiameter.
# Default: 5868. Use 0 to disable.
#SecPort = 5868;
# Use RFC3588 method for TLS protection, where TLS is negociated after CER/CEA exchange is completed
# on the unsecure connection. The alternative is RFC6733 mechanism, where TLS protects also the
# CER/CEA exchange on a dedicated secure port.
# This parameter only affects outgoing connections.
# The setting can be also defined per-peer (see Peers configuration section).
# Default: use RFC6733 method with separate port for TLS.
#TLS_old_method;
# Disable use of TCP protocol (only listen and connect over SCTP)
# Default : TCP enabled
#No_TCP;
# Disable use of SCTP protocol (only listen and connect over TCP)
# Default : SCTP enabled
#No_SCTP;
# This option is ignored if freeDiameter is compiled with DISABLE_SCTP option.
# Prefer TCP instead of SCTP for establishing new connections.
# This setting may be overwritten per peer in peer configuration blocs.
# Default : SCTP is attempted first.
#Prefer_TCP;
# Default number of streams per SCTP associations.
# This setting may be overwritten per peer basis.
# Default : 30 streams
#SCTP_streams = 30;
##############################################################
## Endpoint configuration
# Disable use of IP addresses (only IPv6)
# Default : IP enabled
#No_IP;
# Disable use of IPv6 addresses (only IP)
# Default : IPv6 enabled
#No_IPv6;
# Specify local addresses the server must bind to
# Default : listen on all addresses available.
#ListenOn = "202.249.37.5";
#ListenOn = "2001:200:903:2::202:1";
#ListenOn = "fe80::21c:5ff:fe98:7d62%eth0";
ListenOn = "{{hostvars[inventory_hostname]['ansible_default_ipv4']['address']}}";
##############################################################
## Server configuration
# How many Diameter peers are allowed to be connecting at the same time ?
# This parameter limits the number of incoming connections from the time
# the connection is accepted until the first CER is received.
# Default: 5 unidentified clients in paralel.
#ThreadsPerServer = 5;
##############################################################
## TLS Configuration
# TLS is managed by the GNUTLS library in the freeDiameter daemon.
# You may find more information about parameters and special behaviors
# in the relevant documentation.
# http://www.gnu.org/software/gnutls/manual/
# Credentials of the local peer
# The X509 certificate and private key file to use for the local peer.
# The files must contain PKCS-1 encoded RSA key, in PEM format.
# (These parameters are passed to gnutls_certificate_set_x509_key_file function)
# Default : NO DEFAULT
#TLS_Cred = "<x509 certif file.PEM>" , "<x509 private key file.PEM>";
#TLS_Cred = "/etc/ssl/certs/freeDiameter.pem", "/etc/ssl/private/freeDiameter.key";
TLS_Cred = "/etc/freeDiameter/pgw.cert.pem", "/etc/freeDiameter/pgw.key.pem";
# Certificate authority / trust anchors
# The file containing the list of trusted Certificate Authorities (PEM list)
# (This parameter is passed to gnutls_certificate_set_x509_trust_file function)
# The directive can appear several times to specify several files.
# Default : GNUTLS default behavior
#TLS_CA = "<file.PEM>";
TLS_CA = "/etc/freeDiameter/cacert.pem";
# Certificate Revocation List file
# The information about revoked certificates.
# The file contains a list of trusted CRLs in PEM format. They should have been verified before.
# (This parameter is passed to gnutls_certificate_set_x509_crl_file function)
# Note: openssl CRL format might have interoperability issue with GNUTLS format.
# Default : GNUTLS default behavior
#TLS_CRL = "<file.PEM>";
# GNU TLS Priority string
# This string allows to configure the behavior of GNUTLS key exchanges
# algorithms. See gnutls_priority_init function documentation for information.
# You should also refer to the Diameter required TLS support here:
# http://tools.ietf.org/html/rfc6733#section-13.1
# Default : "NORMAL"
# Example: TLS_Prio = "NONE:+VERS-TLS1.1:+AES-128-CBC:+RSA:+SHA1:+COMP-NULL";
#TLS_Prio = "NORMAL";
# Diffie-Hellman parameters size
# Set the number of bits for generated DH parameters
# Valid value should be 768, 1024, 2048, 3072 or 4096.
# (This parameter is passed to gnutls_dh_params_generate2 function,
# it usually should match RSA key size)
# Default : 1024
#TLS_DH_Bits = 1024;
# Alternatively, you can specify a file to load the PKCS#3 encoded
# DH parameters directly from. This accelerates the daemon start
# but is slightly less secure. If this file is provided, the
# TLS_DH_Bits parameters has no effect.
# Default : no default.
#TLS_DH_File = "<file.PEM>";
##############################################################
## Timers configuration
# The Tc timer of this peer.
# It is the delay before a new attempt is made to reconnect a disconnected peer.
# The value is expressed in seconds. The recommended value is 30 seconds.
# Default: 30
#TcTimer = 30;
# The Tw timer of this peer.
# It is the delay before a watchdog message is sent, as described in RFC 3539.
# The value is expressed in seconds. The default value is 30 seconds. Value must
# be greater or equal to 6 seconds. See details in the RFC.
# Default: 30
#TwTimer = 30;
##############################################################
## Applications configuration
# Disable the relaying of Diameter messages?
# For messages not handled locally, the default behavior is to forward the
# message to another peer if any is available, according to the routing
# algorithms. In addition the "0xffffff" application is advertised in CER/CEA
# exchanges.
# Default: Relaying is enabled.
#NoRelay;
# Number of server threads that can handle incoming messages at the same time.
# Default: 4
#AppServThreads = 4;
# Other applications are configured by loaded extensions.
##############################################################
## Extensions configuration
# The freeDiameter framework merely provides support for
# Diameter Base Protocol. The specific application behaviors,
# as well as advanced functions, are provided
# by loadable extensions (plug-ins).
# These extensions may in addition receive the name of a
# configuration file, the format of which is extension-specific.
#
# Format:
#LoadExtension = "/path/to/extension" [ : "/optional/configuration/file" ] ;
#
# Examples:
#LoadExtension = "extensions/sample.fdx";
#LoadExtension = "extensions/sample.fdx":"conf/sample.conf";
