The Packet Gateway connects users of an LTE network to external networks like the Internet, by encapsulating IP packets inside GTP and forwarding them on to reach our subscriber wherever in the network they are.
To understand the P-GW, first it’s a good idea to first get a grasp on what GTP is and why we use GTP to transport subscriber’s data through the LTE Evolved Packet Core.
So we use GTP to encapsulate user’s traffic, making it easy to carry it transparently from outside networks (Like the Internet) to the eNodeB and onto our UE / mobile phones, and more importantly redirect where the user’s traffic it’s going while keeping the same IP address.
But we need a network element to take plain old IP from external networks / Internet, and encapsulate the traffic into the GTP packets we’ll send to the subscriber.
This network element will have to do the same in reverse and decapsulate traffic coming from the subscriber to put it back onto the external networks / Internet.
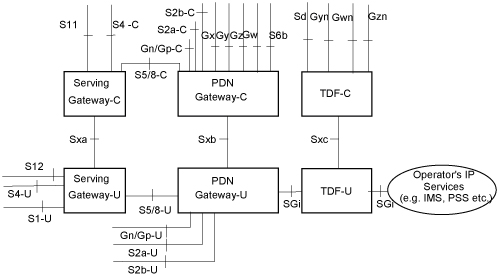
That’s the role of the Packet Gateway (P-GW). The P-GW sits on the border between the outside network (An interface / reference point known as the SGi Interface) and the rest of the packet core (Serving-Gateway then onto eNodeB & UE) via the S5 Interface.

Let’s look at how the P-GW handles an incoming packet:
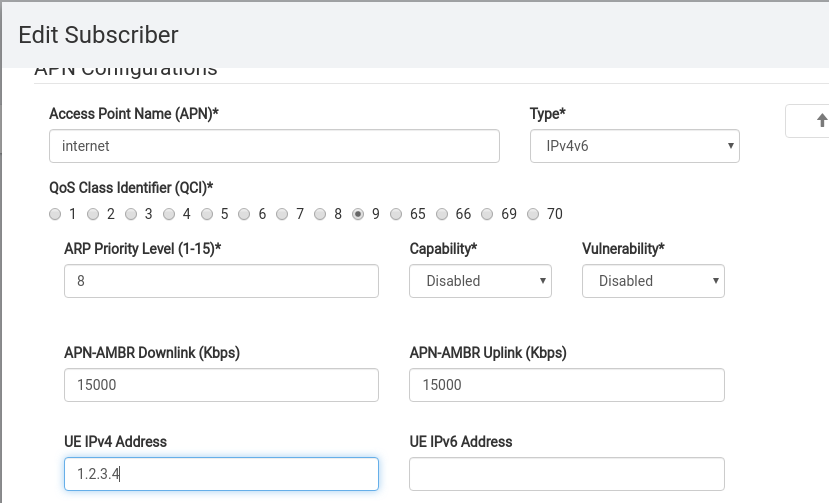
- An IP packet comes in from the Internet destined for IP 1.2.3.4 and routed to the P-GW.
