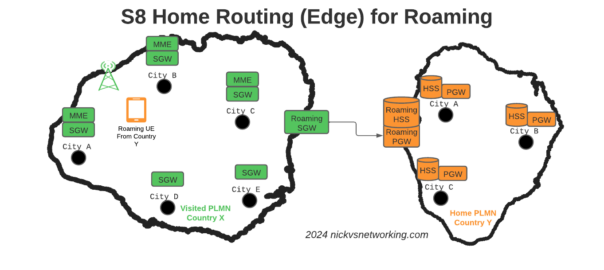
The S8 Home Routing approach for LTE Roaming works really well, as more and more operators are switching off their legacy circuit switched 2G/3G networks and shifting to LTE & VoLTE for roaming, we’re seeing more an more S8-HR deployments.
When LTE was being standardised in 2008, Local Breakout (LBO) and S8 Home Routing were both considered options for how roaming may look. Fast forward to today, and S8 Home routing is the only way roaming is done for modern deployments.
In light of this, there are some “best practices” in an “all S8 Home Routed” world, we’ve developed, that I thought I’d share.
The Basics
When roaming, the SGW in the Visited Network, sends user traffic back to the PGW in the Home Network.
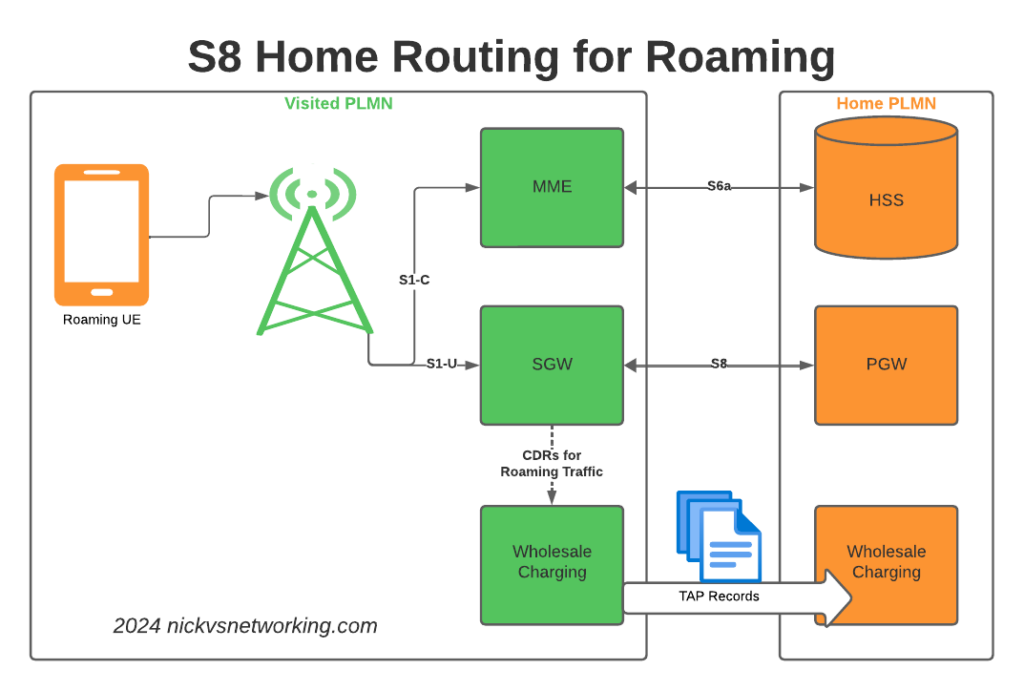
This means Online/Offline charging, IMS, PCRF, etc, is all done in the Home PLMN. As long as data packets can get from the SGW in the Visited PLMN to the PGW in the Home PLMN, and authentication flows from the Visited MME to the HSS in the Home PLMN, you’re golden.