# Extensions are named as follow:
# dict_* for extensions that add content to the dictionary definitions.
# dbg_* for extensions useful only to retrieve more information on the framework execution.
# acl_* : Access control list, to control which peers are allowed to connect.
# rt_* : routing extensions that impact how messages are forwarded to other peers.
# app_* : applications, these extensions usually register callbacks to handle specific messages.
# test_* : dummy extensions that are useful only in testing environments.
# The dbg_msg_dump.fdx extension allows you to tweak the way freeDiameter displays some
# information about some events. This extension does not actually use a configuration file
# but receives directly a parameter in the string passed to the extension. Here are some examples:
## LoadExtension = "dbg_msg_dumps.fdx" : "0x1111"; # Removes all default hooks, very quiet even in case of errors.
## LoadExtension = "dbg_msg_dumps.fdx" : "0x2222"; # Display all events with few details.
## LoadExtension = "dbg_msg_dumps.fdx" : "0x0080"; # Dump complete information about sent and received messages.
# The four digits respectively control: connections, routing decisions, sent/received messages, errors.
# The values for each digit are:
# 0 - default - keep the default behavior
# 1 - quiet - remove any specific log
# 2 - compact - display only a summary of the information
# 4 - full - display the complete information on a single long line
# 8 - tree - display the complete information in an easier to read format spanning several lines.
LoadExtension = "/usr/lib/x86_64-linux-gnu/freeDiameter/dbg_msg_dumps.fdx" : "0x8888";
LoadExtension = "/usr/lib/x86_64-linux-gnu/freeDiameter/dict_rfc5777.fdx";
LoadExtension = "/usr/lib/x86_64-linux-gnu/freeDiameter/dict_mip6i.fdx";
LoadExtension = "/usr/lib/x86_64-linux-gnu/freeDiameter/dict_nasreq.fdx";
LoadExtension = "/usr/lib/x86_64-linux-gnu/freeDiameter/dict_nas_mipv6.fdx";
LoadExtension = "/usr/lib/x86_64-linux-gnu/freeDiameter/dict_dcca.fdx";
LoadExtension = "/usr/lib/x86_64-linux-gnu/freeDiameter/dict_dcca_3gpp.fdx";
##############################################################
## Peers configuration
# The local server listens for incoming connections. By default,
# all unknown connecting peers are rejected. Extensions can override this behavior (e.g., acl_wl).
#
# In addition to incoming connections, the local peer can
# be configured to establish and maintain connections to some
# Diameter nodes and allow connections from these nodes.
# This is achieved with the ConnectPeer directive described below.
#
# Note that the configured Diameter Identity MUST match
# the information received inside CEA, or the connection will be aborted.
#
# Format:
#ConnectPeer = "diameterid" [ { parameter1; parameter2; ...} ] ;
# Parameters that can be specified in the peer's parameter list:
# No_TCP; No_SCTP; No_IP; No_IPv6; Prefer_TCP; TLS_old_method;
# No_TLS; # assume transparent security instead of TLS. DTLS is not supported yet (will change in future versions).
# Port = 5868; # The port to connect to
# TcTimer = 30;
# TwTimer = 30;
# ConnectTo = "202.249.37.5";
# ConnectTo = "2001:200:903:2::202:1";
# TLS_Prio = "NORMAL";
# Realm = "realm.net"; # Reject the peer if it does not advertise this realm.
# Examples:
#ConnectPeer = "aaa.wide.ad.jp";
#ConnectPeer = "old.diameter.serv" { TcTimer = 60; TLS_old_method; No_SCTP; Port=3868; } ;
{% for pcrf in pcrf_hosts %}
ConnectPeer = "{{ pcrf }}" { ConnectTo = "{{ pcrf }}"; No_TLS; };
{% endfor %}
##############################################################
I’ve been working on a ePDG for VoWiFi access to my IMS core.
This has led to a bit of a deep dive into GTP (easy enough) and GTPv2 (Bit harder).
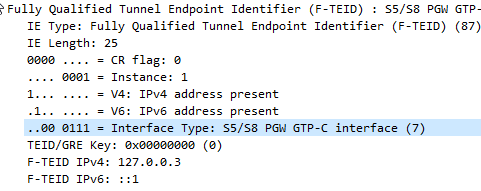
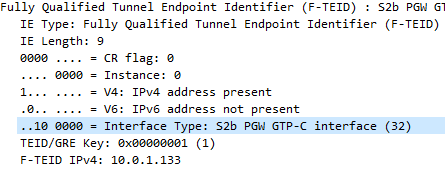
The Fully Qualified Tunnel Endpoint Identifier includes an information element for the Interface Type, identified by a two digit number.
Here we see S2b is 32
In the end I found the answer in 3GPP TS 29.274, but thought I’d share it here.
0
S1-U eNodeB GTP-U interface
1
S1-U SGW GTP-U interface
2
S12 RNC GTP-U interface
3
S12 SGW GTP-U interface
4
S5/S8 SGW GTP-U interface
5
S5/S8 PGW GTP-U interface
6
S5/S8 SGW GTP-C interface
7
S5/S8 PGW GTP-C interface
8
S5/S8 SGW PMIPv6 interface (the 32 bit GRE key is encoded in 32 bit TEID field and since alternate CoA is not used the control plane and user plane addresses are the same for PMIPv6)
9
S5/S8 PGW PMIPv6 interface (the 32 bit GRE key is encoded in 32 bit TEID field and the control plane and user plane addresses are the same for PMIPv6)
10
S11 MME GTP-C interface
11
S11/S4 SGW GTP-C interface
12
S10 MME GTP-C interface
13
S3 MME GTP-C interface
14
S3 SGSN GTP-C interface
15
S4 SGSN GTP-U interface
16
S4 SGW GTP-U interface
17
S4 SGSN GTP-C interface
18
S16 SGSN GTP-C interface
19
eNodeB GTP-U interface for DL data forwarding
20
eNodeB GTP-U interface for UL data forwarding
21
RNC GTP-U interface for data forwarding
22
SGSN GTP-U interface for data forwarding
23
SGW GTP-U interface for DL data forwarding
24
Sm MBMS GW GTP-C interface
25
Sn MBMS GW GTP-C interface
26
Sm MME GTP-C interface
27
Sn SGSN GTP-C interface
28
SGW GTP-U interface for UL data forwarding
29
Sn SGSN GTP-U interface
30
S2b ePDG GTP-C interface
31
S2b-U ePDG GTP-U interface
32
S2b PGW GTP-C interface
33
S2b-U PGW GTP-U interface
I also found how this data is encoded on the wire is a bit strange,
In the example above the Interface Type is 7,
This is encoded in binary which give us 111.
This is then padded to 6 bits to give us 000111.
This is prefixed by two additional bits the first denotes if IPv4 address is present, the second bit is for if IPv6 address is present.
