If you’ve got parents of a certain age, you’re probably quite used to getting the thumbs up emoji.
For the more tech savvy parents, they may even react to your SMS, like this:
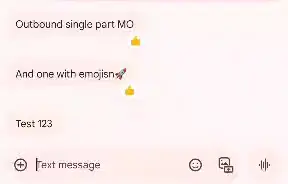
But of course this feature doesn’t exist in the SMS standard, so how does it work?
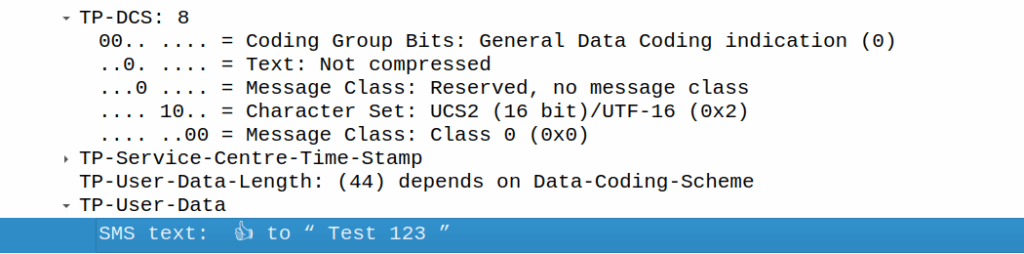
Well, when you “react” to an SMS what is sent by your phone is a copy of the message like this:
In hex that’s:
200a 200b D83D DC4D 200b 0020 0074 006f 0020 201c 200a 0054 0065 0073 0074 0020 0031 0032 0033 200a 201d 200a
So what’s going on?
Well Android cleverly has formatted this message so that it has special meaning on Android phones, but non-android phones, will just see:
👍 to ” Test 123″
Breaking it down:
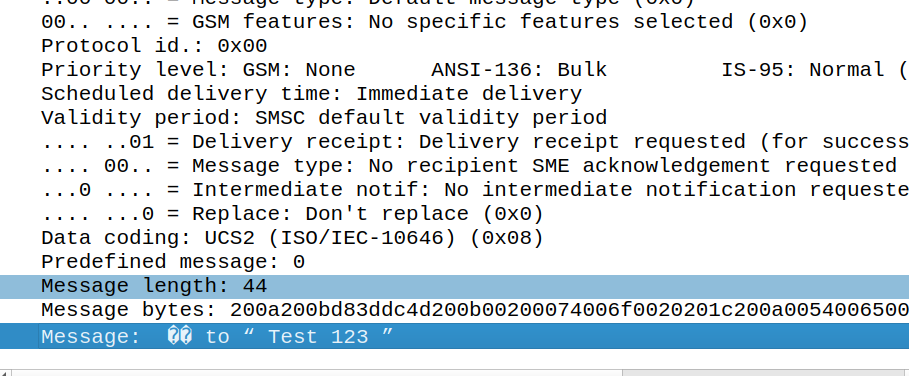
200A is Hair Space followed by 200B which is a Zero Width Space (This is metadata for Google’s messaging app) to denote it’s an emoji. This is really clever, as these characters mean it’s an emoji reaction to a previous SMS, but they don’t render as visible characters if the user is on a phone that doesn’t know how to treat it.
Our UTF-16 thumbs up is represented at D83D DC4D (Surrogate), and then the original message is quoted after it.
As a fun aside, this does not work if the original message was near the limit of a single part message, as the original message is quoted, so what happens then?
Here’s a MO message that’s exactly 160 characters:

If I react, the original message (160 chars, GSM7 data) is included, but as we’re including an emoji, it must be UCS2 (essentially UTF16) as the emoji isn’t part of the GSM7 alphabet.
In this case, this ends up being a 3 part message, the original text has almost doubled in size as it’s now in UTF16 – it was 140 bytes before (140 bytes fits 160 GSM7 characters) but is now 320 bytes (140 characters at 8 bytes each) + the 8 bytes for the hair space + whitespace + 8 more bytes for the emoji + the 6 bytes UDH header per message, brings us to a whopping 347 bytes not including overhead.
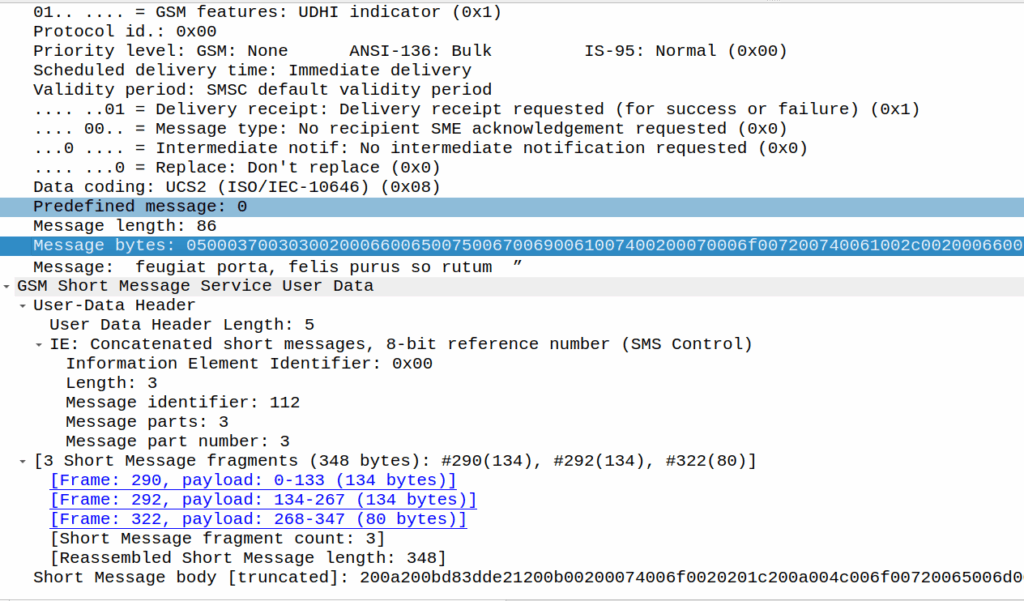
Ah, “simple” SMS…