The Constraints
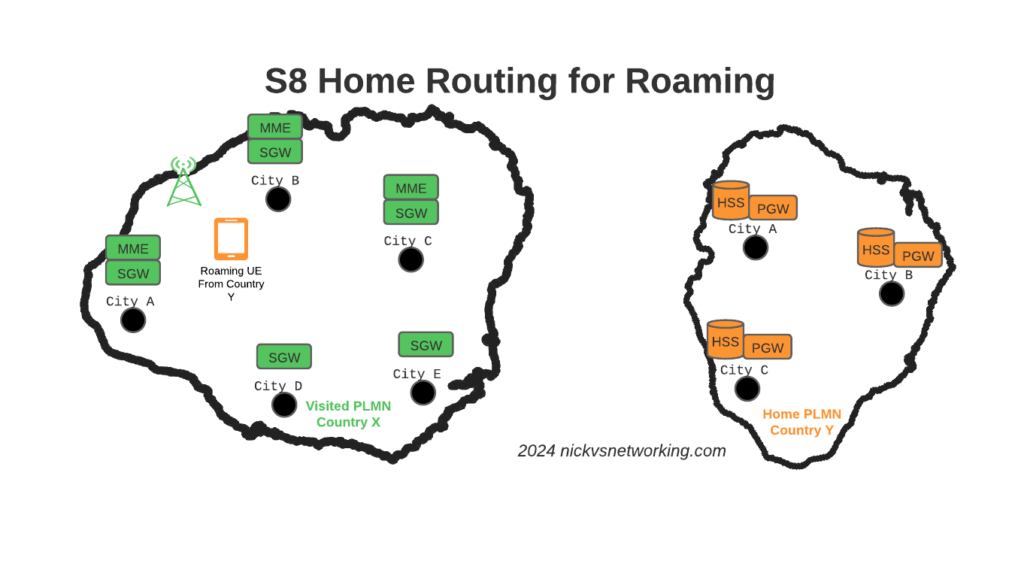
Of course real networks don’t look as simple as this, in reality a roaming scenario for a visited network has a lot more nodes, which need to be
Building Distributed Packet Core & IMS
Virtualization (VNF / CNF) has led operators away from “big iron” hardware for Packet Core & IMS nodes, towards software based solutions, which in turn offer a lot more flexibility.
Best practice for design of User Plane is to keep the the latency down, by bringing the user plane closer to the user (the idea of “Edge” UPFs in 5GC is a great example of this), and the move away from “big iron” in central locations for SGW and PGW nodes has been the trend for the past decade.
So to achieve these goals in the networks we build, we geographically distribute the core network.
This means we’ve got quite a few S-GW, P-GW, MME & HSS instances across the network.
There’s some real advantages to this approach:
From a redundancy perspective this allows us to “spread the load” and build far more resilient networks. A network with 20 smaller HSS instances spread around the country, is far more resilient than 2 massive ones, regardless of how many power feeds or redundant disks it may have.
This allows us to be more resource efficient. MNOs have always provisioned excess capacity to cater for the loss of a node. If we have 2 MMEs serving a country, then each node has to have at least 50% capacity free, so if one MME were to fail, the other MME could handle the additional load it from it’s dead friend. This is costly for resources. Having 20 MMEs means each MME has to have 5% capacity free, to handle the loss of one MME in the pool.
It also forces our infrastructure teams to manage infrastructure “as cattle” rather than pets. These boxes don’t get names or lovingly crafted, they’re automatically spun up and destroyed without thinking about it.
For security, we only use internal IP addresses for the nodes in our packet core, this provides another layer of protection for the “crown jewels” of our network, so no one messing with BGP filtering can accidentally open the flood gates to our core, as one US operator learned leaving a GGSN open to the world leading to the private information for 100 million customers being leaked.
What this all adds to, is of course, the end user experience.
For the end subscriber / customer, they get a better experience thanks to the reduced latency the connection provides, better uptime and faster call setup / SMS delivery, and less cost to deliver services.
I love this approach and could prothletise about it all day, but in a roaming context this presents some challenges.
The distributed networks we build are in a constant state of flux, new capacity is being provisioned in some areas, nodes things decommissioned in others, and our our core nodes are only reachable on internal IPs, so wouldn’t be reachable by roaming networks.
Our Distributed-Core Roaming Solution
To resolve this we’ve taken a novel approach, we’ve deployed a pair of S-GWs we call the “Roaming SGWs”, and a pair of P-GWs we call the “Roaming PGWs”, these do have public IPs, and are dedicated for use only by roaming traffic.