Bit 1
Bit 2
Bit 3-6
IPv4 Address Present
IPv4 Address Present
Interface Type
1
1
000111
This is then encoded to hex to give us 87
Here’s my Python example;
interface_type = int(7)
interface_type = "{0:b}".format(interface_type).zfill(6) #Produce binary bits
ipv4ipv6 = "10" #IPv4 only
interface_type = ipv4ipv6 + interface_type #concatenate the two
interface_type = format(int(str(interface_type), 2),"x") #convert to hex
It’s probably pretty evident to most why you’d want to use TLS these days,
SIP Secure – aka sips has been around for a long time and is supported by most SIP endpoints now.
Kamailio supports TLS, and it’s setup is very straightforward.
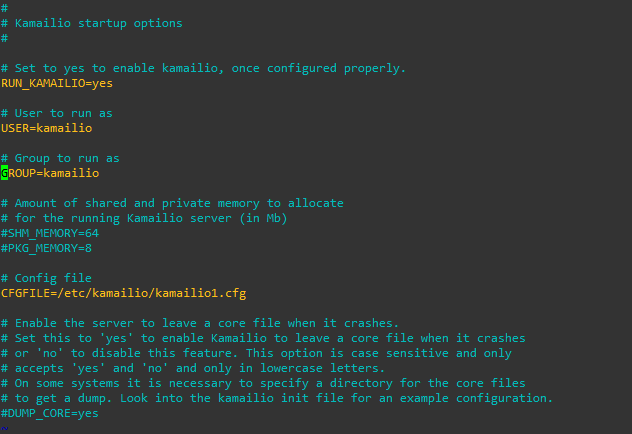
I’ve got a private key and certificate file for the domain nickvsnetworking.com so I’ll use those to secure my Kamailio instance by using TLS.
I’ll start by copying both the certificate (in my case it’s cert.pem) and the private key (privkey.pem) into the Kamailio directory. (If you’ve already got the private key and certificate on your server for another application – say a web server, you can just reference that location so long as the permissions are in place for Kamailio to access)
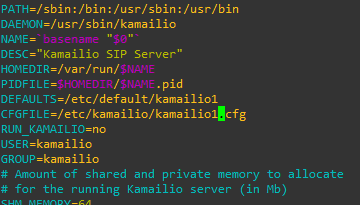
Next up I’ll open my Kamailio config (kamailio.cfg), I’ll be working with an existing config and just adding the TLS capabilities, so I’ll add this like to the config:
!define WITH_TLS
That’s pretty much the end of the configuration in kamailio.cfg, if we have a look at what’s in place we can see that the TLS module loads it’s parameters from a separate file;
After restarting Kamailio subscribers can now contact us via TLS using sips.
You may wish to disable TCP & UDP transport in favor of only TLS.
A note about CAs…
If you’re planning on rolling out SIP over TLS (sips) to existing IP phones it’s worth looking at what Certificate Authorities (CAs) are recognised by the IP phones.
As TLS relies on a trust model where a CA acts kind of like a guarantor to the validity of the certificate, if the IP phone doesn’t recognise the CA, it may see the certificate as Invalid.
Some IP phones for example won’t recognize Let’s Encrypt certificates as valid, while others may not recognize any of the newer CAs.
If you’re running a Debian system, the Kamailio team provide nightly development builds as Debian packages that can be installed on Debian or Ubuntu systems using the apt package manager.
Installing is a breeze, first we just add the GPG key for the repo:
Despite the fact it’s 2020 there’s still a lot of folks in the world manually configuring boxes,
Ansible is a topic I could talk all day about, but in essence it’s kind of an automation framework, tell Ansible what to do one and it can spin you up two boxes, or two thousand boxes and manage the config on them.
I talked about DMQ, the Distributed Message Queue in a Kamailio Bytes post some time ago, and so as an example I’ll share an example playbook to Install Kamailio the lazy way from the Repos, and load the DMQ config with the IP Address and DMQ Address pulled from variables based on the host itself.
There’s a huge number of posts on installing and the basics of Ansible online, if you’re not familiar with Ansible already I’d suggest starting by learning the basics and then rejoining us.
The Hosts
Depending on if your hosts are running on bare metal, VMWare VMs or cloud based, I’m going to assume you’re working with a Debian system.
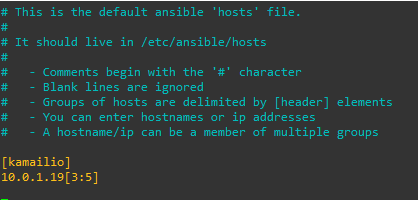
I’ve already got 3 servers ready to go, they’ve got sequential IP Addresses so I’ve added the range to my /etc/ansible/hosts file:
I’ve created the group kamailio and put the IP Address range 10.0.1.193 to 10.0.1.195 in there.
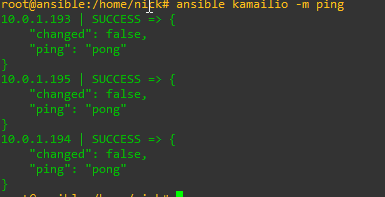
You will probably need to add the authentication info, such as passwords, private keys and privilege escalation details, but I’m going to assume you’ve already done that and you can run the ping module on each one:
ansible kamailio -m ping
Assuming that comes back OK and you can get into each one let’s move onto the Playbook.
The Playbook
There’s a few tasks we’ll get out of the way before we configure Kamailio,
The first of which is adding the Debian repo and the keys,
Next we’ll load a Kamailio config from a template that fills in our IP Address and Kamailio version, then we’ll install Kamailio,
Rather than talk you through each of the plays here’s a copy of my playbook:
---
- name: Configure Kamailio
hosts: kamailio
become: yes
vars:
kamailio_version: "53"
debian_sources_dir: "/etc/apt/sources.list.d"
tasks:
- name: Add keys for Kamailio repo
apt_key:
url: http://deb.kamailio.org/kamailiodebkey.gpg
state: present
- name: Add repo to sources.list
apt_repository:
repo: deb http://deb.kamailio.org/kamailio{{kamailio_version}} {{hostvars[inventory_hostname]['ansible_lsb']['codename']}} main
#The full list of Debian repos can be found at http://deb.kamailio.org/
#The version is based off the versions listed there and the release is based on the codename of the Debian / Ubuntu release.
state: present
- name: Copy Config Template
#Copies config from the template, fills in variables and uplaods to the server
template:
src: kamailio.cfg.j2
dest: /etc/kamailio/kamailio.cfg
owner: root
group: root
backup: yes
register: config_changed
- name: Install Kamailio
#Updates cache (apt-get update) and then installs Kamailio
apt:
name: kamailio
update_cache: yes
state: present
register: kamailio_installed_firstrun
- name: Restart Kamailio if config changed
service:
name: kamailio
state: restarted
when: config_changed.changed
- name: Start Kamailio if installed for the first time
service:
name: kamailio
state: started
when: kamailio_installed_firstrun.changed
Should be pretty straight forward to anyone who’s used Ansible before, but the real magic happens in the templatemodule. Let’s take a look;
Kamailio config in Jinja2 template
Pusing out static config is one thing, but things like IP Addresses, FQDNs and SSL certs may differ from machine to machine, so instead of just pushing one config, I’ve created a config and added some variables in Jinja2 format to the config, that will be filled with the value on the target when pushed out.