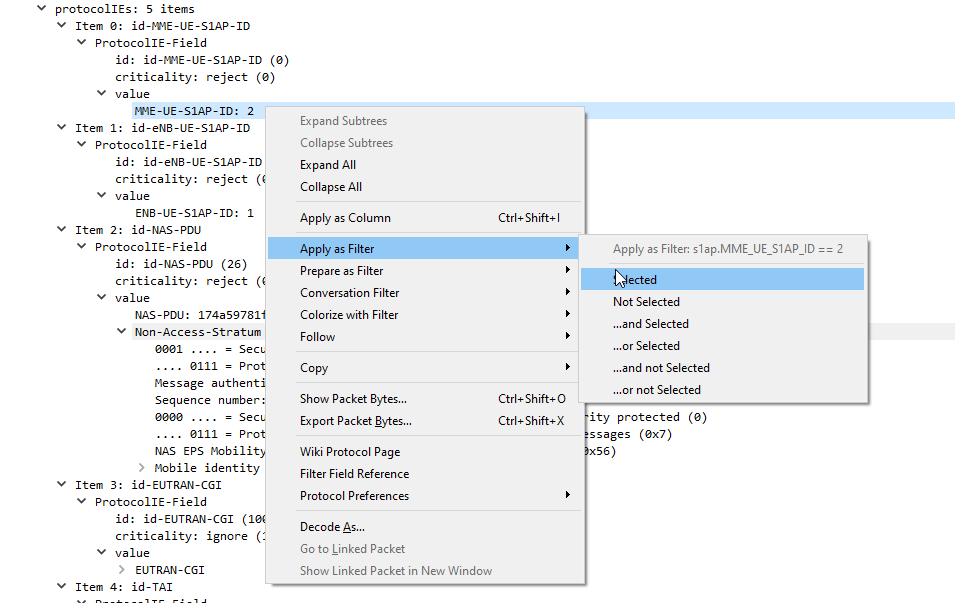
- The P-GW looks up in it’s internal database what Tunnel Endpoint Identifier (TEID) IP Address 1.2.3.4 is associated with.
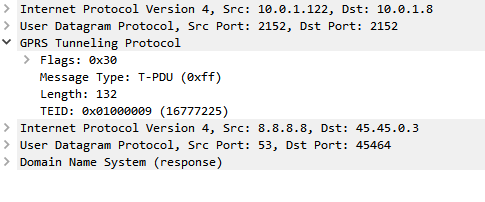
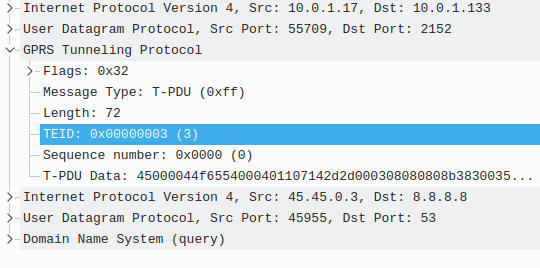
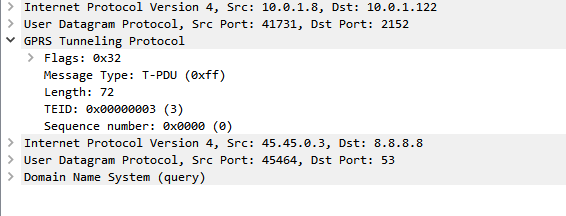
- The P-GW encapsulates the IP packet (Layer 3 & up) into a GTP packet, adding the Tunnel Endpoint Identifier (TEID) to the GTP header.
- The P-GW looks up in it’s internal database which Serving Gateway is handling traffic for that TEID.
- The P-GW then sends this GTP packet containing our IP packet to the Serving Gateway.
In order to start relaying traffic to/from the S5 & SGi interfaces, the P-GW needs a set of procedures for setting up these sessions, (IP Address allocation and TEID allocation) known as bearers. This is managed using GTPv2 (aka GTPv2-Control Plane / GTPv2-C).
GTPv2-C has a set of procedures for creating these sessions, the key ones used by the P-GW are:
- Create Session Request / Response – Sets up GTP sessions / bearers
- Delete Session Request / Response – Removes GTP session / bearers
The Create Session Request is sent by the S-GW to the P-GW and contains the APN of the network to be setup, the IP Address to be assigned (if static) and information regarding the maximum throughput the user will be permitted to achieve.
If the P-GW was able to setup the connection as requested, a Create Session Response is sent back to the P-GW, with the IP Address for the UE to use, and the TEID (Tunnel Endpoint Identifier).
At this stage the tunnel is up and ready to go, traffic to the P-GW to the IP of the UE will be encapsulated in GTP-U packets with the TEID for this bearer, and forwarded on to the S-GW serving the user.