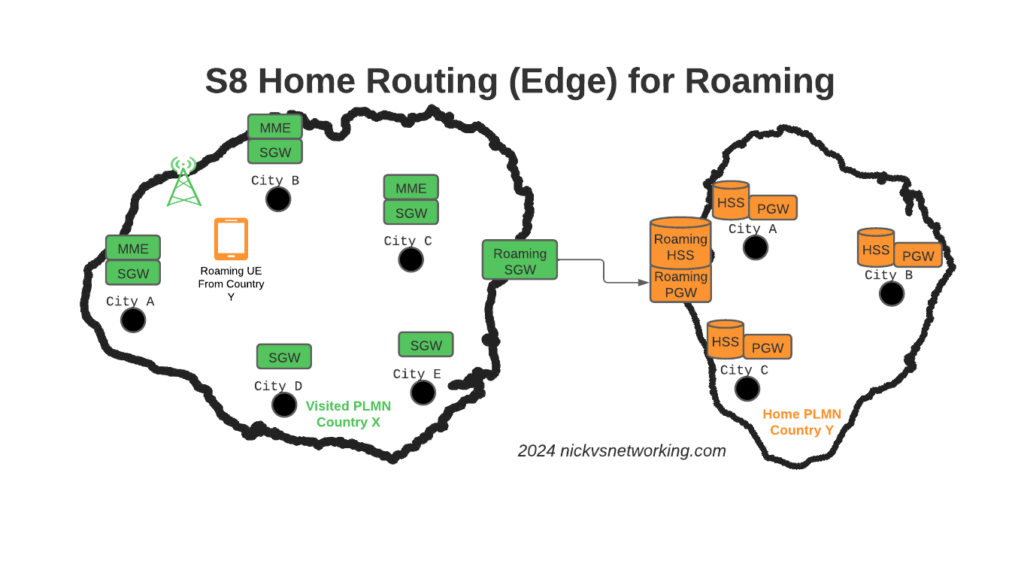
We really like this approach for a few reasons:
It allows us to be really flexible do what we want inside the network, without impacting roaming customers or operators who use our network for roaming. All the benefits I described from the distributed architectures can still be realised.
From a security standpoint, only these SGW/PGW pairs have public IPs, all the others are on internal IPs. This good for security – Our core network is the ‘crown jewels’ of the network and we only expose an edge to other providers. Even though IPX networks are supposed to be secure, one of the largest IPX providers had their systems breached for 5 years before it was detected, so being almost as distrustful of IPX traffic as Internet traffic is a good thing.
This allows us to put these PGWs / SGWs at the “edge” of our network, and keep all our MMEs, as well as our on-net PGW and SGWs, on internal IPs, safe and secure inside our network.
For charging on the SGWs, we only need to worry about collecting CDRs from one set of SGWs (to go into the TAP files we use to bill the other operators), rather than running around hoovering up SGW CDRs from large numbers of Serving Gateways, which may get blown away and replaced without warning.
Of course, there is a latency angle to this, for international roaming, the traffic has to cross the sea / international borders to get to us. By putting it at the edge we’re seeing increased MOS on our calls, as the traffic is as close to the edge of the network as can be.
Caveat: Increased S11 Latency on Core Network sites over Satellite
This is probably not relevant to most operators, but some of our core network sites are fed only by satellite, and the move to this architecture shifted something: Rather than having latency on the S8 interface from the SGW to the PGW due to the satellite hop, we’ve got latency between the MME and the SGW due to the satellite hop.
It just shifts where in the chain the latency lies, but it did lead to us having to boost some timers in the MME and out of sequence deliver detection, on what had always been an internal interface previously.
Evolution to 5G Standalone Roaming
This approach aligns to the Home Routed options for 5G-SA roaming; UPF chaining means that the roaming traffic can still be routed, as seems to be the way the industry is going.
SA roaming is in its infancy, without widely deployed SA networks, we’re not going to see common roaming using SA for a good long while, but I’ll be curious to see if this approach becomes the de facto standard going forward.
Where to from here?
We’re pretty happy with this approach in the networks we’ve been building.
So far it’s made IREG testing easier as we’ve got two fixed points the IPX needs to hit (The DRAs and the SGWs) rather than a wide range of networks.
Operators with a vast number of APNs they need to drop into different VRFs may have to do some traffic engineering here – Our operations are generally pretty flat, but I can see where this may present some challenges for established operators shifting their traffic.
I’d be keen to hear if other operators are taking this approach and if they’ve run into any issues, or any issues others can see in this, feel free to drop a comment below.
Good info