In the templatemodule of the playbook you can see I’ve specified the file kamailio.cfg.j2 this is just a regular Kamailio config file but I’ve added some variables, let’s look at how that’s done.
On the machine 10.0.1.194 we want it to listen on 10.0.1.194, we could put list 0.0.0.0 but this can lead to security concerns, so instead let’s specify the IP in the Jinja config,
By putting ansible_default_ipv4.address in two sets of curly brackets, this tells Ansible to fill in thes values from the template with the Ansible IPv4 Address of the target machine.
Let’s take a look on the 10.0.1.194’s actual kamailio.cfg file:
Let’s take another example,
To keep DMQ humming it makes sense to have different DMQ domains for different versions of Kamailio, so in the Kamailio config file template I’ve called the variable kamailio_versionin the DMQ address,
This means on a Kamailio 5.2 version this URL look like this on the boxes’ config:
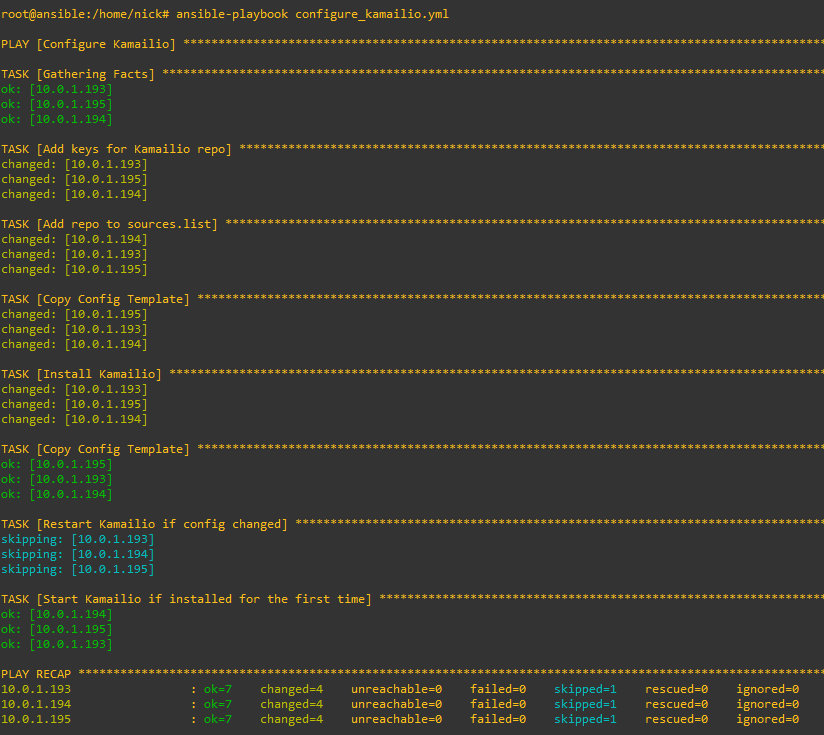
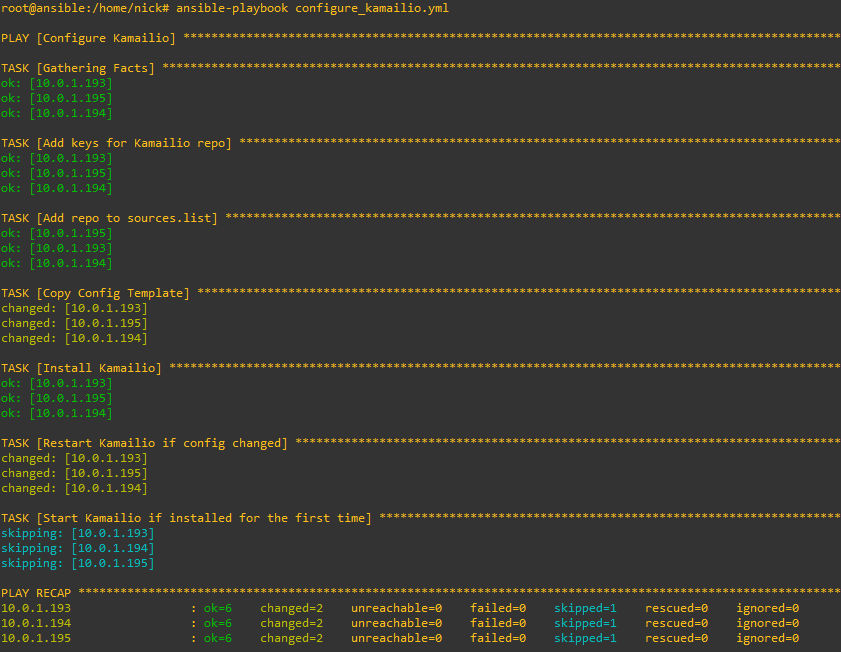
Running it is just a simple matter of calling ansible-playbook and pointing it at the playbook we created, here’s how it looks setting up the 3 hosts from their vanilla state:
The great thing about Kamailio is it’s omnipotent – This means it will detect if it needs to do each of the tasks specified in the playbook.
So if we run this again it won’t try and add the repo, GPG keys, install Kamailio and load the template, it’ll look and see each of those steps have already been done and skip each of them.
