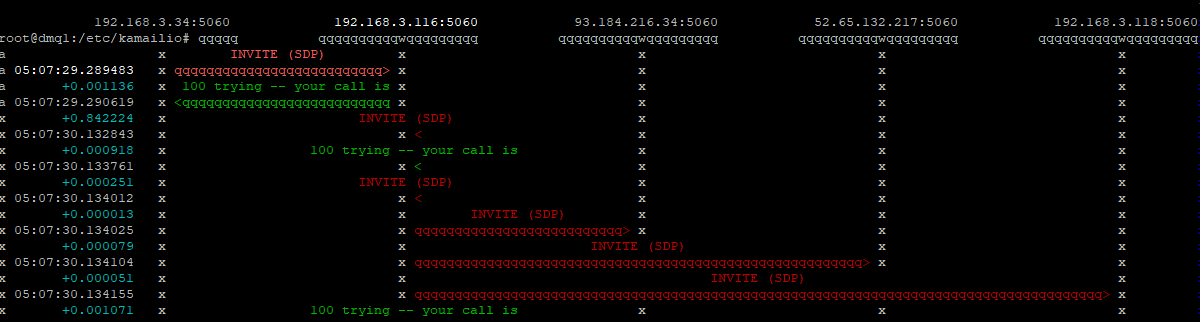
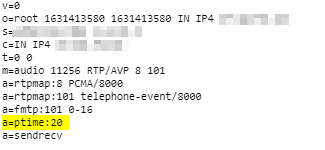
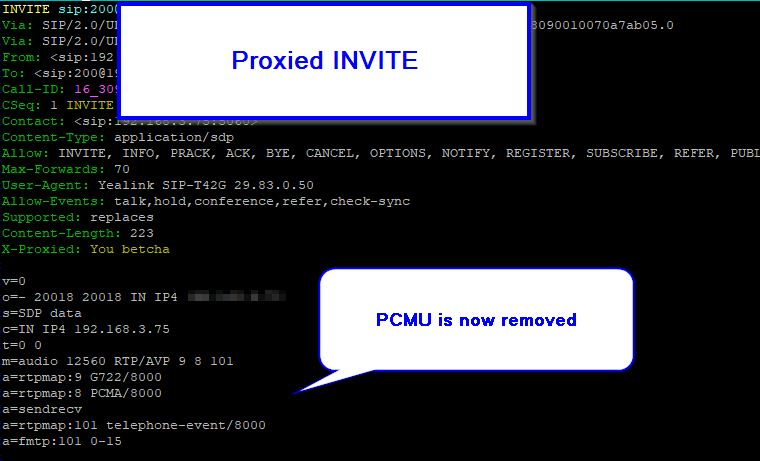
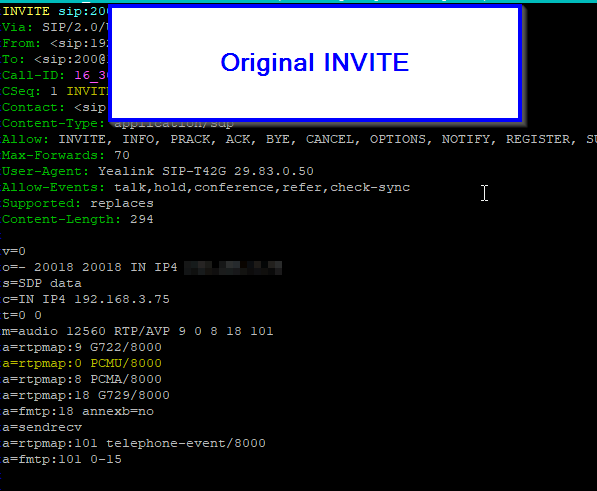
Starting from today, Australia’s largest carrier will begin disconnecting ISDN services, and all will be shut off entirely by 2022.
When I started working in the industry the question wasn’t how many SIP Channels you wanted, but rather PRI or BRI when it came to trunk lines.
We’d use ISDN dial up to remotely administer systems, and had a bulky ISDN PRI test set for testing lines and BERT.
ISDN Crossovers, QSIG, gateways, ISUP, Bit Error Rate Testing, loopbacks, clock slips, cause code 16, enblock dialing – all things I’m not likely to need to know anymore.
Since ISDN was first rolled out in Australia just over 3 decades ago, to it being switched off from today onward, ISDN has been crazily reliable, and as much as it pains me to admit it, it has availability stats any SIP provider would be envious of.
As the market evolved over the years the smaller telcos realized using ISDN-SIP gateways made by AudioCodes, Epigy, Sangoma & Quintum was a cheap way to provide a drop in replacement for those expensive Telstra/Optus ISDN services. This generally was a stop gap measure as companies then made the move to straight SIP and stopped paying for the gateway device each month.
And just like that, ISDN was no longer relevant.
So today SIP based VoIP is the clear standard, ISDN fades away, but strangely those POTS lines carry on. Sure they are just VoIP delivered over a carrier grade ATA, but that 48vDC loop of copper with AC ring current, standardized over 120 years ago somehow lives on…
Here’s an article from The Age dated 11 August 1989:
Number may be up for the Telephone
Alexander Graham Bell’s system of sending voices over wires with a varying electrical current started a revolution, then weathered it for 123 years.
In Australia, that unchallenged reign officially ended yesterday with the official beginning of another revolution called integrated services digital networking — ISDN. The telephone has married the computer and gone digital.
The revolution really began late last year when Telecom invited several big companies to try out the communications system that will soon extend its tendrils into our offices and eventually, our homes.
In Canberra’s new National Convention Centre yesterday, the Minister for Telecommunications and Aviation Support, Mrs Kelly, communicated simultaneously via voice, fax and photovideotex on a single telephone line with two senior officers of the Defence Department in an office on the other side of Canberra.
Mr Bell’s telephone could never do that — it does only one job at a time.
With ISDN, any device that speaks or responds to the simple on-off language of computer digital code, or anything that can be rendered in the same code, including the human voice, video images and computer images, can be sent simultaneously on a single ISDN connection.
Each type of information is coded and -addressed in such a way that, at the other end, fax messages go to faxes, voices come out of the telephone and computer images arrive onscreen or on a printer.
The system inaugurated by Mrs Kelly is called ISDN Macro-link. It allows large companies with high-volume communications needs to design their own communications networks by selecting from a range of services available through the network, and plugging in the devices they need to do their business.
Like Lego, ISDN can be configured in myriad ways. It permits permanent, high-volume links to be established between offices in widely separated locations so that big computers can talk to each other.
Charges for all ISDN use are based on the amount of information sent.
The blazingly fast G4 fax can transmit a full A4 page in a few seconds, and the image emerges perfect and with the tiniest detail still visible, as if fresh from a laser printer.
The same link allows an executive in Melbourne to call a colleague in Sydney as easily as dialing an extension in the same building.
One can sketch a diagram on his computer terminal, and it will appear at the other end as it is being drawn.
Photographs can be digitized on a scanner and sent to a computer or printer as they speak, and if they wish, the colleagues can even see each other’s faces on slow scan video.
ISDN’s availability will lead to a change in the design of items like telephones, personal computers, printers and faxes — already companies are making devices that integrate all four.
As Australian and overseas networks develop, and ISDN communication between continents increases, the global village will shrink even further.
Number may be up for the telephone – Grahame O’Neill, Science and Technology Reporter
‘The AGE’ Melbourne Australia – Friday 11 August 1989