I’ve been using IBM’s Watson’s Speech to Text engine for transcribing call audio, some possible use cases are speech driven IVRs, Voicemail to Email transcription, or making Call Recordings text-searchable.
The last time I’d played with Speech Recognition on Voice Platforms was in 2012, and it’s amazing to see how far the technology has evolved with the help of AI.
IBM’s offering is a bit more flexible than the Google offering, and allows long transcription (>1 minutes) without uploading the files to external storage.
Sadly, Watson doesn’t have Australian language models out of the box (+1 point to Google which does), but you can add Custom Language Models & train it.
Input formats support PCM coded data, so you can pipe PCMA/PCMU (Aka G.711 µ-law 7 a-law) audio straight to it.
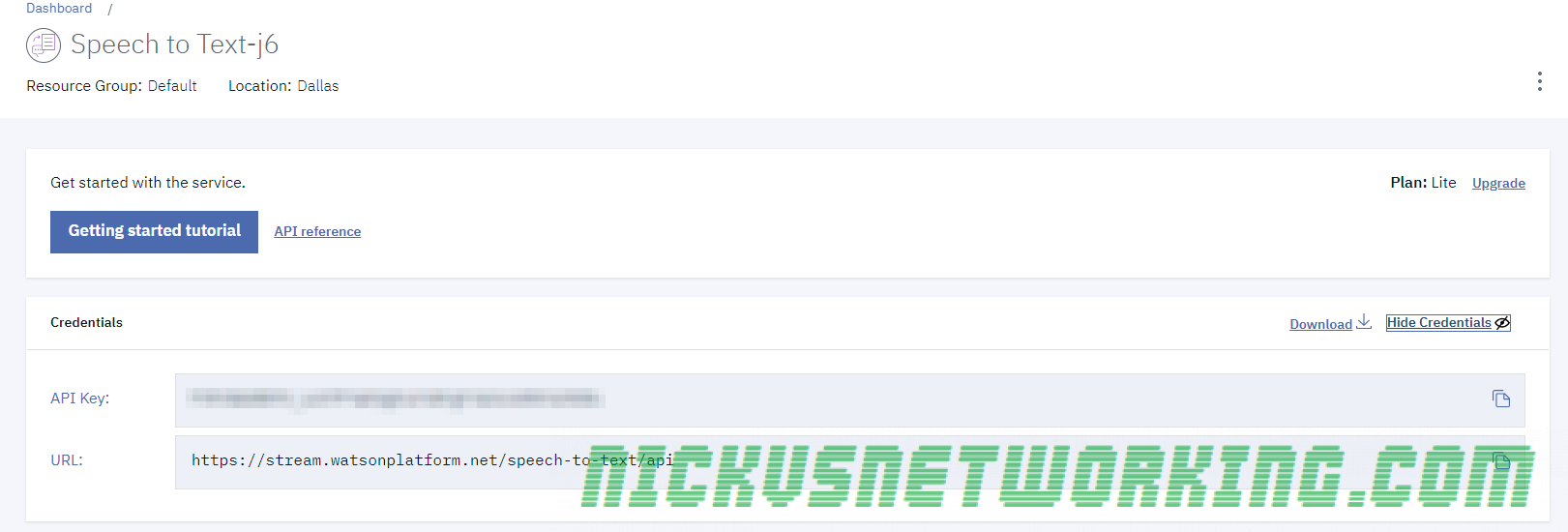
Getting Setup
The first thing you’re going to need are credentials.