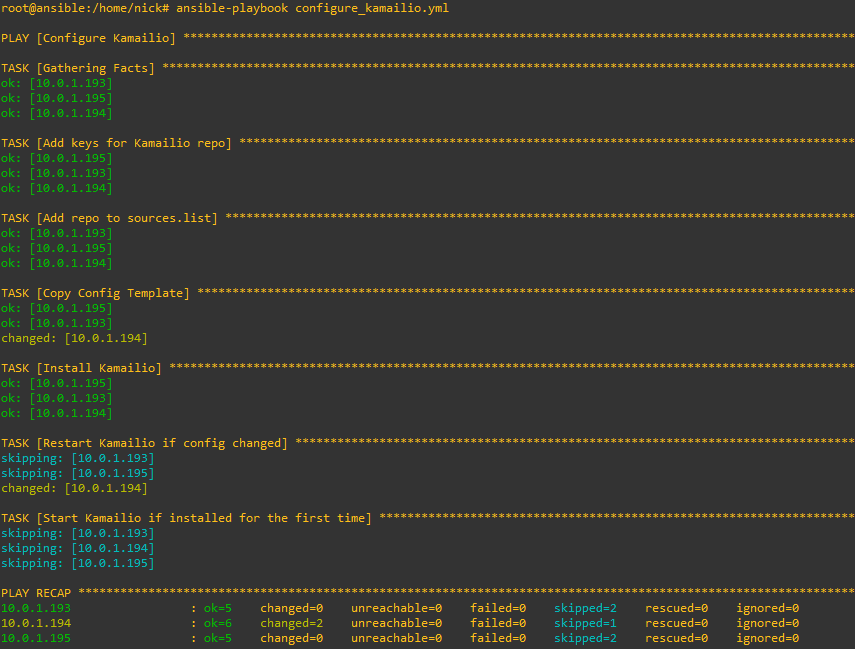
But what if someone makes some local changes on one of the boxes, let’s look at what happens:
Likewise now if we decide to change our config we only need to update the template file and Ansible will push it out to all our machines, I’ve added a comment into the Kamailio template, so let’s run it again and see the config pushed out to all the Kamailio instances and them restarting.
I’ve been working for some time on open source mobile network cores, and one feature that has been a real struggle for a lot of people (Myself included) is getting VoLTE / IMS working.
Here’s some of the issues I’ve faced, and the lessons I learned along the way,
Sadly on most UEs / handsets, there’s no “Make VoLTE work now” switch, you’ve got a satisfy a bunch of dependencies in the OS before the baseband will start sending SIP anywhere.
Get the right Hardware
Your eNB must support additional bearers (dedicated bearers I’ve managed to get away without in my testing) so the device can setup an APN for the IMS traffic.
Sadly at the moment this rules our Software Defined eNodeBs, like srsENB.
ISIM – When you thought you understood USIMs – Guess again
According to the 3GPP IMS docs, an ISIM (IMS SIM) is not a requirement for IMS to work.
However in my testing I found Android didn’t have the option to enable VoLTE unless an ISIM was present the first time.
In a weird quirk I found once I’d inserted an ISIM and connected to the VoLTE network, I could put a USIM in the UE and also connect to the VoLTE network.
Obviously the parameters you can set on the USIM, such as Domain, IMPU, IMPI & AD, are kind of “guessed” but the AKAv1-MD5 algorithm does run.
Getting the APN Config Right
There’s a lot of things you’ll need to have correct on your UE before it’ll even start to think about sending SIP messaging.
I was using commercial UE (Samsung handsets) without engineering firmware so I had very limited info on what’s going on “under the hood”. There’s no “Make VoLTE do” tickbox, there’s VoLTE enable, but that won’t do anything by default.
If your P-GW doesn’t know the IP of your P-CSCF, it’s not going to be able to respond to it in the Protocol Configuration Options (PCO) request sent by the UE with that nice new bearer for IMS we just setup.
There’s no way around Mutual Authentication
Coming from a voice background, and pretty much having RFC 3261 tattooed on my brain, when I finally got the SIP REGISTER request sent to the Proxy CSCF I knocked something up in Kamailio to send back a 200 OK, thinking that’d be the end of it.
For any other SIP endpoint this would have been fine, but IMS Clients, nope.
Reading the specs drove home the same lesson anyone attempting to setup their own LTE network quickly learns – Mutual authentication means both the network and the UE need to verify each other, while I (as the network) can say the UE is OK, the UE needs to check I’m on the level.
I saw my 401 response go back to the UE and then no response. Nada.
This led to my next lesson…
There’s no way around IPsec
According to the 3GPP docs, support for IPsec is optional, but I found this not to be the case on the handsets I’ve tested.
After sending back my 401 response the UE looks for the IPsec info in the 401 response, then tries to setup an IPsec SA and sends ESP packets back to the P-CSCF address.
Even with my valid AKAv1-MD5 auth, I found my UE wasn’t responding until I added IPsec support on the P-CSCF, hence why I couldn’t see the second REGISTER with the Authentication Info.
After setting up IPsec support, I finally saw the UE’s REGISTER with the AKAv1-MD5 authentication, and was able to send a 200 OK.
For my LTE lab I got myself a BaiCells Neutrino, it operates on Band 3 (FDD ~1800Mhz) with only 24dBm of output power max and PoE powered it works well in a lab environment without needing -48vDC supply, BBUs, DUs feeders and antennas.
Setup can be done via TR-069 or via BaiCells management server, for smaller setups the web UI makes setup pretty easy,
Logging in with admin/admin to the web interface:
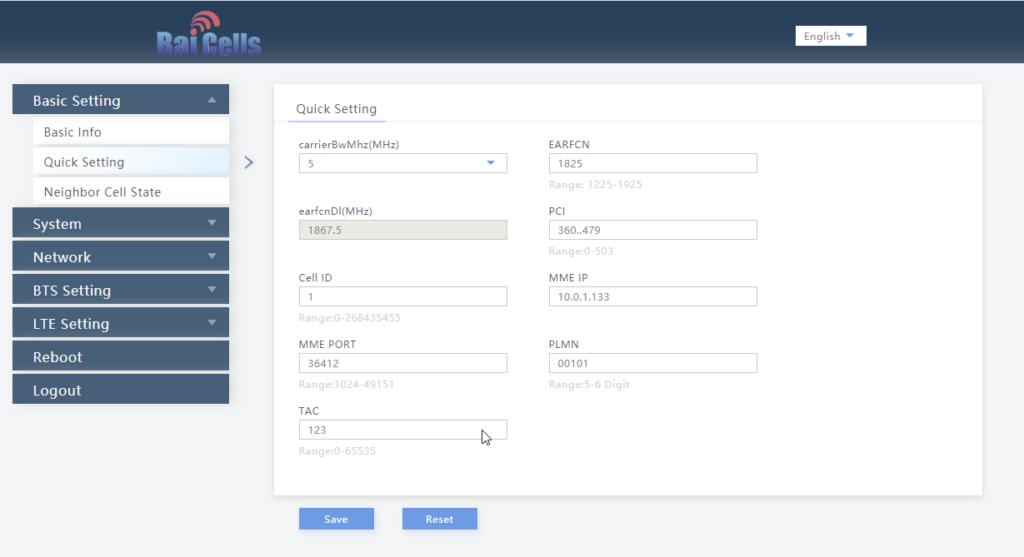
We’ll select Quick Settings, and load in our MME IP address, PLMN (MCC & MNC), Tracking Area Code, Cell ID and Absolute Radio Frequency No.
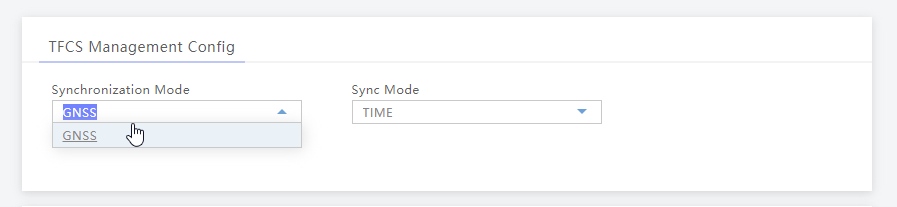
Once that’s done we’ll set our Sync settings to use GPS / GNSS (I’ve attached an external GPS Antenna purchased cheaply online).
Finally we’ll set the power levels, my RF blocking setup is quite small so I don’t want excess power messing around with it, so I’ve dialed the power right back:
And that’s it, it’ll now connect to my MME on 10.0.1.133 port 36412 on SCTP.
The Proxy-Call Session Control Function is the first network element a UE sends it’s SIP REGISTER message to, but how does it get there?
To begin with our UE connects as it would normally, getting a default bearer, an IP address and connectivity.
Overview
If the USIM has an ISIM application on it (or IMS is enabled on the UE using USIM for auth) and an IMS APN exists on the UE for IMS, the UE will set up another bearer in addition to the default bearer.
This bearer will carry our IMS traffic and allow QoS to be managed through the QCI values set on the bearer.
While setting up the bearer the UE requests certain parameters from the network in the Protocol Configuration Options element, including the P-CSCF address.
When setting up the bearer the network responds with this information, which if supported includes the P-CSCF IPv4 &/or IPv6 addresses.
The Message Exchange
We’ll start assuming the default bearer is in place & our UE is configured with the APN for IMS and supports IMS functionality.
The first step is to begin the establishment of an additional bearer for the IMS traffic.
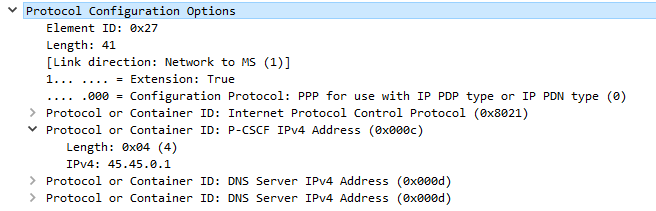
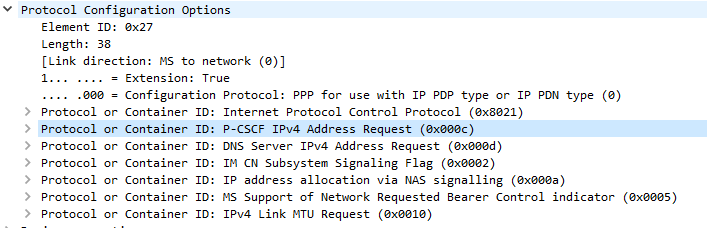
This is kicked off through the Uplink NAS Transport, PDN Connectivity Request from the UE to the network. This includes the IMS APN information, and the UE’s NAS Payload includes the Protocol Configuration Options element (PCO), with a series of fields the UE requires responses from the network. including DNS Server, MTU, etc.
In the PCO the UE also includes the P-CSCF address request, so the network can tell the UE the IP of the P-CSCF to use.
If this is missing it’s because either your APN settings for IMS are not valid, or your device doesn’t have IMS support or isn’t enabling it.(that could be for a few reasons).
Protocol Configuration Options (Unpopulated) used to request information from the Network by the UE
The MME gets this information from the P-GW, and the network responds in the E-RAB Setup Request, Activate default EPS bearer Context Request and includes the Protocol Configuration Options again, this time the fields are populated with their respective values, including the P-CSCF Address;
Once the UE has this setup, the eNB confirms it’s setup the radio resources through the E-RAB Setup Response.
One the eNB has put the radio side of things in place, the UE confirms the bearer assignment has completed successfully through the Uplink NAS Transport, Activate default EPS Bearer Accept, denoting the bearer is now in place.
Now the UE has the IP address(s) of the P-CSCF and a bearer to send it over, the UE establishes a TCP socket with the address specified in the P-CSCF IPv4 or IPv6 address, to start communicating with the P-CSCF.
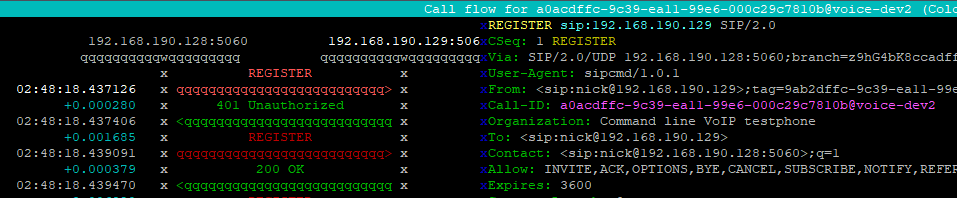
The SIP REGISTER request can now be sent and the REGISTRATION procedure can begin.