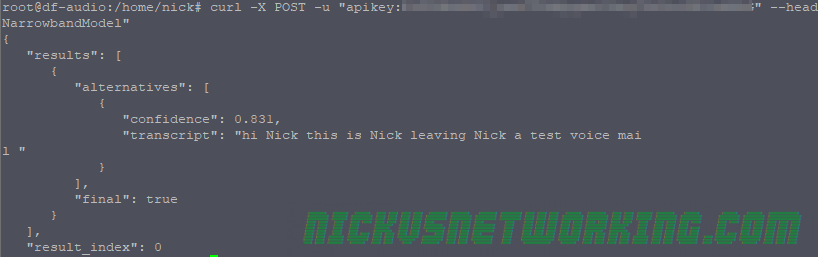
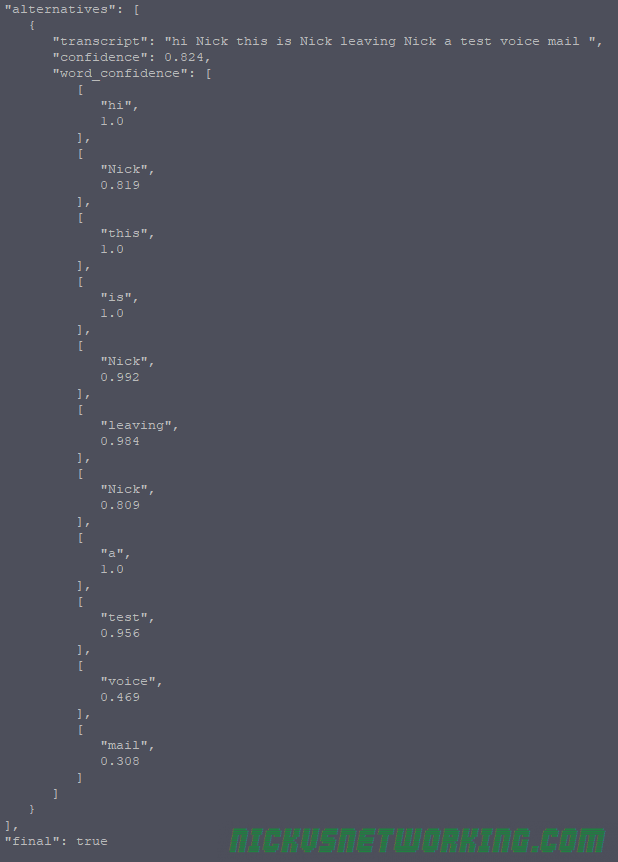
“confidence”: 0.831, “transcript”: “hi Nick this is Nick leaving Nick a test voice mail “
Common Transcription Options
speaker_labels=true
Speaker labels enable you to identify each speaker in a multi-party call.
This makes the transcription read more like a script with “Speaker 1: Hello other person” “Speaker 2: Hello there Speaker 1”, makes skimming through much easier.
timestamps=true
Timestamps timestamp each word based on the start of the audio file,
This reads poorly in CURL but when used with speaker_labels allows you to see the time and correlate it with a recording.
One useful use case is searching through a call recording transcript, and then jumping to that timestamp in the audio.
For example in a long conference call recording you might be interested in when people talked about “Item X”, you can search the call recording for “Item” “X” and find it’s at 1:23:45 and then jump to that point in the call recording audio file, saving yourself an hour and bit of listening to a conference call recording.
Audio formats (content types)
Unfortunately Watson, like GCP, only has support for MULAW (μ-law compounding) and not PCMA as used outside the US.
Luckily it has wide ranging WAV support, something GCP doesn’t, as well as FLAC, G.729, mpg, mp3, webm and ogg.
Speech Recognition Model
Watson has support for US and GB variants of speech recognition, wideband, narrowband and adaptive rate bitrates.
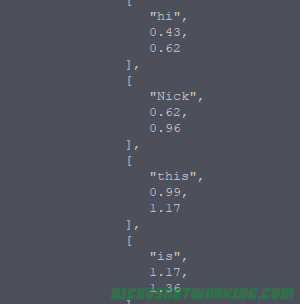
word_confidence=true
Per word confidence allows you to see a per word confidence breakdown, so you can mark unknown words in the final output with question marks or similar to denote if it’s not confident it has transcribed correctly.
Voice and mail Watson wasn’t sure of
max_alternatives
This allows you to specify on either a per-word basis or as a whole, the maximum number of alternatives Watson has for the conversation.