To be able to call sipcmd from anywhere, copy the binary to /usr/sbin/
cp sipcmd /usr/sbin/
Usage
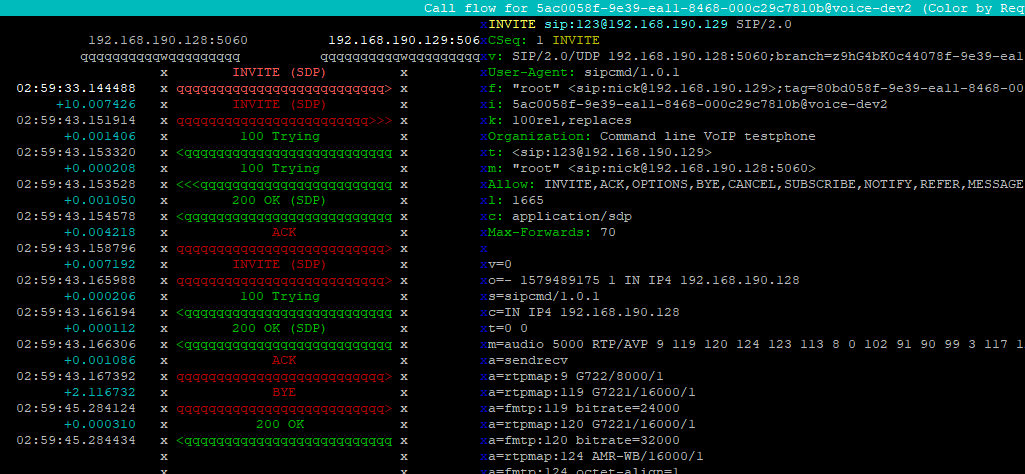
Unlike SIPp, sipcmd has a much more simple syntax to allow you to follow basic call scenarios, like call a destination, wait a set time and then hangup, or answer an incoming call and send a DTMF digit and wait for the called party to hangup.
So let’s get the most basic thing we can set, SIP Registration and Authentication.
And there you have it, simple as that, we’ve made a test call, waited a set time and then hung up.
We can even combine this with monitoring / NMS systems like Nagios to run tests against the network continually.
For more advanced scenarios I’d recommend using SIPp, but for simple testing, particularly from a command line, sipcmd is a simple easy place to start.
The team at Software Radio Systems in Ireland have been working on an open source LTE stack for some time, to be used with software defined radio (SDR) hardware like the USRP, BladeRF and LimeSDR.
They’ve released SRSUE and SRSENB their open source EUTRAN UE and eNodeB, which allow your SDR hardware to function as a LTE UE and connect to a commercial eNB like a standard UE while getting all the juicy logs and debug info, or as a LTE eNB and have commercial UEs connect to a network you’re running, all on COTS hardware.
The eNB supports S1AP to connect to a 3GPP compliant EPC, like Open5Gs, but also comes bundled with a barebones EPC for testing.
The UE allows you to do performance testing and gather packet captures on the MAC & PHY layers, something you can’t do on a commericial UE. It also supports software-USIMs (IMSI / K / OP variables stored in a text file) or physical USIMs using a card reader.
I’ve got a draw full of SDR hardware, from the first RTL-SDR dongle I got years ago, to a few HackRFs, a LimeSDR up to the BladeRF x40.
Really cool software to have a play with, I’ve been using SRSUE to get a better understanding of the lower layers of the Uu interface.
Installation
After mucking around trying to satisfy all the dependencies from source I found everything I needed could be found in Debian packages from the repos of the maintainers.
To begin with we need to install the BladeRF drivers and SopySDR modules to abstract it to UHD:
People think SIP they think VoIP & phone calls, but SIP it’s the Phone Call Initiation Protocol it’s the Session Initiation Protocol – Sure VoIP guys like me love SIP, but it’s not just about VoIP.
Have you sent an SMS on a modern mobile phone recently? Chances are you sent a SMS over SIP using SIP MESSAGE method.
So let’s look a bit at SIP SIMPLE, the catchily titled acronym translates to Session Initiation Protocol for Instant Messaging and Presence Leveraging Extensions (Admittedly less catchy in it’s full form).
There’s two way SIP SIMPLE can be used to implement Instant Messaging, Paging Mode with each message sent as a single transaction, and Session Mode where a session is setup between users and IMs exchanged with the same Call ID / transaction.
I’m going to cover the Paging Mode implementation because it’s simpler easier to understand.
Before we get too far this is another example of confusing terminology, let’s just clear this up; According to the RFC any SIP request is a SIP Message, like a SIP OPTIONS message, a SIP INVITE message. But the method of a SIP INVITE message is INVITE, the method of a SIP OPTIONS message is OPTIONS. There’s a SIP MESSAGE method, meaning you can send a SIP MESSAGE message using the MESSAGE method. Clear as mud? I’ll always refer to the SIP Method in Capitals, like MESSAGE, INVITE, UPDATE, etc.
The SIP MESSAGE method looks / acts very similar to a SIP INVITE, in that it’s got all the standard SIP headers, but also a Message Body, in which our message body lives (funny about that), typically we’ll send messages using the Content-Type: text/plain to denote we’re sending a plaintext message.
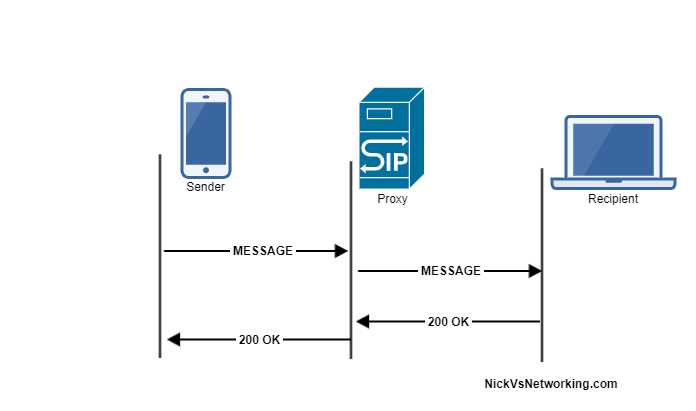
Example MESSAGE Message Flow
Like a SIP OPTIONS Method, the MESSAGE method is simply answered with a 200 OK (No Ack).
Let’s have a look at how the MESSAGE message looks:
In my last post I talked about using KEMI in Kamailio and how you can integrate in a different programming language to handle your SIP request handling in a language you already know – Like Python!
Before we get too excited there’s some boilerplate we’ve got to add to our Python script, we need to create a class called kamailio and populate the class by defining some functions, we’ll define an __init__ to handle loading of the class, define a child_init for handling child processes, define ksr_request_route to handle the initial requests. We’ll also need to define a mod_init – outside of the Kamailio class to initialize the class.
import sys
import Router.Logger as Logger
import KSR as KSR
import requests
# global function to instantiate a kamailio class object
# -- executed when kamailio app_python module is initialized
def mod_init():
KSR.info("===== from Python mod init\n");
return kamailio();
# -- {start defining kamailio class}
class kamailio:
def __init__(self):
KSR.info('===== kamailio.__init__\n');
# executed when kamailio child processes are initialized
def child_init(self, rank):
KSR.info('===== kamailio.child_init(%d)\n' % rank);
return 0;
# SIP request routing
# -- equivalent of request_route{}
def ksr_request_route(self, msg):
KSR.info("===== request - from kamailio python script\n");
KSR.dbg("method " + KSR.pv.get("$rm") + " r-uri " + KSR.pv.get("$ru"))
Most of these should be pretty self explanatory for anyone who’s done a bit more in-depth Python programming, but it’s no big deal if you don’t understand all this, the only part you need to understand is the ksr_request_route function.
ksr_request_route: translates to our request_route{} in the Kamailio native scripting language, all requests that come in will start off in this part.
Python Kamailio Routing
So let’s start to build upon this, so we’ll blindly accept all SIP registrations;
Here you’ll see we’ve added an if statement, as if we were doing any other If statement in Python, in this case we’re asking if the KSR.is_method(“REGISTER”), and if it is, we’ll send back a 200 OK response.
Let’s pause and talk about KSR
All the Kamailio bits we’ll use in Python will have the KSR. prefix, so let’s take a quick break here to talk about KSR. The KSR. functions are the KEMI functions we’ve exposed to Python.
Without them, we’re just writing Python, and we’d have to do all the functions provided by Kamailio nativeley in Python, which would be crazy.
So we leverage the Kamailio modules you know and love from Python using Python’s logic / programming syntax, as well as opening up the ability to pull in other libraries from Python.
Let’s look at how we might send a stateless reply,
There’s a module function to send a stateless reply;
KSR.sl.send_reply(200, "OK")
The vast majority of functions are abstracted as module functions, like the example above, but not all of them.
So every function doesn’t need to be wrapped up as a module, there’s also a way to call any function that you’d call from the native scripting language, wrapped up, kind of like an Exec command:
KSR.x.modf("sl_send_reply", "200", "OK");
So thanks to this we can call any Kamailio function from Python, even if it’s not explicitly in the KEMI abstraction.
Python Kamailio Routing (Continued)
So earlier we managed REGISTER requests and sent back a 200 OK response.
What about forwarding a SIP Request to another proxy? Let’s follow on with an elif statement to test if the method is an INVITE and statelessly forward it.
elif KSR.is_method("INVITE"):
#Lookup our public IP address
try:
ip = requests.get('https://api.ipify.org').text
except:
ip = "Failed to resolve"
#Add that as a header
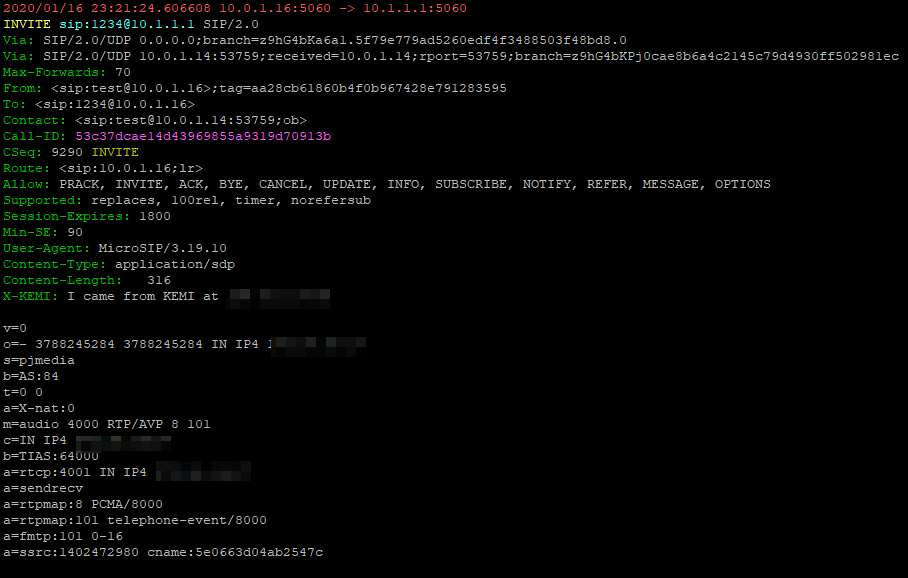
KSR.hdr.append("X-KEMI: I came from KEMI at " + str(ip) + "\r\n");
#Set host IP to 10.1.1.1
KSR.sethost("10.1.1.1");
#Forward the request on
KSR.forward()
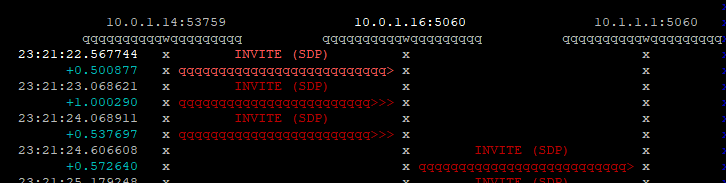
Now an incoming SIP invite will be proxied / forwarded to 10.1.1.1, all from Python.
But so far we’ve only done things in KEMI / Python that we could do in our native Kamailio scripting language, so let’s use some Python in our Python!
I utterly love the Python Requests library, so let’s use that to look up our public IP address and add it as a header to our forwarded SIP INVITE;
elif KSR.is_method("INVITE"):
#Lookup our public IP address
try:
ip = requests.get('https://api.ipify.org').text
except:
ip = "Failed to resolve"
#Add that as a header
KSR.hdr.append("X-KEMI: I came from KEMI at " + str(ip) + "\r\n");
#Set host IP to 10.1.1.1
KSR.sethost("10.1.1.1");
#Forward the request on
KSR.forward()
Bottom header is the X-KEMI custom header we included with our public IP
So let’s wrap this up a bit and handle any other request that’s not an INVITE or a REGISTER, with a 500 error code.
# SIP request routing
# -- equivalent of request_route{}
def ksr_request_route(self, msg):
KSR.dbg("method " + KSR.pv.get("$rm") + " r-uri " + KSR.pv.get("$ru"))
if KSR.is_method("REGISTER"):
KSR.sl.send_reply(200, "OK")
elif KSR.is_method("INVITE"):
#Lookup our public IP address
try:
ip = requests.get('https://api.ipify.org').text
except:
ip = "Failed to resolve"
#Add that as a header
KSR.hdr.append("X-KEMI: I came from KEMI at " + str(ip) + "\r\n");
#Set host IP to 10.1.1.1
KSR.sethost("10.1.1.1");
#Forward the request on
KSR.forward()
else:
KSR.sl.send_reply(500, "Got no idea...")